第一步
先检查服务器环境 pip python3 mysql redis 能下就下,该升级就升级
第二步
如果你的flask程序在github上 请使用git clone 地址 下载下来(如果是私人的则需要账号和密码,最近在学git 都给我搞复杂了)
总之想办法把文flask程序下载到服务器上
第三步
安装虚拟环境 virtualenv 同样使用pip install virtualenv
创建一个文件夹
mkdir py3 (名字随意)
cd 进入该文件
cd py3
使用virtualenv 创建一个虚拟环境
virtualenv -p python env(虚拟环境名字 同时指定python为3版本 ubuntu上如果不设置很可能默认为p2版本) source /你创建的文件夹/bin/activate 回车 进入虚拟环境中 (退出则是 deactivate 命令)
第四步
已经进入虚拟环境中 进入使用git clone 下载的文件夹中(我默认你还是用pip freeze 打包依赖文件了)
pip install -r reqxxxxx.txt
安装运行这个flask的包
检查flask的配置信息,比如redis数据库地址,mysql地址,(我没有在ubuntu的系统变量中设置配置,都是明文写在代码中的)
如果使用了flask_script和flask_migrate 插件
那么建立数据库(migrate只能帮助建立表,不能建库)
python flask入口文件 db init
python flask入口文件 db migrate
python flask入口文件 db upgrade
第五步
安装 并启动
pip install gunicorn
使用gunicorn 开启多线程运行
注意 如果入口文件 在开发中你是使用flask_script 来进行操作flask程序的,上传至服务器时并没有去除,请选择去除,使用工厂模式中 app = create_app() 得到一个能使用gunicorn启动的服务
manage.py
from app import create_app from flask_script import Manager from flask_migrate import MigrateCommand app = create_app() if __name__ == '__main__': app.run() #manage = Manager(app=create_app()) #manage.add_command('db',MigrateCommand) #if __name__ == '__main__': # manage.run() ~
不让很可能出现 xxx gunicorn 只能使用一个参数 不能使用 2个参数 这样的提示
启动的命令 我开启的是5001 端口 实际过程中只要不是占用其他和系统端口 随意设置 测试 gunicorn -w 4 -b 127.0.0.1:5001 manage:app
如果需要后台进行挂起 使用守护进程后台挂起 杀掉进程则使用 ps -efl |grep gunicorn 查询进程号码 kill -9 xxxx 终止进程
gunicorn -w 4 -D -b 127.0.0.1:5001 manage:app
以上命令的意思是
gunicorn 使用-w 开启4个进程 -b 则是我指定端口 127.0.0.1:5001 让他人都能在你这服务器公网ip:5001 访问到这个flaskweb程序 manage 则是启动入口文件的名字 注意不要到后缀 app则是flask的实例
有可能启动时出现 不断重试四五次进程显示失败,属于端口被占用了,杀掉占用的端口kill -9 xxx 或者换一个
除了这个还有一个进行启动的方法,通过配置文件启动
gunicorn -c 配置文件 文件名:app实例
设置配置文件 之后以这种方式启动 不过貌似有些参数和spuervisor 有关 先进行一个 注释
# gunicorn.conf # 并行工作进程数 workers = 4 # 指定每个工作者的线程数 threads = 2
# 增加 设置链接最大数
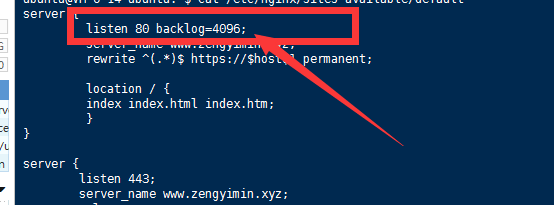
backlog = 4096
# 监听内网端口5001 bind = '127.0.0.1:5001' # 设置守护进程,将进程交给supervisor管理 daemon = 'false' # 工作模式协程 worker_class = 'gevent' # 这个注释掉 # 设置最大并发量 worker_connections = 2000 # 设置进程文件目录 pidfile = '/var/run/gunicorn.pid' # 设置访问日志和错误信息日志路径 accesslog = '/var/log/gunicorn_acess.log' errorlog = '/var/log/gunicorn_error.log' # 设置日志记录水平 loglevel = 'warning'
# 注意 gunicorn和web框架是在同一台服务器上的
第六步
接下来设置nginx 摸索一晚上还是有点弄懂了一点东西(其实啥也不懂,网上找了好多,都是不同配置,乱七八糟,如果有人看到这里,你把我的也当做参考吧... orz)
安装 nginx 版本 nginx version: nginx/1.10.3 (Ubuntu)
sudo pip install nginx
先去 /etc/nginx/sites-available/default 这个路径下 看名字就知道了 这是nginx 的默认配置
至于网上看到到一些其他都是在
这里弄的,但是我发现我弄的版本不同 这个文件夹中我显示的是这个
先进行一个备份 使用 cp default defuult.apk
使用sudo su vim default 打开该文件
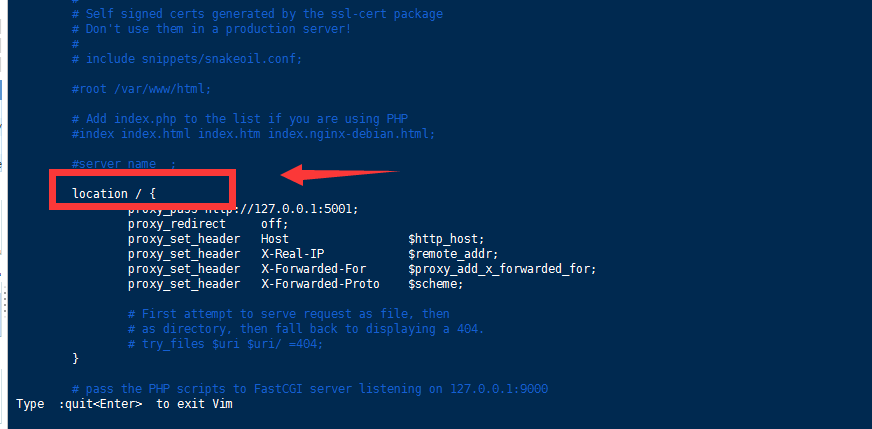
找到含有这个字段的大括号 是 / 斜杠 没有其他字段 插入以下讲解之上的代码
proxy_pass http://127.0.0.1:5001; # 我是nginx和gunicorn一台服务器上的,所以实际分开配置时需要框架服务器的真实公网ip proxy_redirect off; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; # 讲解 proxy_pass http://127.0.0.1:5001; 所有经过nginx的请求都会发往这个ip地址 貌似是因为我是一台机器上安装了nginx和gunicorn 所以ip地址是我使用gunicorn开启的配置的ip端口,如果是分开放置 可能需要将这个ip地址改为放置gunicorn的机器ip proxy_redirect off; 为服务器的ip地址做一个掩护 避免暴露出去 如果想要修改 请参考 https://blog.csdn.net/u010391029/article/details/50395680 proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; 这四个都是用来设置请求头的 比如拿到用户的真实ip
如果想要得到证实的ip 使用
ip = request.headers.get('X-Real-IP')
得到代理之后的真实ip ip = request.headers.get('X-Forwarded-For')

除了这个还会有一个ngnix的默认设置,你直接访问 这个加载nginx的服务器公网ip, 比如 131.15.42.31 由于是默认80端口, 访问时不需要添加端口 可以直接访问 131.15.42.31
nginx 会把流向它的请求 发送你设置的框架服务器ip中
新增链接最大值
第七部
退出编辑 :wq
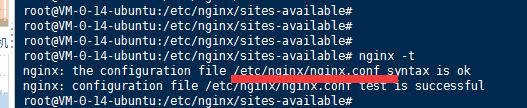
niginx -t
检查配置有没有出错
使用 service nginx restart 重启
如果开启了nginx和gunicorn 那么试试在另一台机器中打开nginx服务器的ip 加上路径地址 试试能不能访问
可以看到不需要端口号了
关于更多的nginx设置,比如分布式 布置 请看 https://www.bilibili.com/video/av45206566

PS:我来做做小优化
默认情况下 请求经过nginx 是会经过一定程度的压缩 才会发往服务器的,但是 服务器返回的数据也是也是可以被压缩的
经过测试 在 /etc/nginx/nginx.conf 文件 中不是有一排被注释的代码吗 包括在 http 大括号内 头部叫做 Gzip Settings

修改之后推出保存 service nginx restart 重启
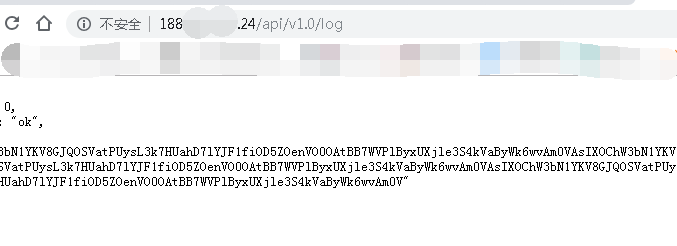
测试前请求过一次 第二次之后的则是修改配置之后发送过来的数据 压缩快 45% 了,虽然200k以上大数据可能不会这样,这只是小数据
并且返回的headers 中 只要是被压缩 都会加入 gzip 这个字段
还有对于nginx这个服务器对于压缩文件数据这种事情还是会有点压力
我这是全部注释掉了 还可以优化优化下的,有些对于服务器不好的可以注释掉 有关名词解释可以百度搜索
如果不想这种数据都进行压缩,从而解释nginx的资源 那设定小于多少的字节不会被执行压缩
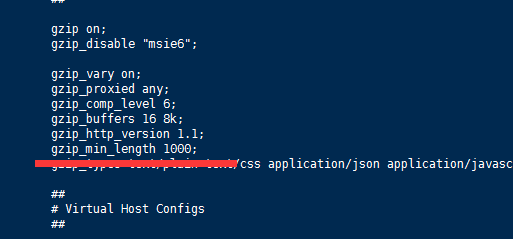
添加一个 gzip_min_length 1000; 设置最小字节为 1k 以下的不会被压缩 ,当然你也可以设置的大一点
详细页面讲解 https://www.cnblogs.com/qcloud1001/p/9341682.html
目前简单测试了一下,使用多线程500个爬虫访问这个flask程序 (腾讯云的10元1核2g内存的服务器,由于是想写api,所以也没有啥静态文件),
并简单的每次写入10个字符的log记录到mysql中,测试平均值 大概在4.35s 左右 (并不严谨)
4.389250993728638 4.4822564125061035 4.46025538444519 4.415252685546875 4.415252447128296 4.60326361656189
这是简单写入测试 ,但是又有问题来了 如果我有写入也有返回数据呢?
于是在flask识图函数中选择 str(os.urandm(500)) 生成500个字符串 用jsonify json格式返回
出现了问题,只要超过500个线程的爬虫,发送到499 就会停止不动,但是数据库中添加的数据也都有添加了 但就是在499卡住了
难道是mysql链接数量限制? 也不对啊 爬虫发送数据出去 返回都是200 也不光sql的问题啊?
这个待定解决
不过经过time包 可以确定发送500次数据 并接收数据返回500个字符的数据 需要的时间大概在12.5s左右的平均值
但是如果返回 只有20个字符 由os.urandom(20) 来生成 则平均值 4.4 左右
4.419252634048462 4.472255706787109 4.437253952026367
可能是由于os.urandom 生成字符串需要的时间比较耗费资源,返回速度比较慢,同样复制一个固定值500字符串进行一个返回 得到的结果和 为 平均值 4.5
4.7312705516815186 4.669267177581787 4.546260118484497 4.408251762390137
服务器占用cpu 如果是这种请求一直保存在 76 的cpu占比
如果进入尾声占比 33
无人访问 占比5
之后的反向代理nginx 和 监管服务 supervisor 设置 等我学会了再说 待定