新的神经网络架构随时随地都在出现,DCIGN,IiLSTM,DCGAN~
神经网络通常都有很多层,包括输入层、隐藏层、输出层。单独一层不会有连接,一般相邻的两层是全部相连的(每一层的每个神经元都与另一层的每个神经元相连)。
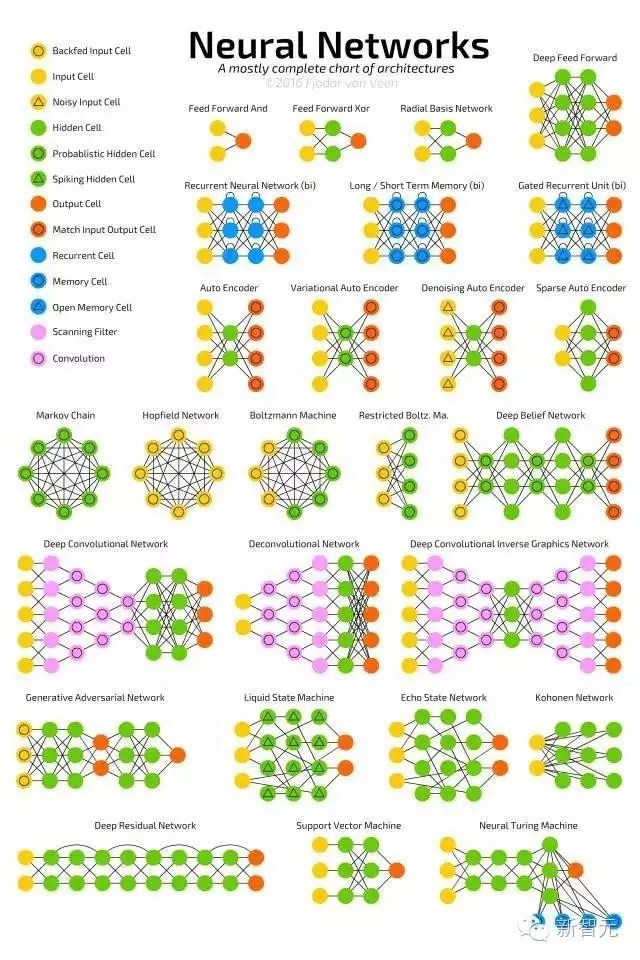
1. 前向传播网络(FF 或 FFNN)
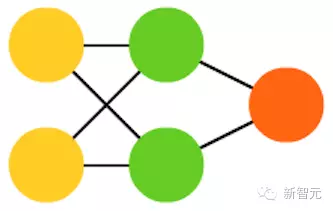
它们从前往后传输信息(分别是输入和输出)。神经网络通常都有很多层,包括输入层、隐藏层、输出层。单独一层不会有连接,一般相邻的两层是全部相连的(每一层的每个神经元都与另一层的每个神经元相连)。最简单,从某种意义上说也是最实用的网络结构,有两个输入单元,一个输出单元,可以用来为逻辑关口建模。FFNN 通常用反向传播算法训练,因为网络会将“进来的”和“我们希望出来的”两个数据集配对。这也被称为监督学习,相对的是无监督学习,在无监督学习的情况下,我们只负责输入,由网络自己负责输出。由反向传播算法得出的误差通常是在输入和输出之间差别的变化(比如 MSE 或线性差)。由于网络有足够多的隐藏层,从理论上说对输入和输出建模总是可能的。实际上,它们的使用范围非常有限,但正向传播网络与其他网络结合在一起会形成十分强大的网络。
2. 径向基函数(RBF)网络
是以径向基函数作为激活函数的 FFNN。RBF 就是这样简单。但是,这并不说它们没有用,只是用其他函数作为激活函数的 FFNN 一般没有自己单独的名字。要有自己的名字,得遇上好时机才行。
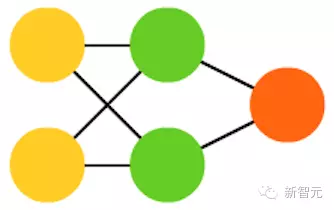
3. Hopfied 网络(HN)
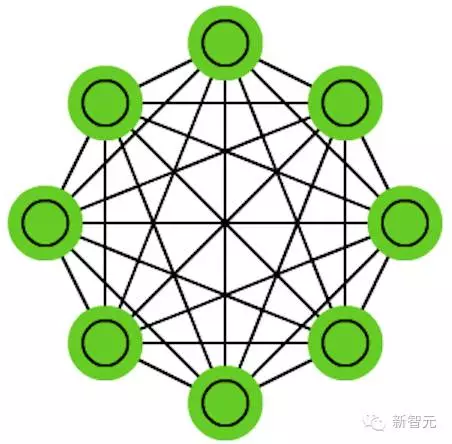
所有的神经元都与另外的神经元相连;每个节点功能都一样。在训练前,每个节点都是输入;在训练时,每个节点都隐藏;在训练后,每个节点都是输出。训练 HN 的方法是将每个神经元的值设定为理想的模式,然后计算权重。这之后权重不会发生改变。一旦接收了训练,网络总会变成之前被训练成的模式,因为整个网络只有在这些状态下才能达到稳定。需要注意的是,HN 不会总是与理想的状态保持一致。网络稳定的部分原因在于总的“能量”或“温度”在训练过程中逐渐缩小。每个神经元都有一个被激活的阈值,随温度发生变化,一旦超过输入的总合,就会导致神经元变成两个状态中的一个(通常是 -1 或 1,有时候是 0 或 1)。更新网络可以同步进行,也可以依次轮流进行,后者更为常见。当轮流更新网络时,一个公平的随机序列会被生成,每个单元会按照规定的次序进行更新。因此,当每个单元都经过更新而且不再发生变化时,你就能判断出网络是稳定的(不再收敛)。这些网络也被称为联存储器,因为它们会收敛到与输入最相似的状态;当人类看到半张桌子的时候,我们会想象出桌子的另一半,如果输入一半噪音、一半桌子,HN 将收敛成一张桌子。
4. 马尔科夫链(MC 或离散时间马尔科夫链,DTMC)
是 BM 和 HN 的前身。可以这样理解 DTMC:从我现在这个节点出发,达到相邻节点的几率有多大?它们是没有记忆的,也即你的每一个状态都完全取决于之前的状态。虽然 DTMC 不是一个真正的神经网络,他们却有与神经网络相似的性质,也构成了 BM 和 HN 的理论基础。
5. 玻尔兹曼机(BM)

和 HN 十分相似,但有些神经元被标记为输入神经元,其他的神经元继续保持“隐藏”。输入神经元在网络整体更新后会成为输入神经元。一开始权重是随机的,通过反向传播算法,或者通过最近出现的对比散度(用马尔科夫链决定两个获得信息之间的梯度)。相较于 HN,BM 的神经元有时候会呈现二元激活模式,但另一些时候则是随机的。BM 的训练和运行过程与 HN 十分相似:将输入神经元设定为固定值,然后任网络自己变化。反复在输入神经元和隐藏神经元之间来回走动,最终网络会在温度恰当时达到平衡。
6.自编码器(AE)

跟 FFNN 有些类似,它只是 FFNN 的一种不同的用法,称不上是从本质上与 FFNN 不同的另一种网络。AE 的外观看起来像沙漏,输入和输出比隐藏层大。AE 也沿中间层两边对称。最小的层总是在中间,这里也是信息压缩得最密集的地方。从开始到中间被称为编码部分,中间到最后被称为解码部分,中间(意外吧)被称为代码。你可以使用反向传播算法训练 AE。AE 两边是对称的,因此编码权重和解码权重也是相等的。