



from selenium import webdriver
b = webdriver.Firefox()
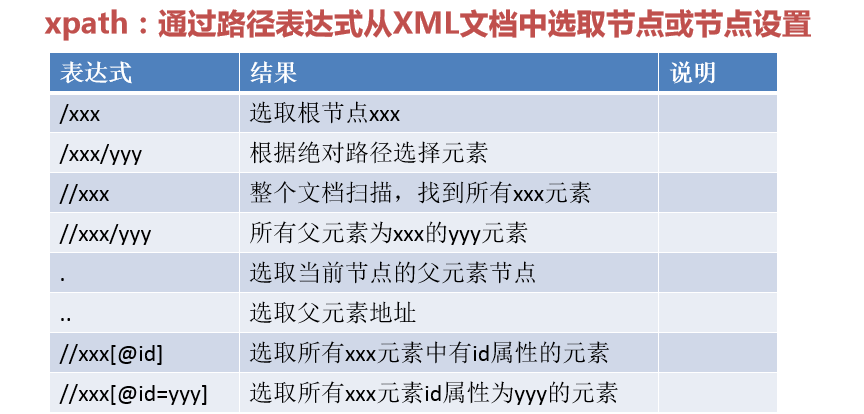
#路径读取方式一:
# b.get(r"C:我的代码selenium自动化测试 est.html")
#路径读取方式二:
# b.get("C:\我的代码\selenium自动化测试\test.html")
#路径读取方式三:
b.get('file://C:\我的代码\selenium自动化测试\test.html')
#打印选取根节点:
ele = b.find_element_by_xpath("/html")
print(ele)
#打印所有的文本:
print(ele.text)
#根据绝对路径选择元素:
ele1 = b.find_element_by_xpath("/html/body/form/input")
print(ele1)
#get_attribute查看type属性:
print(ele1.get_attribute("type"))
#同级定位输入框:
ele2 = b.find_element_by_xpath("/html/body/form/input[2]")
print(ele2.get_attribute("name"))
#遍历整个文档找到元素:
ele3 = b.find_element_by_xpath("//input")
print(ele3)
#遍历整个元素索引匹配:
ele4 = b.find_element_by_xpath("//input[2]")
print(ele4.get_attribute("name"))
#关闭页面:
# b.close()
#所有父元素为xxx的yyy元素:
ele5 = b.find_element_by_xpath("//form//input")
print(ele5.get_attribute("name"))
#获取id属性元素:
ele6 = b.find_element_by_xpath("//input[@id]")
print(ele6.id)
#找到所有的元素:
ele7 = b.find_element_by_xpath("//*")
print(ele7.tag_name)
#两个反斜杠是遍历整个文档、*是遍历整个元素、count元素统计标签个数
ele8 = b.find_element_by_xpath("//*[count(input)=2]")
print(ele8.tag_name)
#找到tag为某某的元素:
ele9 = b.find_element_by_xpath("//*[local-name()='input']")
print(ele9.tag_name)
#找到所有tag以某某开头的元素:
ele10 = b.find_element_by_xpath("//*[starts-with(local-name(),'i')]")
print(ele10.tag_name)
# 找到所有tag包含x的元素:
ele11 = b.find_element_by_xpath("//*[contains(local-name(),'i')]")
print(ele11.get_attribute("name"))
print(ele11.tag_name)
# 找到所有tag长度为3的元素:
# ele12 = b.find_element_by_xpath("//*[string-length(local-name())=5")
# print(ele12.get_attribute("name"))
# print(ele12.tag_name)
#多个路径查找:
ele13 = b.find_element_by_xpath("//title | //input")
print(ele13.tag_name)
#直接查找xpath:
ele14 = b.find_element_by_xpath("/html/body/p/input")
print(ele14.tag_name)
print(ele14.get_attribute("name"))