一、模型的评估方法
(1)留出法:顾名思义,就是留出一部分作为测试样本。将已知的数据集分成两个互斥的部分,其中一部分用来训练模型,另一部分用来测试模型,评估其误差,作为泛化误差的估计。
注意:(1) 两个数据集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入人为的偏差。
(2)数据分割存在多种形式会导致不同的训练集、测试集划分,单次留出法结果往往存在偶然性,其稳定性较差,通常会进行若干次随机划分,重复实验评估取平均值作为评估结果。
(3)数据集拆分成两部分,每部分的规模设置会影响评估结果,测试、训练的比例通常为7:3、8:2
优点:(1)实现简单、方便,在一定程度上能评估泛化误差
(2)测试集和训练集分开,缓解了过拟合
缺点:(1)一次划分,评估结果偶然性大
(2)数据被拆分后,用于训练、测试的数据更少了
(2)交叉验证法:将数据集划分为k个大小相似的互斥的数据子集,子集数据尽可能保证数据分布的一致性(分层采样),每次从中选取一个数据集作为测试集,其余用作训练集,可以进行k次训练和测试,得到评估均值,该验证方法也称作k折交叉验证。使用不同的划分,重复p次,称为p次k折交叉验证。
优点:(1)k可以根据实际情况设置,充分利用了所有样本
(2)多次划分,评估结果相对稳定
缺点:(1)计算比较繁琐,需要进行k次训练和评估
(3)留一法:是k折交叉验证的特殊形式,将数据集分成两个,其中一个数据集记录条数为1,作为测试集使用,其余记录作为训练集训练模型。训练出的模型和使用全部数据集训练得到的模型接近,其评估结果比较准确。缺点是当数据集较大时,训练次数和规模较大。(优缺点同交叉验证法)
(4)自助法:是一种产生样本的抽样方法,其实质是有放回的随机抽样,即从已知数据集中随机抽取一条记录,然后将该记录放入训练集同时放回原数据集,继续下一次抽样,直到测试集中数据条数满足要求。缺点是,数据全集的一些数据可能会在测试集中出现多次,还有一些数据不会出现。现假设,数据全集含有n条数据,利用此方法进行n次采样,则,对于其中的某一次采样,一条记录未被选中的概率为1-1/n,连续n次采样均为被选中的概率为(1-1/n)n,取极限 lim (1-1/n)n = 1/e ≈ 0.37。这说明,通过有放回的抽样获得的训练集去训练模型,不在训练集中的数据(约为37%)用来测试,这样的测试结果被称为包外估计(OOB)
优点:(1)样本量较小时可以通过自助法产生多个自助样本集,且有约37%的测试样本
(2)对于总体的理论分布没有要求
缺点:(1)有放回的抽样引入了额外的偏差
那么这些方法应该怎么选择呢?
(1)已知数据集数量充足时,可以采用留出法或者交叉验证法
(2)对于已知数据集较小且难以有效划分训练集/测试集的时候,采用自助法
(3)对于已知数据集较小且可以有效划分训练集/测试集的时候,采用留一法
二、模型的比较检验
通常我们会选择合适的评估方法和相应的性能度量方法,计算出性能度量后直接比较,但是存在以下问题:
(1)模型评估得到的是测试集上的性能,并非严格意义上的泛化性能,两者并不完全相同
(2)测试集上的性能与样本选取关系很大,不同的划分,测试结果会不同,比较缺乏稳定性
(3)很多模型本身有随机性,及时参数和数据集相同,其运行结果也存在差异(比如随机森林)
下面先了解一个概念,统计假设检验:
事先对总体的参数或者分布做一个假设,然后基于已有的样本数据去判断这个假设是否合理,即样本和总体假设之间的不同时纯属机会变异(因为随机性误差导致的不同),还是两者确实不同。常用的假设检验方法有t-检验法,x2检验法(卡方检验),F-检验法等
基本思想:
(1)从样本推断整体
(2)通过反证法推断假设是否成立
(3)小概率事件在一次实验中基本不会发生
(4)不轻易拒绝原假设
(5)通过显著性水平定义小概率事件不可能发生的概率
(6)全称命题只能被否定而不能被证明
假设检验的步骤如下:
1.建立假设(原假设:搜集证据希望被推翻的假设;备择假设:搜集证据予以支持的假设)
2.确定检验水准(指原假设正确但是最终被拒绝的概率,一般为0.05,0.025,0.01等,也可理解为容忍度)
3.构造统计量
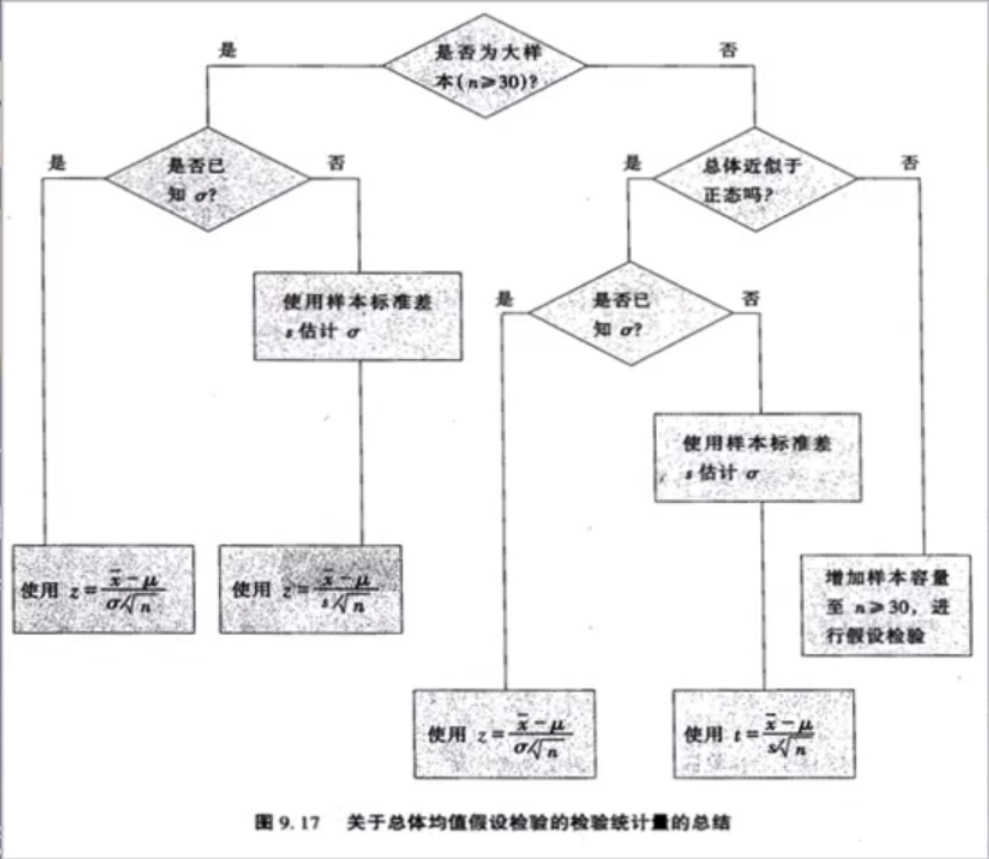
常见检验方法如下:
(1)t 检验:小样本(<30),总体标准差未知的正态分布
(2)F 检验:即方差分析,检验两个正态随机变量的总体方差是否相等
(3)Z 检验:大样本(>=30)平均值差异性检测
(4)x2检验(卡方检验):用于非参数检验,主要是比较两个及两个以上样本率以及两个分类变量的关联性分析
可理解如下图(摘自《商务与经济统计》):
4.计算p值
关于p值:
(1)用来判定假设检验结果的参数,和检验水准相比
(2)在原假设为真的前提下出现观察样本以及更极端的情况的概率
(3)如果p值很小,说明原假设出现的概率很小,应该拒绝,p值越小,拒绝原假设的理由越充足
5.得到结论(如果p值小于等于检验水准,则拒绝原假设;统计量的值如果落在拒绝域内或者临界值则拒绝原假设,否则不能拒绝)