1、同时支持事件时间和处理时间语义。事件时间语义能够针对无序事件提供精确、一致的结果;处理时间语义能够用在具有极低延迟需求的应用中。
2、提供精确一次(exactly once)的状态一致性保障。
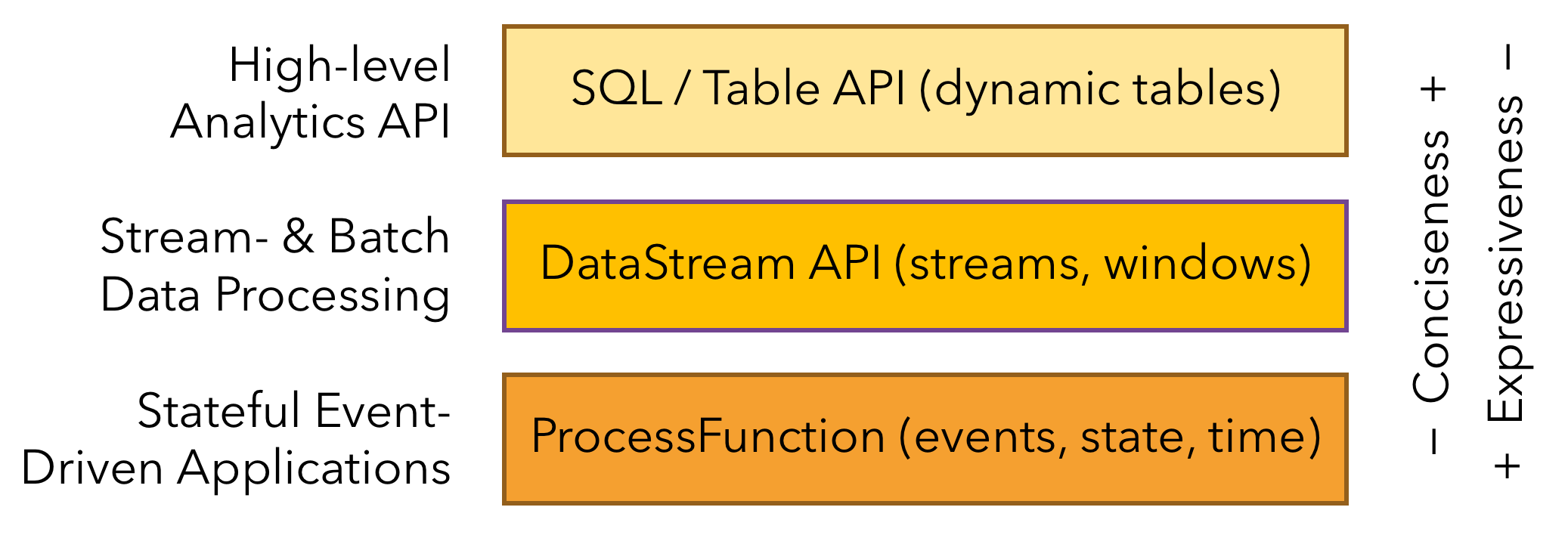
3、层次化的API在表达能力和易用性方面各有权衡。表达能力由强到弱(易用性由弱到强)依次是:ProcessFunction、DataStream API、SQL/Table API。
Flink API提供了通用的流操作原语(如窗口划分和异步操作)以及精确控制时间和状态的接口。
4、提供常见存储系统的连接器,Kafka,Elasticsearch,JDBC
5、checkpoint和savepoint
6、支持高可用性配置(无单点失效),与k8s、Yarn、Apache Mesos紧密集成,快速故障恢复,动态扩缩容作业。
7、提供详细、可自由定制的系统及应用指标(metrics)集合,用于提前定位和响应问题。
8、社区正在努力将Flink发展成为在API及运行时层面都能做到批流统一。
9、对开发者友好,Flink的嵌入式执行模式可将应用自身连同整个Flink系统在单个JVM进程内启动,方便在IDE里运行和调试Flink作业
reference:
1 《Stream Processing with Apache Flink》