本文转自微信公众号:高可用架构
作者:杨尚刚
2015 年最重磅的当属 MySQL 5.7 GA 的发布,号称 160 万只读 QPS,大有赶超 NoSQL 趋势。
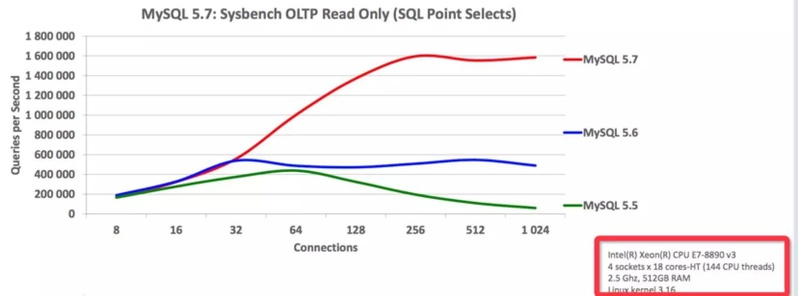
上面这个图是 Oracle 在只读场景下官方测试的结果,看上去 QPS 确实提升很大。不过官方的硬件测试环境是很高的,所以这个 160 万 QPS 对于大家测试来说,可能还比较遥远,所以实际测试的结果可能会失望。但是,至少我们看到了基于同样测试环境,MySQL 5.7 在性能上的改进,对于多核利用的改善。
提高运维效率的特性
MySQL 5.7 动态修改 Buffer Pool
从 MySQL 5.7.5 开始可以在线动态调整,对运维更友好。很多人都经历过 Buffer Pool 过大或过小调整需要重启实例,运维成本非常高,尤其是主库或其他核心业务。
MySQL redo log 大小
5.5 <= 4G, 5.6 +<= 512G
当然这个也不是越大越好,但是提供了可以 尝试的机会,越大的 redo log 理论会有更稳定的性能。当然带来的风险就是故障恢复时间会更长。
下图就是不同 redo 大小的性能对比,主要是看性能抖动情况
innodb_file_per_table
默认值 Off <= 5.6.5 <=On,独立表空间优点很明显。尤其可以使用 InnoDB Transportable tablespaces,可以像 MyISAM 一样快速迁移表。
query cache
1 <= 5.6.8 <= 0,默认关闭。整体来说关闭 query cache 是利远大于弊,官方最终也选择了关闭。
SQL_Mode 变为Strict mode
SQL要求更严格,version < 5.6.6 sql_mode 为空,最为宽松,不够严谨。
5.6.6 < version < 5.7.4
- NO_ENGINE_SUBSTITUTION
version > 5.7.9
- ONLY_FULL_GROUP_BY
- STRICT_TRANS_TABLES
- NO_ZERO_IN_DATE
- NO_ZERO_DATE
- ERROR_FOR_DIVISION_BY_ZERO
- NO_AUTO_CREATE_USER NO_ENGINE_SUBSTITUTION
以 NO_ZERO_DATE 为例,如果你原表里有 0000-00-00 这种数据,在 MySQL 5.7 使用默认 SQL_Mode 时候改表时候就会报错了。
binlog_rows_query_log_events
默认关闭 ,可选打开,建议打开,还是比较有用的。可以看到row格式下的sql语句,方便排查问题和恢复数据。
以 NO_ZERO_DATE 为例,如果你原表里有 0000-00-00 这种数据,在 MySQL 5.7 使用默认 SQL_Mode 时候改表时候就会报错了。
binlog_rows_query_log_events
默认关闭 ,可选打开,建议打开,还是比较有用的。可以看到row格式下的sql语句,方便排查问题和恢复数据。
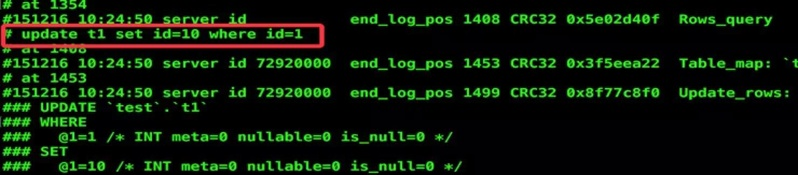
上图就是开启之后 binlog 解析出来的内容,可以看到正常 SQL。
max_execution_time
5.7.4 刚引入名字是 max_statement_time,后来改成 max_execution_time
单位是毫秒,SQL 语句的超时中断,自我保护的一种方案。
只针对 select,也可以在 sql 里指定。如果 percona 版本 的话,这个参数更暴力,对所有请求生效慎用。
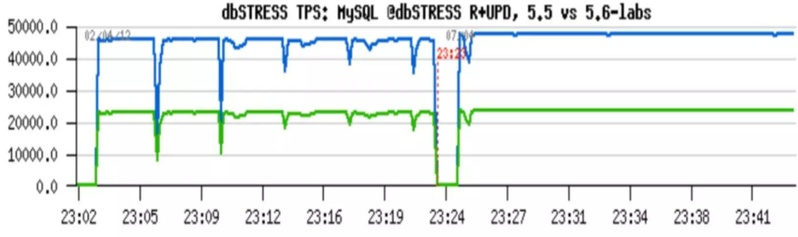
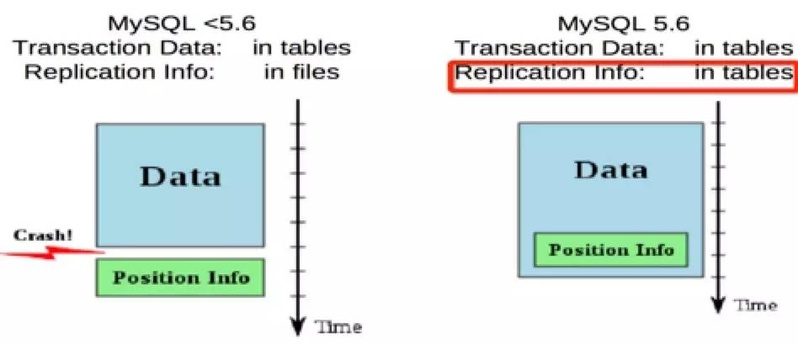
replication info in tables
crash-safe slave 方案,最早 Google 做的方案是存储在事务日志里。单独存储更灵活,可以解决很多从库宕机后 duplicate key 问题。
innodb_numa_interleave
建议关掉 numa。最早 Twitter 开源分支里有提供,也可以启动实例时候设置 numactl –interleave all,不过实际线上使用系统默认 numa 策略,并没有遇到过因为 numa 导致的 swap 问题。
动态修改 replication filter
方便做拆分或做级连复制时候使用,可以通过 change 动态修改。如果用过 replication filter 应该清楚 这个还是比较有用的。
优化器 Server 层改进
优化器主要还是基于 cost model 层面和给用户更多自主优化
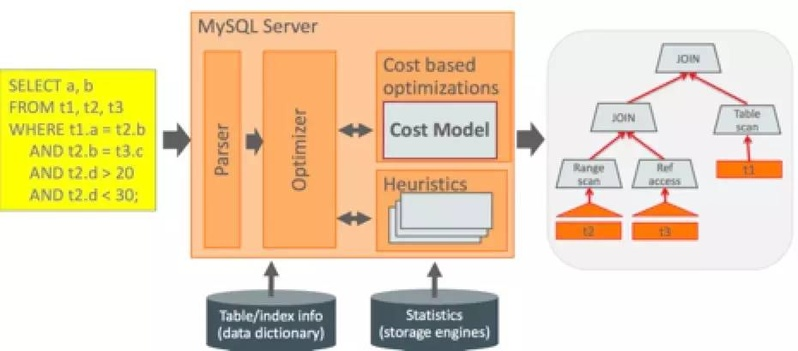
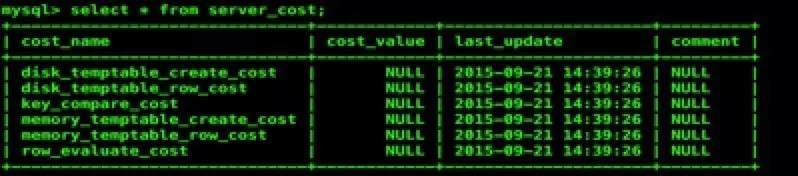
可配置 cost based optimizer,mysql.server_cost 和 mysql.engine_cost。
New JSON 数据类型和函数支持。当然 JSON 也可以存在 Text 或 VARCHAR 里用内置 json,更容易访问,方便修改。

支持生成列(虚拟列),以及虚拟列上索引。
CREATE TABLE order_lines (orderno integer,
lineno integer,
price decimal(10,2),
qty integer,
sum_price decimal(10,2) GENERATED ALWAYS AS (qty * price) STORED );
简化查询,有 virtual 和 stored 两种情况,感觉这个功能还是比较小众。
下图是二者对比

5.7 还对 explain 做了增强,对于当前正在运行查询 explain。
EXPLAIN [FORMAT=(JSON|TRADITIONAL)] FOR CONNECTION <id>;
InnoDB 层优化
InnoDB 层核心还是拆分各种锁,提高并发。只读事务优化就是其中一个例子
不再使用只读事务 list,重构 MVCC 代码,不为只读事务分配事务 id,降低内存开销。
如何使用只读事务:
start transaction read only
开启 autocommit 下的不加锁的 select 语句
原生支持分区 Native Partitioning,之前版本分区表是放在 server 层管理的,现在是在引擎层面支持,更节省内存,分区越多,效果越明显。
atomic write, disable double write,MySQL 5.7 开始支持 atomic write,成本高,性价比不算高,需要底层存储硬件支持,感觉比较鸡肋。
支持 spatial index 空间索引
基于 R tree 实现
目前只支持 2D 数据类型
支持 GeoHash 和 GeoJson ,提高数据查找效率
Transparent page compression
需要文件系统支持 PUNCH HOLE,ext4 和 xfs 都可以支持,测试效果比目前压缩效果好一些。适配更多压缩算法,支持 lz4 zlib,功能上还不够稳定和成熟。
performance_schema 改进,增加了很多统计信息表,metadata_locks,status_by_host ,status_by_user,status_by_thread,获取当前执行的慢查询 top10,可以获取到更多状态信息。
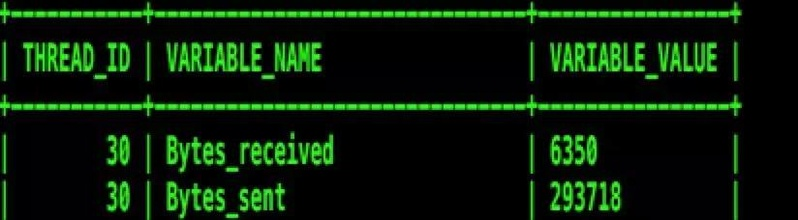
上图是对单个 thread_id 吞吐量统计信息
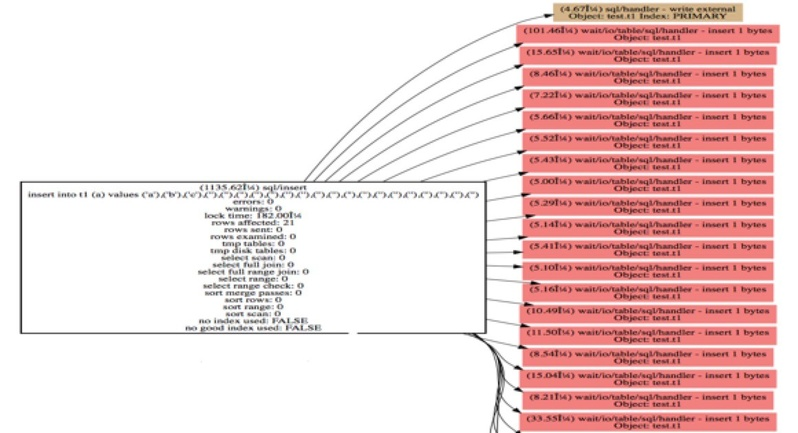
新增加的 sys 数据库,相当于对 performance_schema 的数据整合。IO 信息和索引信息,相当于 Oracle 里的 V$ Catalog,基于 ps_helper 实现。基于 performace schema 画的 SQL 执行时间分布图。
replication改进
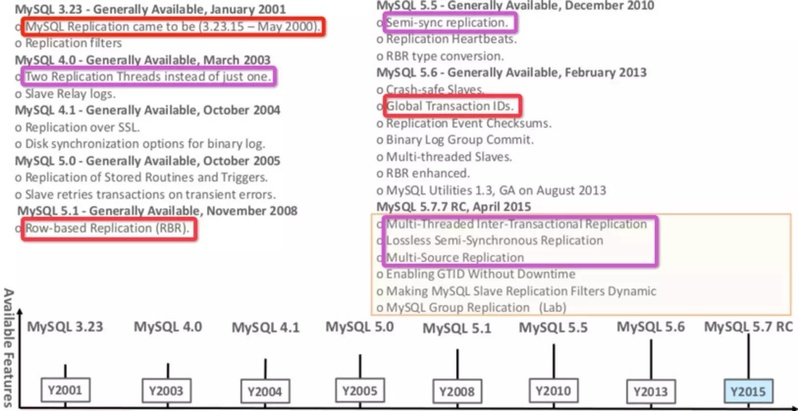
上图是 MySQLreplication 的发展历史
最大的亮点 GTID 增强,支持在线调整 GTID。当然也不是简单的 SET @@GLOBAL.GTID_MODE = ON,步骤也是很复杂,不过至少不用停机,也是进步
从库可以不开启 log_slave_updates,通过引入 gtid_executed 表实现,对性能优一定帮助,大大简化切换流程。增强半同步复制,确保从库先收到,设置半同步从库个数。使用 mysqlbinlog 作为伪 slave 是个不错方案。
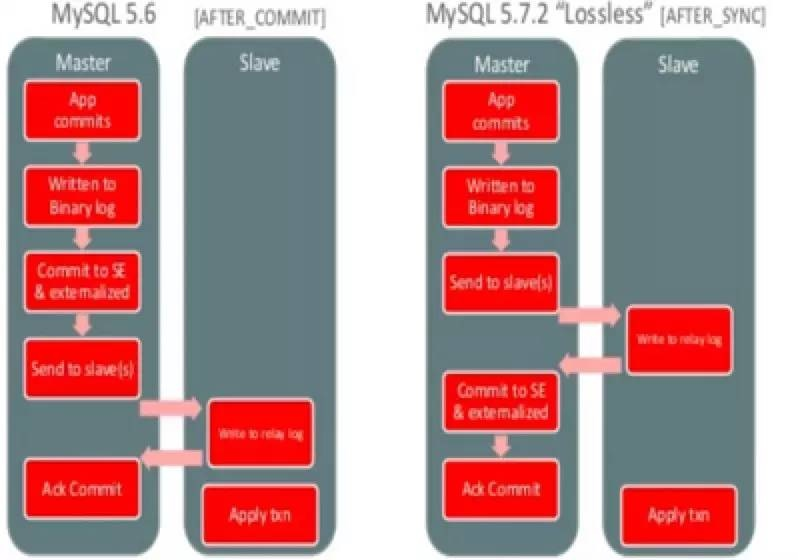
上图就是 loss-less 半同步和之前的区别
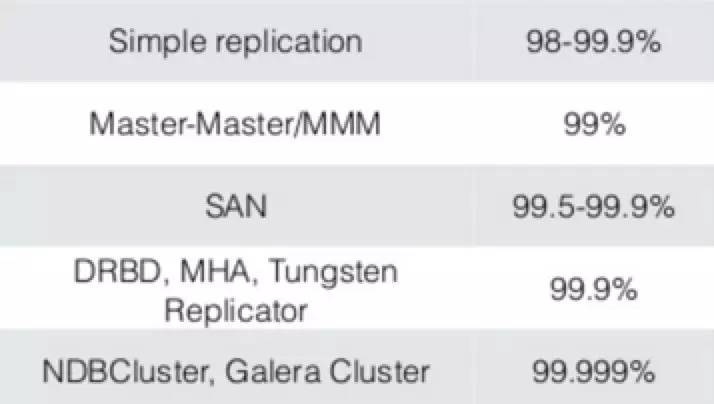
并行复制优化 ,Database 5.6 默认并行复制。logical-clock 5.7 引入,一个组提交内事务都可以并行,可以达到接近主库并发效果。
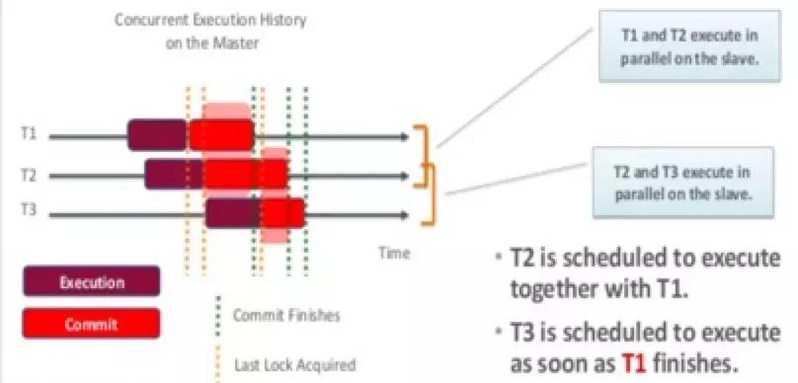
不同复制方案的可用性级别
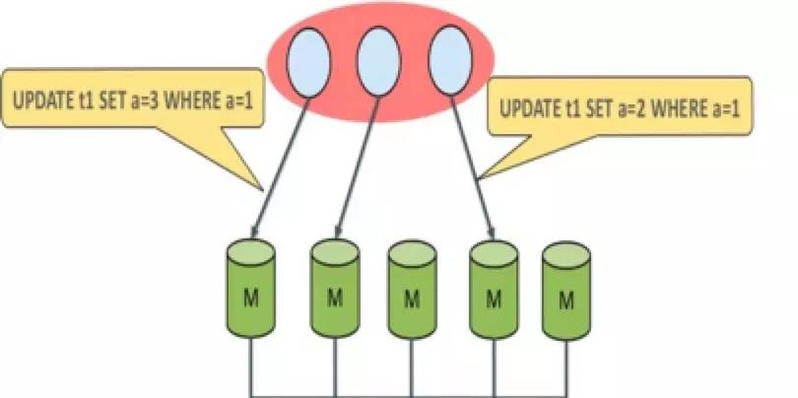
5.7 引入的 group replication 也是为了提高可用性。多主复制,多点写入,内部检测冲突,保证一致性,自动探测。支持 GTID,共享 UUID,只支持 InnoDB,不支持并发 DDL。
安全方面密码自动过期,这个要注意,建议关闭。default_password_lifetime 控制过期默认一年。锁定用户,支持 SSL 访问,server 端利用 OpenSSL 加密。
工具支持 mysqlpump,并行版 mysqldump,也是替换原生 mysqldump 和 mydumper 的。--watch-progress 查看 dump 进度,--compress-ouptut 压缩。mysqldump 可以做为一个伪 slave 接受 binlog,做 binlog 备份的匪巢的方案,也支持 SSL。
从整体来说,MySQL 5.7 做的改进还是非常有吸引力的,不论是从运维角度还是性能优化上,当然真正在生产环境上遇到问题时在所难免的,要做好踩坑的准备。
未来发展
RDS服务
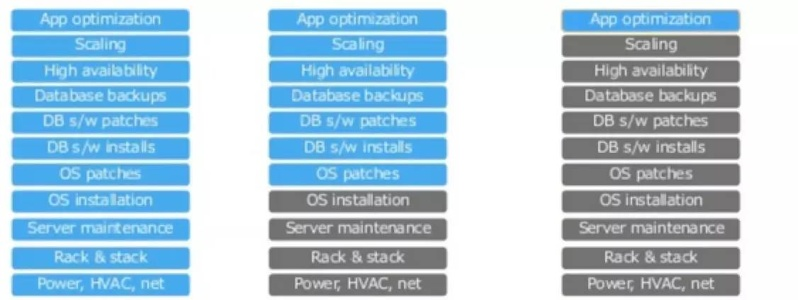
应该大家很多人都用过 RDS 服务,确实降低了使用成本。下图是各种架构区别,普通物理服务器,EC2,RDS,优势很明显。
阿里云 RDS MySQL,支持读写分离,多 zone,支持异地容灾,压缩(支持 TokuDB),阿里云宣称的一大亮点,代码控制能力强。
老牌 RDS 服务 Amazon RDS,目前有 MySQL Aurora 和 MariaDB 这三种。Aurora 虽然目前来说,会有一些问题,但是方向还是不错的。
HA 架构,从可用性来说 Galera > Aurora > MHA
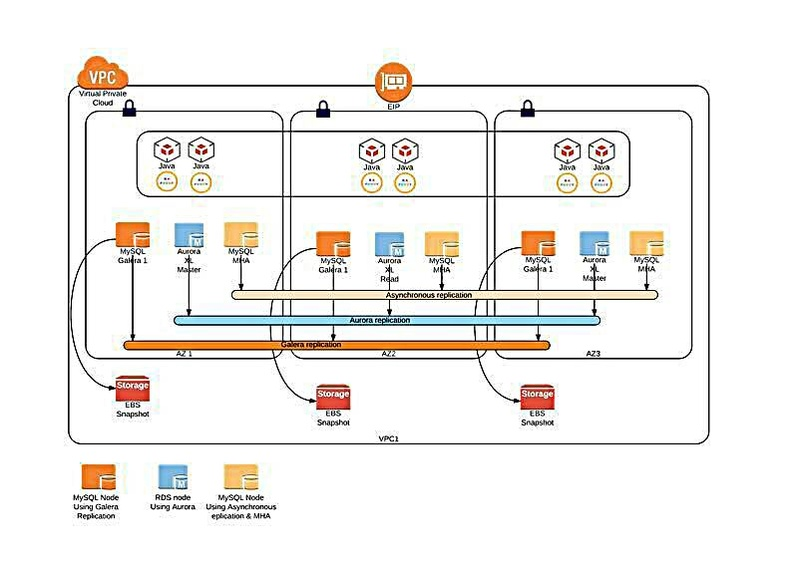
关于 RDS 服务的一些建议,数据库经验积累还是很重要的,面临过或解决的问题越多,提供的服务也相对越稳定。RDS 提供便利的同时,也存在数据安全的风险和 RDS 服务本身的 SLA 保证,是用户更关心的。
如何降低云服务商故障对业务影响,其实从 RDS 提供的性能指标考量,如果使用同等性能配置的物理服务器,RDS 成本还是偏高一些的。从功能上来说大部分 RDS 还算完备,具体哪些坑实际用的不多不好评判。
存储层的优化
LSM Tree : LevelDB, RocksDB,适配高性能存储 SSD,更高的压缩比,,更低的写入放大比例,缺点读性能差,适合写多读少场景。
MyRocks: MySQL + RocksDB
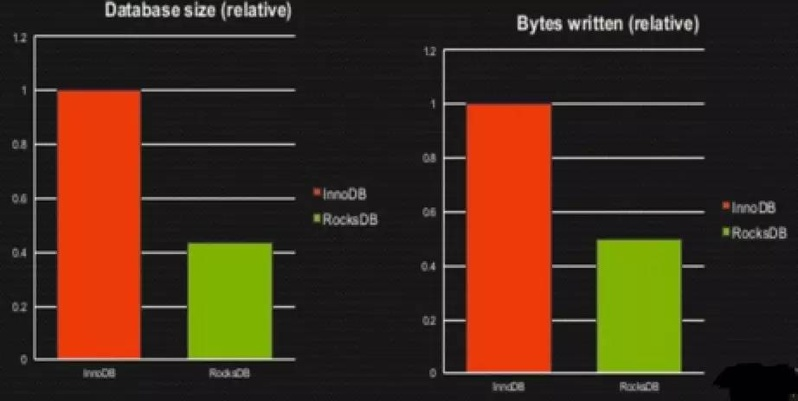
统层优化
系统优化主要还是 IO 方面的,blk-mq、scsi-mq、IO 中断多队列、3D Xpoint 接近内存的访问速度和非易失存储,说不定以后整个数据库实例都可以放在这种介质上面,也是一场新的变革。
运维经验总结
数据恢复
备份 xtrabackup 物理为主,mydumper/mysqlpump 为辅,binlog 备份也是很重要的。恢复导出 SQL 文件正常恢复。
myloader
xtrabackup
InnoDB transportable space
online ddl
5.6 和 5.7 虽然一直在改善,但是在主从同步问题上依然有问题,下图是目前主流的 online DDL 方案。
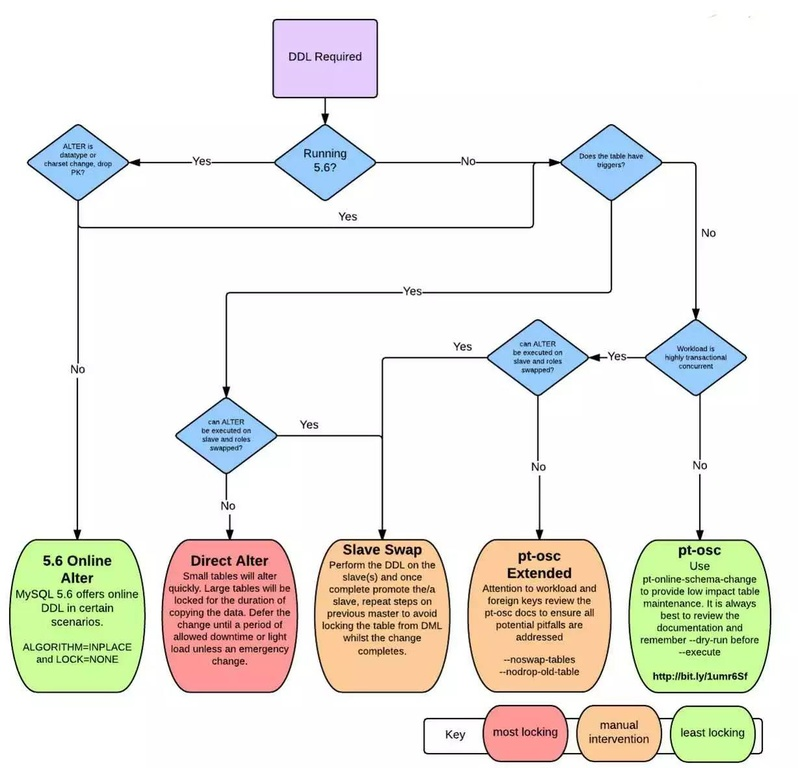
总体使用 pt-osc 更通用一些,pt-osc 注意的一些坑,添加唯一键,导致数据丢失延时备份。行格式下,只在从库使用 OSC,丢数据。
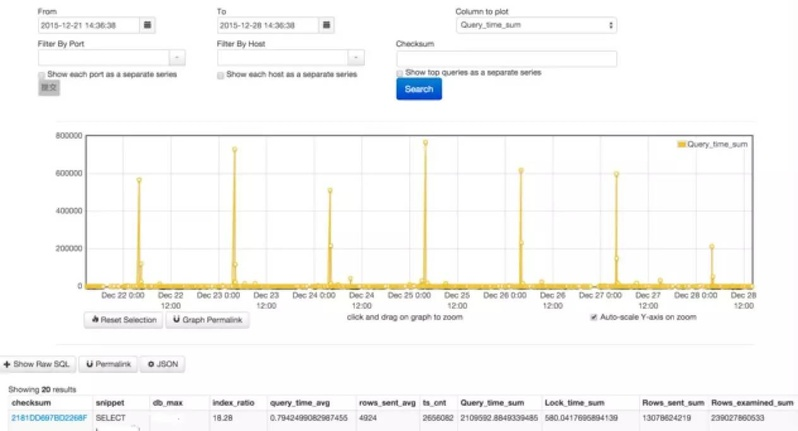
MySQL 慢日志系统
基于 pt-query-digest logstash 和 Anemometer 实现,可以定期跟踪线上业务慢查询优化。
系统状态收集
基于某些特定条件触发,比如 MySQL 连接数增长到一定阈值,收集当前系统状态,方便后续问题排查。比如系统 top mpstat strace tcpdump 等,MySQL 的 processlist show engine innodb status 等。
Q & A
1、请问 query cache 关闭的原因,MySQL 是否支持全同步?
query cache 访问需要获取一个全局锁,高并发时候争用很严重。更主要的是 query cache 缓存的效果并不好。原生 MySQL 的话,5.7 里的 group replication 是支持全同步的,还有目前的基于 galera 实现的 percona xtradb cluster 也是支持全同步的。
2、有没有 MySQL 的读写分离中间件?最好没有语言限制的,谢谢!
目前开源的中间件很多了,比如 mycat、atlas、vitess等,你指的语言限制是指的对开发语言的兼容吧,我觉得每种都兼容的很好的 不多,毕竟现在的中间件都是基于开发者本公司的现状开发的,在兼容性上不太能做到很完美。现在官方做了个MySQL Fabric,现在应该也 GA 了,后面可以关注一下。
3、你们备份的策略(比如完整多久一次,增量多久一次,备份恢复测试多久一次), 备份对线上系统的影响如何控制都是选一个slave备份的么?
我们目前的策略是以周备+日备,结合 binlog 备份,理论可以恢复到一周内任意时间点。全部是全量备份,没有做增量。备份恢复测试,我们目前还没有做,基于xtrabackup备份数据可靠性还是很高的 ,之前在新浪是有实现备份测试的,大概2-3天能对线上备份端口做一轮测试。目前备份是选择一个线上从库来做的,控制影响的话主要是通过对备份工具 xtrabackup 的并行度和 IO 来进行限制。
4、请问关于 DB 管理的问题,线上数据库是否可开放给业务方技术人员查询?开放到什么程度?有没有必要做 WEB 查询平台?
开发人员还是有必要开放的,如果完全禁止,很多业务数据查询的事情可能就需要 DBA 介入,其实效率是比较低的。当然在权限上可以限制,比如只开放读权限,禁止 dump 这种。对核心库限制要更严格一些。如果能做 Web 平台 当然更好,可以在入口层做限制,后端控制数据访问频度和策略等。
5、当插入一条数据,非唯一索引是通过 change buffer 更新提高并发,那么唯一索引或者主键如何更新呢?保证高并发?
唯一索引或主键需要看更新或插入的数据在不在 Buffer Pool,没有的话就需要去磁盘读取数据做检测,需要维持约束。
6、" 聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的 ",有个疑问,某条数据的更新,是新生成一条,老本的打上版本号,然后定期删除。这样有个问题,新数据应该在新的物理地址。聚簇索引是不是失效了?
聚簇索引在实际磁盘存储也不是严格顺序的,并且老的版本是存储在 undo里,也就是 ibdata 共享表空间里 ,和实际数据不冲突。
7、MySQL 5.7 有没有对复合索引做优化,在违背 left most prefixing 时也能使用复合索引?
最左前缀的原则比较难突破,当然在 5.6 引入了 index condition pushdown 机制,可以在存储引擎层面做一些过滤,减少过滤行数,会有一定优化。