一、词嵌入
(1)NNLM(Neural Network Language Model)
paper:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
code:https://github.com/graykode/nlp-tutorial/tree/master/1-1.NNLM

Bengio等人在2001年提出的NNLM是最经典的语言模型,属于n-gram,对每个token采用低维向量表示(摈弃one-hot,因为其元素之间正交,且会维度爆炸),算法的流程如上,实现:


(2)word2vec,paper:《Distributed Representations of Words and Phrases and their Compositionality》
code:https://github.com/graykode/nlp-tutorial/tree/master/1-2.Word2Vec
paper: https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
word2vec中文意思是词嵌入,论文作者讨论了One-hot的缺点(维度爆炸&词向量之间正交),因此提出了一种Distributed representation,即将稀疏表示的词向量映射到低维空间,同时满足:
(1)这个映射是单设(即映射到的低维向量各不相同);
(2)映射之后的向量不会丢失之前的那种向量所含的信息。
上面的映射一般可以通过神经网络模型完成,同时作何发现了映射后的低维向量存在以下发现:

之所以有如上结果是因为利用到了上下文的信息,所以作者紧接着提出了两种模型:CBOW(Continuous Bag-of-Words)和skip-gram,其中前者是“根据上下文预测目标词”,后者是“根据目标词预测上下文”,结构分别如下:
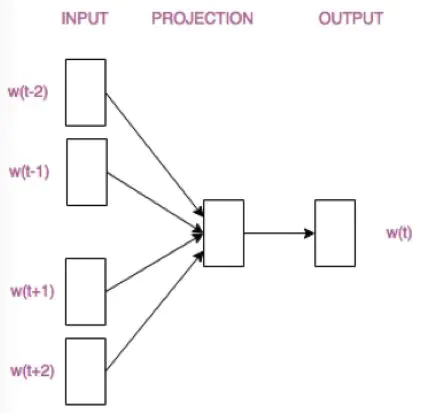
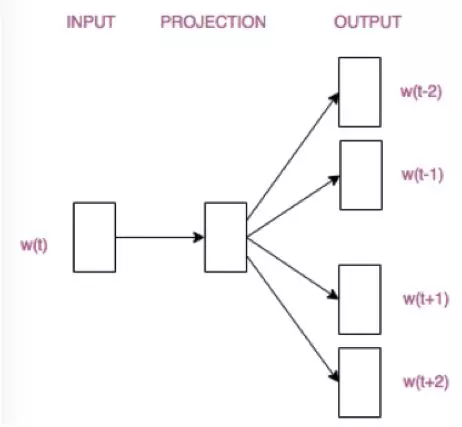
具体可参考:https://www.jianshu.com/p/471d9bfbd72f
(3)FastText,用于快速文本分类,优点如下:
1、fastText在保持高精度的情况下加快了训练速度和测试速度
2、fastText不需要预训练好的词向量,fastText会自己训练词向量(这点其实不算优点。。)
3、fastText两个重要的优化:Hierarchical Softmax(将多分类通过霍夫曼树解耦合为多个二分类任务)、N-gram(加入N-gram特征,即词序信息)
原理讲解:https://blog.csdn.net/feilong_csdn/article/details/88655927
简单实现(不加入Hierarchical Softmax和N-gram):https://blog.csdn.net/kingsonyoung/article/details/90757879
二、CNN结构
(1)用于本文分类的TextCNN网络
将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
论文链接:http://www.aclweb.org/anthology/D14-1181( Convolutional Neural Networks for Sentence Classification)
代码链接:https://github.com/graykode/nlp-tutorial/blob/master/2-1.TextCNN/TextCNN-Torch.py
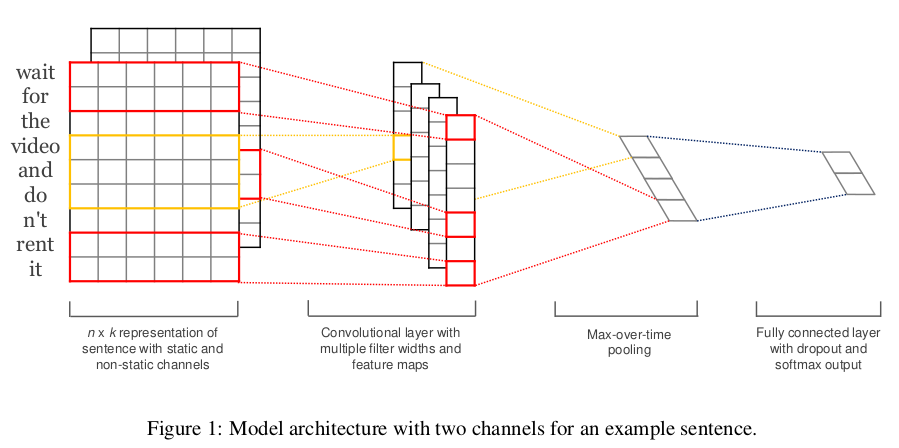
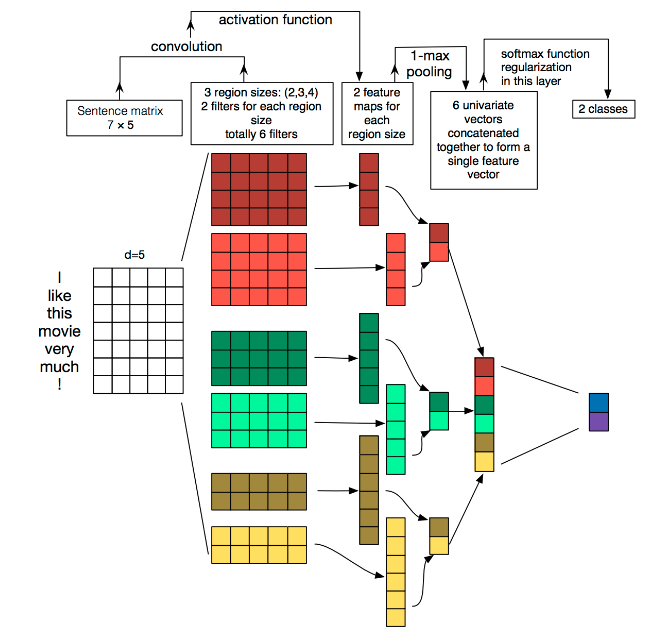
详细原理过程如下:
三、RNN类结构
(1)TextRNN,由上下文预测下一个词,属于CBOW模型;
pipeline:使用单向RNN结构,输入是一个句子的上下文,每一个word用one hot编码,它们输入进RNN中,并结合初始隐状态,输出下一步的目标词的概率。
代码链接:https://github.com/graykode/nlp-tutorial/blob/master/3-1.TextRNN/TextRNN-Torch.py
pytorch中封装好的RNN模块:nn.RNN()(https://pytorch.org/docs/stable/_modules/torch/nn/modules/rnn.html)
实现功能:
参数解释:
1)初始化参数

2)输入参数

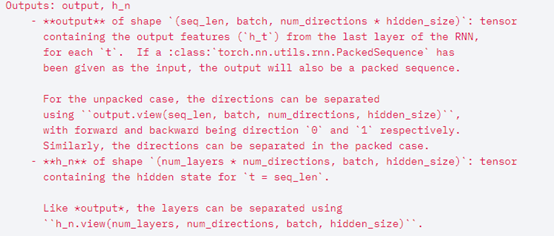
3)输出参数
(2)TextLSTM,使用LSTM实现CBOW模型;
LSTM结构图:https://www.cnblogs.com/zf-blog/p/12792543.html
主要介绍关键的nn.LSTM()模块,参数介绍如下:
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)

关于这些参数更详细的解释参见:https://zhuanlan.zhihu.com/p/39191116(写的很好)
(3)使用Bi-LSTM构建双向LSTM实现CBOW模型
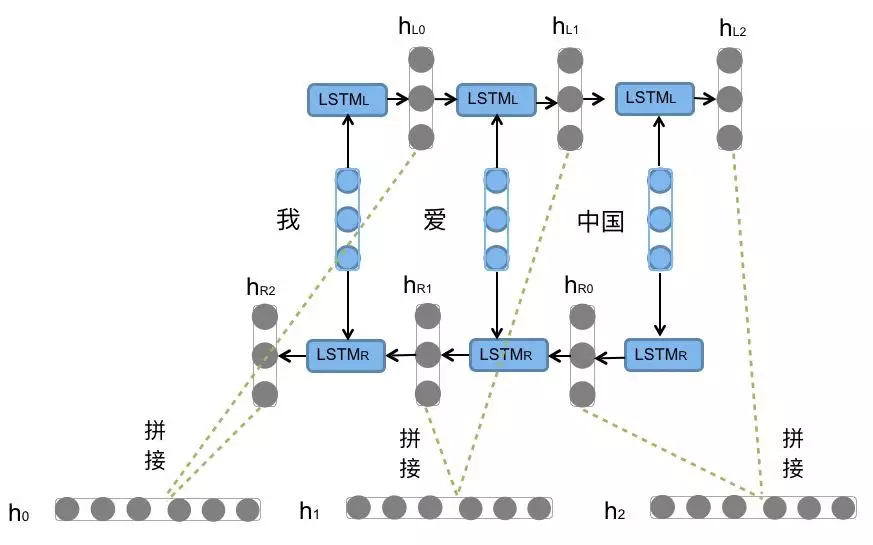
只需在nn.LSTM()初始化中设置bidirectional=True即可改造为双向LSTM;
代码链接:https://github.com/graykode/nlp-tutorial/blob/master/3-3.Bi-LSTM/Bi-LSTM-Torch.py
四、Attention机制
(1)seq2seq模型(可用于translate)
它的算法pipeline如下:

模型为encoder-decoder架构,输入的sequence经过编码后会得到编码向量c,然后该向量输入进decoder进行解码获得translate后的向量;
代码链接:https://github.com/graykode/nlp-tutorial/tree/master/4-1.Seq2Seq
(2)seq2seq with attention模型(seq2seq改进版)
这篇文章在神经网络 采用编码-解码RNN 做端到端的机器翻译的基础上,使得模型可以在预测下一个词的时候,自动地选择原句子相关的部分作为解码的输入(其实就是对每个step的编码输出做一个attention的加权求和),这也是后来被提为attention机制的内容。文章的重点就在于,在前人encode-decode的框架上,同时做到机器翻译中的对齐(调序)与(短语)翻译过程,对齐(调序)是指将源语言与目标语言短语对齐,翻译指的是短语间的翻译,文章是怎么做到这一点的呢。其实现在听来很简单,在模型中间加了一层Attention的机制。pipeline如下:
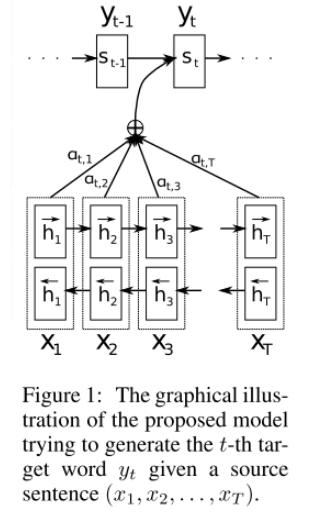
更形象的流程表示如下:

如上图所示:seq2seq with attention其实就是QA(Question&Answer)问题

代码链接:https://github.com/graykode/nlp-tutorial/tree/master/4-2.Seq2Seq(Attention)
(3)Bi-LSTM with attention
算法pipeline如下:
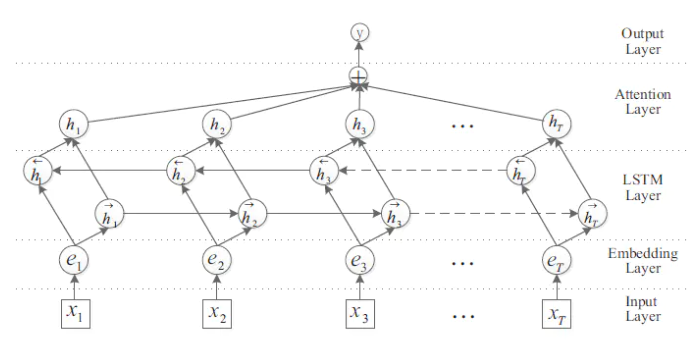
代码链接:https://github.com/graykode/nlp-tutorial/tree/master/4-3.Bi-LSTM(Attention)