最近项目用到了某专业热门学科的知识网统计分析,先总结一下热门主题的分析流程:
1.根据权威论文期刊网站的文章发表情况,统计某学科/专业的热门主题
2.解析该网站的html代码,从中获取数据
3.首先对热门主题进行拆解分词,得到一个列表
4.统计词频并去重
5.对得到的词频字典进行两两键值的文本相似度分析,若相似度大于0.49,则认为两个短语相似,将其进行合并
6.对最终处理得到的字典倒序排序,打印结果
一、先来看看待处理的数据吧。
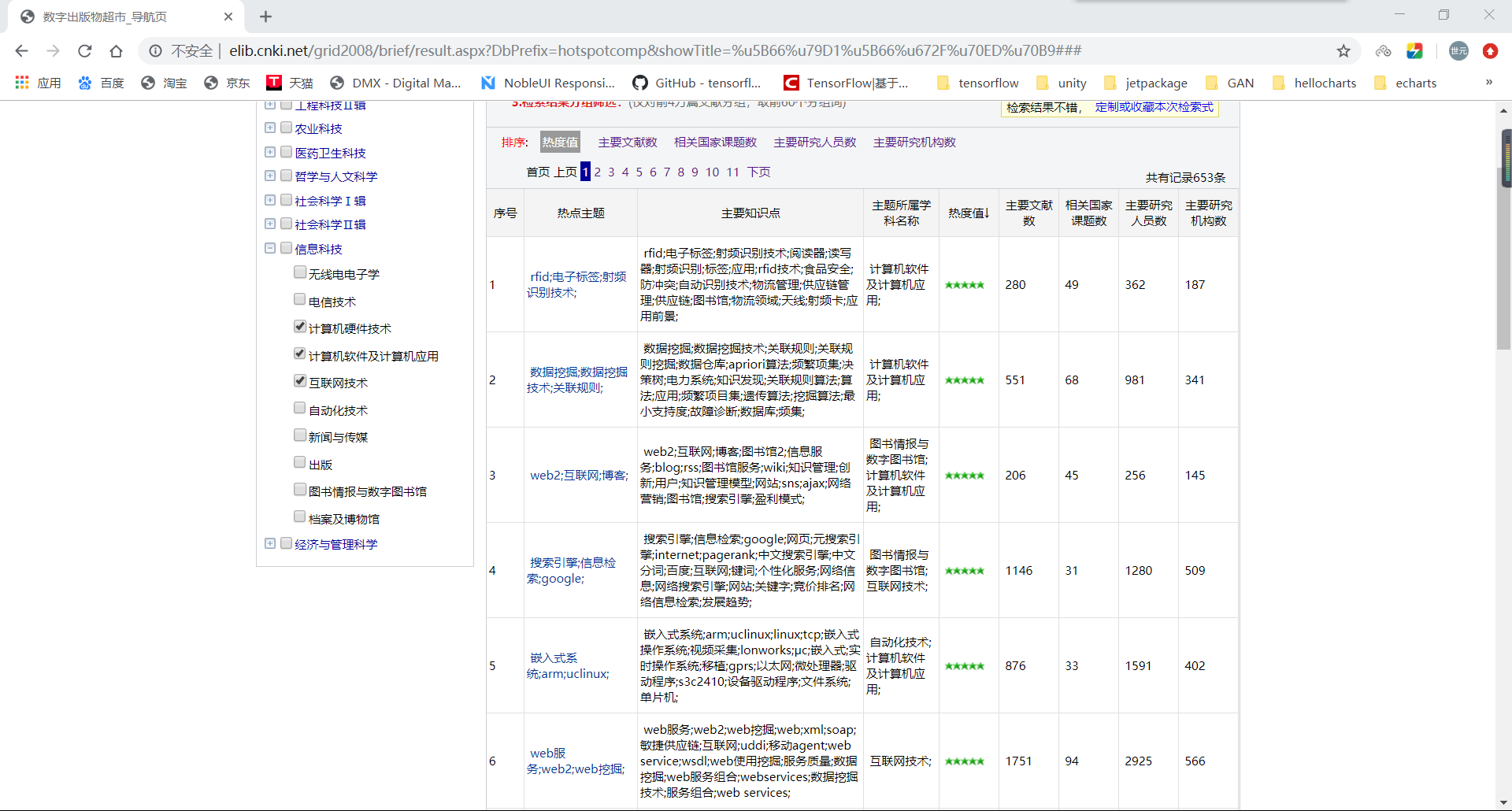
这里选用知网的数据,可以看到,只需要在左侧选择相关专业或者学科,右面就会对应查询出热门主题排行,这里获取整个表格的前一百行,需要的是除索引外前两列数据。主要是对第一列的数据进行相似度分析以及词频统计。获取到html数据后,使用beautifulsoup进行数据的提取,可以看到主题中是用分号进行短语分割的,首先会对这些使用split进行拆分后存到列表里,然后使用Counter统计词频,初步统计之后,列表中还存在例如“数据挖掘”、“数据挖掘技术”这样的相近短语,这时候就需要用到余弦相似度进行文本分析,需要注意的是,余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。这里通过初步分析打印结果发现,相似度超过0.49的基本可以判定为相似。判定相似后,移除相似元素其中的一个,并将移除元素的key对应的value加到相似字典元素上,最后倒序打印即可。
代码如下:
from bs4 import BeautifulSoup from collections import Counter import jieba import numpy as np from operator import itemgetter # 余弦相似度检验文本匹配情况 def cos_sim(str1, str2): co_str1 = (Counter(str1)) co_str2 = (Counter(str2)) p_str1 = [] p_str2 = [] for temp in set(str1 + str2): p_str1.append(co_str1[temp]) p_str2.append(co_str2[temp]) p_str1 = np.array(p_str1) p_str2 = np.array(p_str2) return p_str1.dot(p_str2) / (np.sqrt(p_str1.dot(p_str1)) * np.sqrt(p_str2.dot(p_str2))) # 从本地提供的一个html中获取信息 path = 'soft.html' htmlfile = open(path,'r',encoding='utf-8') htmlhandle = htmlfile.read() # 使用bs提取html中需要的数据 soup = BeautifulSoup(htmlhandle,'lxml') list = soup.find_all('tr') theme_list = [] knowledge_list = [] # 分离热点词汇和相关知识点词汇 for i in list: tds = i.find_all('td') for j in range(len(tds)): if j==1: for k in tds[j].text.split(";"): if k.strip()!='': theme_list.append(k.strip()) elif j==2: knowledge_list.append(tds[j].text.strip()) # 词频统计 counter = Counter(theme_list) dictionary = dict(counter) fenci_list = [] print(dictionary) # print(counter.most_common(10)) # 对每一个热点词汇进行jieba分词,用于后面检验文本相似度 for i in dictionary: fenci_list.append(jieba.lcut(i)) # 操作分词列表,匹配文本相似度,并将相似度大于0.49的热词从字典中进行合并,同时移除后出现的热点词 for i in range(len(fenci_list)): for j in range((i+1),len(fenci_list)): result = cos_sim(fenci_list[i],fenci_list[j]) if result!=0.0: # print(''.join(fenci_list[i])+" 和 "+''.join(fenci_list[j])+" 相似度为:",result) pass if result>0.49: try: value = dictionary.pop(''.join(fenci_list[j])) # print(value) dictionary[''.join(fenci_list[i])]+=value except Exception as e: # print(e) pass print(dictionary) # 将相似文本合并后的结果倒序打印 final_result = sorted(dictionary.items(),key=itemgetter(1),reverse=True) for i in range(len(final_result)): print(final_result[i])
打印结果如下:

