caffe使用
caffe是一个卓越的CNN框架
caffe源码是Cpp语言的,基于一些外部的库,包括BLAS(矩阵计算),CUDA(GPU驱动),gflags,glog,boost,protobuf,hdf5,leveldb,lmdb等。
只要各个以来都安装完毕,编译的时候修改下caffe自带的Makefile.config(路径和编译选项的修改),即可编译整个工程。
caffe代码文件夹主要包括:
build 所有编译好的文件存放位置
data 数据文件夹
docs 教程和说明文件夹(建议好好阅读,部分内容讲的非常详细)
include 包含文件夹,头文件
examples 各种demo的文件夹,相关应用可以参考或者直接使用对应的demo和配置
mnist 手写汉字识别 cifar10 场景识别 imagenet 图片分类 cpp_classification 分类的cpp接口文件 feature_extraction提特征的demo文件夹
matlab matlab对应的接口
python python对应的接口
models model文件的路径,一些训练好的model可以参考caffe官网model zoo:http://caffe.berkeleyvision.org/model_zoo.html
tools 一些工具
src 所有源代码存放位置
docs/tutorial 中的文件非常值得阅读,关于caffe 的架构和基本使用讲的很透彻,入门必读
caffe的使用包括 训练 和 识别 两个部分
总参考:
http://blog.csdn.net/hjimce/article/details/48933813 (强烈推荐)
http://blog.csdn.net/u014696921/article/details/52551364
http://blog.csdn.net/pirage/article/details/17553549
一、caffe训练流程:
1、准备训练数据
包括训练集,验证集两个文件夹的图片,和两个txt文件,txt文件中每行是图片名和图片标签
2、图片格式转化
caffe接收imdb,leveldb,hdf5等格式,推荐imdb,用caffe官方提供的convert_imageset脚本可以将图片转化为imdb,见这篇http://blog.csdn.net/hjimce/article/details/48933813
3、定义模型网络结构文件
例如deploy.prototxt、train_val.prototxt等,在caffe安装目录下的models文件夹下,官方提供了一些有名的CNN,如googlenet,alexnet等
参考:http://blog.csdn.net/u014202086/article/details/75226445
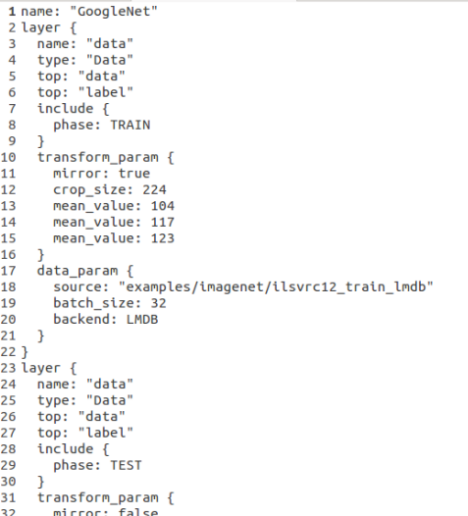
模型网络结构文件形如下图,第一行是模型网络的名字,接下来由一个一个layer组成,layer有输入层(data),卷积层,激励层,池化层,全连接层,输出层等组成。
网络结构文件中指定了训练数据(训练集+验证集)的路径,在输入层中指定。
py的caffe包提供了一些函数快速生成网络结构文件(见pdf)
4、定义solver.prototxt文件
在caffe安装目录下的models文件夹下,官方提供了一些有名的CNN,如googlenet,alexnet等
参考:http://blog.csdn.net/Yan_Joy/article/details/53079185
solver文件中主要是定义了模型训练过程中的一些参数,调参也就在这里进行
py的caffe包同样提供了生成solver文件的方法,见这篇http://wentaoma.com/2016/08/10/caffe-python-common-api-reference/
5、训练模型
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
6、一些杂项
经过上面的5步,你就成功输出了网络结构文件、solver文件、训练得到的模型文件三个主要文件,但是要让模型效果更好,你还需要生成原始数据的均值文件、标签含义文件、bet.pickle文件,来为后面的模型使用者提供参考。
生成均值文件:
http://blog.csdn.net/victoriaw/article/details/53863565
http://blog.csdn.net/gavin__zhou/article/details/50365986
二、caffe识别流程
caffe识别关键就在构造分类器,caffe提供的分类器有两种caffe.Net和caffe.Classifier,现在一般用caffe.Classifier多一点,因为用Net的话还要多些一些数据处理的代码,而Classifier将这些代码封装到了其内部
使用caffe.Net的识别:
https://www.cnblogs.com/denny402/p/5685909.html
http://blog.csdn.net/summermaoz/article/details/64442707
使用caffe.Classifier的识别:
caffe web demo
http://blog.csdn.net/liyaohhh/article/details/50936862
使用caffe.Net批量识别图片
http://blog.csdn.net/fengzhongluoleidehua/article/details/79014671
https://www.cnblogs.com/yyxf1413/p/6339655.html