1 了解赛题
- 赛题概况
- 数据概况
- 预测指标
- 分析赛题
1.1 赛题概况
本次比赛任务是利用历史数据并结合地图信息,预测五和张衡交叉路口未来一周周一(2019年2月11日)和周四(2019年2月14日)两天的5:00-21:00通过wuhe_zhangheng路口4个方向的车流量总和。
要求模型输出格式如下:
{"data":{"resp_data":{"wuhe_zhangheng":[1,4,5,6,4...]}}}
从5:00开始每5min的预测数据,第一个数据为5:00-5:05的流量值,最后一个数据为20:55-21:00。两天的数据按时间先后放在一起,总共有384个数据。
小提示:如果不考虑天气、周边活动、节假日等因素,预测结果可能不准确哦。
1.2 数据概况
首先官方给出的数据说明如下:

将数据集下载下来以后,可以观察到数据集文件分布如下:
以上每个文件夹对应一个日期下的数据,打开其中一个文件夹,可以看到如下文件:
由文件名不难看出,每个csv文件为当日对应路口方向上的车流量信息,记事本查看结果如下:
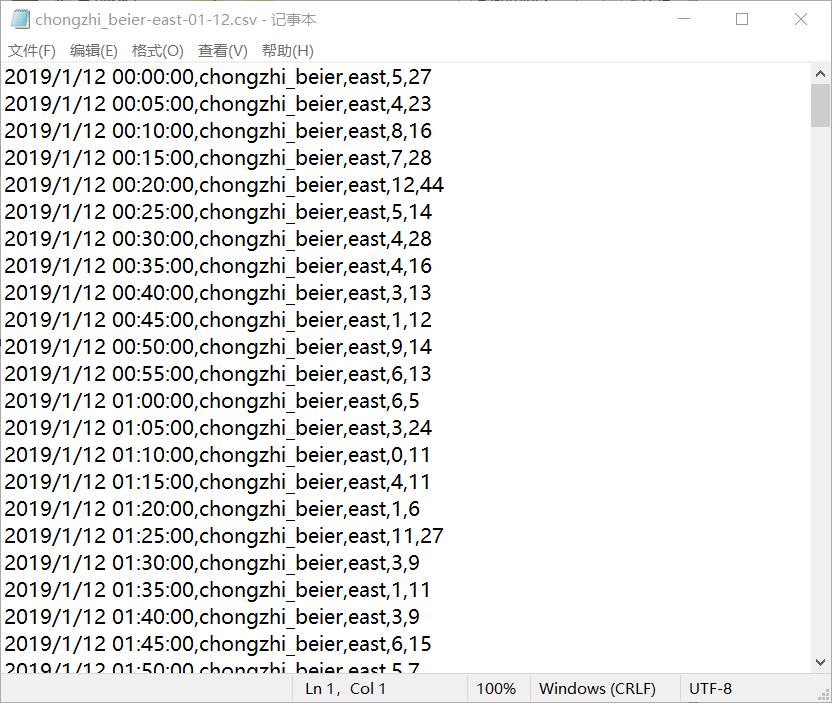
对应官方的说明不难看出,第一列数据对应time,第二列为cross,第三列为direction,第四列为leftFlow,第五列为straightFlow
· time - 时间
· cross - 路口名
· direction - 车流起始方向
· leftFlow - 左转车流
· straightFlow - 直行车流
1.3 预测指标
第一部分(分类问题)
分类问题评价标准:预测的评价还是通过每一个5min预测车流和真实通过车流对比,看看趋势是否一致(比如10月19日的5:00到5:05的真实车流是4,10月20日的5:00到5:05的真实车流为5,那么只要车流预测值大于4,就得100分,最后得分为所有得分求加权平均(权重为该时间段所在小时的车流量占16小时总车流的比重))。
第二部分(回归问题)
回归问题评价标准:预测的评价还是通过每一个5min 预测车流和真实通过车流通过grade公式计算最后得分,加权细则与第一部分相同:
其中wi为权重,xj为真实车流数据,xj拔为预测车流数据,ε为e-9。
最后将两部分分数做归一化处理,第一部分占比40%,第二部分占比60%。
1.4 分析赛题
1)此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。
2)此题是一个典型的回归问题。
3)主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常用库或者框架来进行数据挖掘任务。
4)通过EDA来挖掘数据的联系和自我熟悉数据。
2 初步代码
· 数据读取
· 评价指标
2.1 数据读取
由于官方给的数据分布在不同的文件文件夹中,为了方便观察和拆分训练测试集,首先需要把他们合并起来,代码如下:
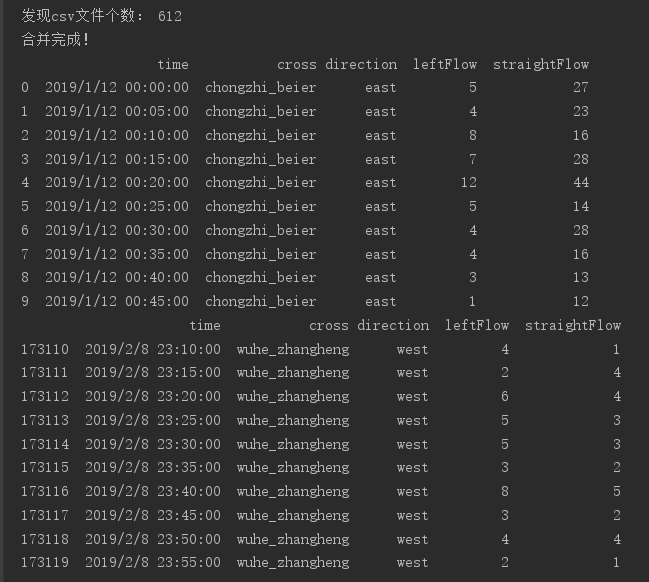
1 import pandas as pd 2 import os 3 4 csv_list = [] 5 # 指定数据集根目录 6 root_path = 'C:/Users/animator/Desktop/pre-data/' 7 # 获取所有日期对应文件夹名 8 for i in os.listdir(root_path): 9 csv_path = root_path + i 10 # 从日期文件夹中获取所有csv文件并添加到列表中 11 for j in os.listdir(csv_path): 12 r_path = csv_path + '/' + j 13 csv_list.append(r_path) 14 15 print("发现csv文件个数:",len(csv_list)) 16 17 # 将列表中所有文件的内容重新写入新文件allData.csv中 18 for i in csv_list: 19 csv = open(i,'rb').read() 20 with open('allData.csv', 'ab') as f: 21 f.write(csv) 22 print("合并完成!") 23 24 # pandas显示首尾数据 25 csv_data = pd.read_csv("./allData.csv",header=None,names=['time','cross','direction','leftFlow','straightFlow']) 26 print(csv_data.head(10)) 27 print(csv_data.tail(10))
运行结果如下:
2.2 评价指标
2.2.1 分类指标代码
1 import numpy as np 2 3 y1 = np.random.randint(0,10,(16,12)) 4 y2 = np.random.randint(0,10,(16,12)) 5 y_ = np.random.randint(0,10,(16,12)) 6 print("前一天天真实值:",y1) 7 print("当天真实值:",y2) 8 print("当天预测值:",y_) 9 r_y_b = (y2 - y1 >= 0) 10 p_y_b = (y_ - y1 >= 0) 11 print('真实趋势(True为增量>=0,False为增量<0):',r_y_b) 12 print('预测趋势(True为增量>=0,False为增量<0):',p_y_b) 13 compare = r_y_b==p_y_b 14 print('趋势比较(True为趋势相同,False为趋势不同):',compare) 15 score = compare.astype(np.int)*100 16 print('分值:',score) 17 18 y_sum = np.sum(y2,axis=1) 19 t_sum = np.sum(y2) 20 print("按小时当日车流量情况:",y_sum) 21 print("当日总车流量为:",t_sum) 22 w = y_sum/t_sum 23 print("各小时占比:",w) 24 25 grade = 0 26 for i in range(len(w)): 27 grade += (1/12) * np.sum(w[i]*score[i]) 28 print("最终分类评分grade=",grade)
运行结果如下:



2.2.2 回归指标代码
1 import numpy as np 2 3 def sigmoid(x): 4 result = 1 / (1 + np.exp(-x)) 5 return result 6 7 8 y = np.random.randint(0,10,(16,12)) 9 y_ = np.random.randint(0,10,(16,12)) 10 print("当天真实值:", y) 11 print("当天预测值:", y_) 12 13 y_sum = np.sum(y,axis=1) 14 t_sum = np.sum(y) 15 print("按小时当日车流量情况:",y_sum) 16 print("当日总车流量为:",t_sum) 17 w = y_sum/t_sum 18 print("各小时占比:",w) 19 20 grade = 0 21 for i in range(len(w)): 22 sum = 0 23 for j in range(len(y[i])): 24 sum += w[i]*sigmoid(30/(pow(y[i,j]-y_[i,j],2)+np.e**-9))*100 25 grade += (1/12)*sum 26 print("最终回归评分grade=",grade)
运行结果如下:
最后只需要按照官方的评分要求,将分类指标评分和回归指标评分按4:6进行归一化就好了。