当进行模型训练的时候,往往可能错过模型的最佳临界点,即当达到最大精度的时候再进行训练,测试集的精度会下降,这时候就会出现过拟合,如果能在其临界点处提前终止训练,就能得到表达力较强的模型,从而也避免了过拟合,这种方法就叫early stopping,但是这种方法多依靠人的经验和感觉去判断,因为无法准确的预测后面还有没有最佳临界值,所以这种方法更适合老道的深度学习人员,而对于初学者或者说直觉没有那么准的人,则有一种更简便的方法——dropout,它的大致意思是在训练时,将神经网络某一层的单元(不包括输出层的单元)数据随机丢失一部分。
具体而言,使用dropout集成方法需要训练的是从原始网络去掉一些不属于输出层的单元后形成的子网络,如图:
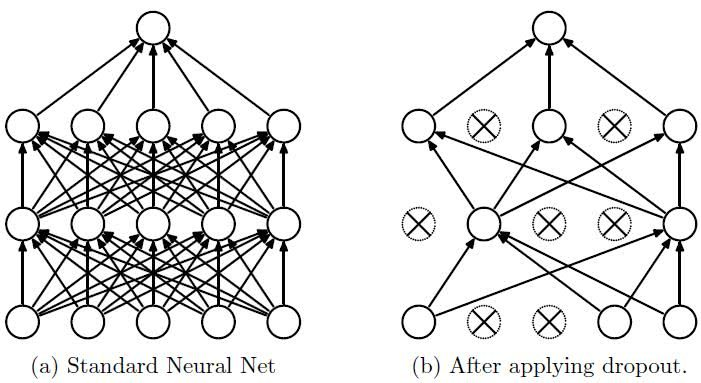
可以将每次的单元丢弃都理解为是对特征的一种再采样,这种做法实际上是等于创造出了很多新的随机样本,以增大样本量,减少特征量的方法来防止过拟合。
在使用复杂的卷积神经网络训练大型的图像识别神经网络模型时使用dropout方法会得到显著的效果,我们可以把dropout的过程想象成随机将一张图片(或某个网络层)中一定比例的数据删除调(即这部分数据都变为0,在图像中0代表黑色),这样就模拟了将图像中某些位置涂成黑色,此时人眼很有可能辨认出这张图片的内容,当然,模型也可以用其进行训练。
tensorflow中提供了很简单的使用方法:
network = keras.Sequential([ keras.layers.Dense(256,activation='relu'), keras.layers.Dropout(0.5), keras.layers.Dense(128,activation='relu'), keras.layers.Dropout(0.5), keras.layers.Dense(64,activation='relu'), keras.layers.Dense(32,activation='relu'), keras.layers.Dense(10) ])
在使用dropout之后,在前向传播时必须声明training参数,因为模型的train和test的策略是不一样的,所以需要人为的做区分,区分方法就是给定training参数的值(True或False),以此来指定当前状态。
代码如下:
for step,(x,y) in enumerate(db_train): # train with tf.GradientTape() as tape: x = tf.reshape(x,(-1,28*28)) out = network(x,training=True) # …… # test out = network(x,training=False)