转载:http://www.cnblogs.com/tornadomeet/archive/2013/03/15/2962116.html
前言:
本文主要是来练习多变量线性回归问题(其实本文也就3个变量),参考资料见网页:http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearning&doc=exercises/ex3/ex3.html.其实在上一篇博文Deep learning:二(linear regression练习)中已经简单介绍过一元线性回归问题的求解,但是那个时候用梯度下降法求解时,给出的学习率是固定的0.7.而本次实验中学习率需要自己来选择,因此我们应该从小到大(比如从0.001到10)来选择,通过观察损失值与迭代次数之间的函数曲线来决定使用哪个学习速率。当有了学习速率alpha后,则本问问题求解方法和上面的没差别。
本文要解决的问题是给出了47个训练样本,训练样本的y值为房子的价格,x属性有2个,一个是房子的大小,另一个是房子卧室的个数。需要通过这些训练数据来学习系统的函数,从而预测房子大小为1650,且卧室有3个的房子的价格。
实验基础:
dot(A,B):表示的是向量A和向量B的内积。
又线性回归的理论可以知道系统的损失函数如下所示:
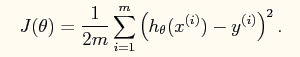
其向量表达形式如下:

当使用梯度下降法进行参数的求解时,参数的更新公式如下:
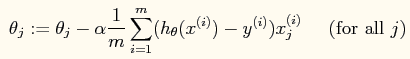
当然它也有自己的向量形式(程序中可以体现)。
实验结果:
测试学习率的结果如下:

由此可知,选用学习率为1时,可以到达很快的收敛速度,因此最终的程序中使用的学习率为1.
最终使用梯度下降法和公式法的预测结果如下:

可以看出两者的结果是一致的。
实验主要程序及代码:
%% 方法一:梯度下降法 x = load('ex3x.dat'); y = load('ex3y.dat'); x = [ones(size(x,1),1) x]; meanx = mean(x);%求均值 sigmax = std(x);%求标准偏差 x(:,2) = (x(:,2)-meanx(2))./sigmax(2); %Z-scores标准化方法 x(:,3) = (x(:,3)-meanx(3))./sigmax(3); figure itera_num = 100; %尝试的迭代次数 sample_num = size(x,1); %训练样本的次数 alpha = [0.01, 0.03, 0.1, 0.3, 1, 1.3];%因为差不多是选取每个3倍的学习率来测试,所以直接枚举出来 plotstyle = {'b', 'r', 'g', 'k', 'b--', 'r--'}; theta_grad_descent = zeros(size(x(1,:))); for alpha_i = 1:length(alpha) %尝试看哪个学习速率最好 theta = zeros(size(x,2),1); %theta的初始值赋值为0 Jtheta = zeros(itera_num, 1); for i = 1:itera_num %计算出某个学习速率alpha下迭代itera_num次数后的参数 Jtheta(i) = (1/(2*sample_num)).*(x*theta-y)'*(x*theta-y);%Jtheta是个行向量 grad = (1/sample_num).*x'*(x*theta-y); theta = theta - alpha(alpha_i).*grad; end plot(0:49, Jtheta(1:50),char(plotstyle(alpha_i)),'LineWidth', 2)%此处一定要通过char函数来转换,plotstyle()用来产生多个曲线 hold on if(1 == alpha(alpha_i)) %通过实验发现alpha为1时效果最好,则此时的迭代后的theta值为所求的值 theta_grad_descent = theta end end legend('0.01','0.03','0.1','0.3','1','1.3'); xlabel('Number of iterations') ylabel('Cost function') %下面是预测公式 price_grad_descend = theta_grad_descent'*[1 (1650-meanx(2))/sigmax(2) (3-meanx(3)/sigmax(3))]' %%方法二:normal equations x = load('ex3x.dat'); y = load('ex3y.dat'); x = [ones(size(x,1),1) x]; theta_norequ = inv((x'*x))*x'*y price_norequ = theta_norequ'*[1 1650 3]'
参考资料:
补充:
两种常用的数据归一化方法:
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两种常用的归一化方法:
一、min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
二、Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
![]()
其中![]() 为所有样本数据的均值,
为所有样本数据的均值,![]() 为所有样本数据的标准差。
为所有样本数据的标准差。