创建表
drop table student; DROP table Course; DROP table sc; CREATE TABLE student ( sid integer PRIMARY KEY ASC autoincrement not null,--id 升序排序 主键不为空,当为主键时默认为不为空自动增长升序排序 我无聊实践了下,只填primary key创建表比当前这种全写的要快 sname nvarchar(32),--学生名 age integer,--年龄 sex nvarchar(8)--性别 ); create table “main”."Course"--课程表 ( cid integer Not null,--id 这个是公司一个开发写的,感觉很新奇,但是没啥卵用,同上primary key已经解决一切,这样只会让创建表时间延长 cname nvarchar(32),--课程名
primary key ("cid" ASC)
); create table sc --成绩表 ( scid integer PRIMARY KEY autoincrement,--id sid integer,--学生表id cid integer,--课程表id core integer--成绩 ); INSERT into student(sname,age,sex) VALUES ('芳芳',21,'女'), ('婷婷',21,'女'), ('瑞宝',21,'女'), ('不知名',21,'女'); insert into Course(cname) VALUES ('语文'), ('数学'); INSERT into sc(sid,cid,core) VALUES (1,1,80), (1,2,50), (2,1,99), (2,2,99);
各种插入
INSERT into student(sid,sname,age,sex) VALUES (6,'错乱',21,'女')
各种查询
--查询自增id不连续的id select sid from (select sid from student order by sid asc) s where not exists (select 1 from student where sid=s.sid-1); --连接查询,芳芳的数学成绩 select s.sname,sc.core from student s LEFT JOIN sc ON s.sid = sc.sid left JOIN Course c on c.cid =sc.cid WHERE s.sname = '芳芳'; --模糊查询名字有婷的学生 select * from student WHERE sname like '%婷%'; --不用连接查询查询婷婷 的数学成绩 select s.sid,s.sname,scc.core from (SELECT sid,sname FROM student ) s,(SELECT sid,core,cid FROM sc) scc WHERE sname = '婷婷' AND scc.sid = s.sid AND scc.cid = 2 ; --简便多表查询芳芳以外学生的语文成绩 select s.sname,c.cname,sc.core from student s,sc,Course c WHERE s.sname IS NOT '芳芳' and s.sid = sc.sid and sc.cid = c.cid and c.cname = '语文' GROUP BY sc.scid ; --查询出数学比语文高的学生 SELECT s.sid,s.sname,sc1.core FROM (SELECT sid,core FROM sc WHERE cid = '2' ) sc2,(SELECT sid,core FROM sc WHERE cid = '1' ) sc1, (SELECT sid,sname FROM student ) s WHERE s.sid = sc1.sid and sc1.sid = sc2.sid AND sc1.core<sc2.core; --查询成绩100的其他学生 select * FROM student WHERE sname NOT IN (SELECT sname FROM student s,sc WHERE s.sid = sc.sid AND sc.core = 100); --查询成绩大于60的学生个数 select count(distinct(sname)) FROM student s,sc WHERE s.sid = sc.sid AND sc.core>60; --查询平均值大于70的学生 select s.sname,avg(sc.core) from student s,sc WHERE s.sid = sc.sid GROUP BY sc.sid HAVING avg(sc.core)>70;
各种更新--待更新
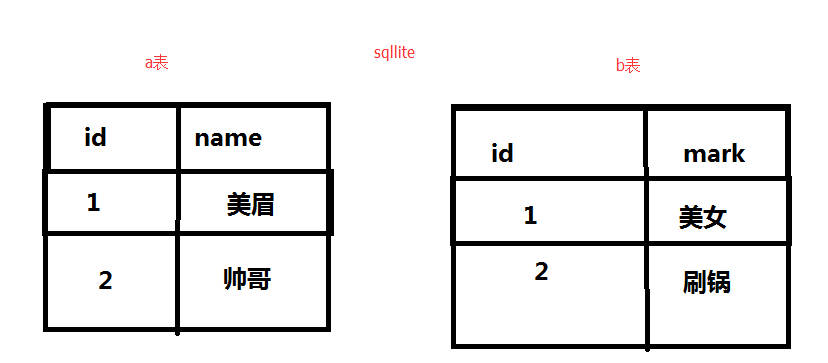
--将mark更新到name update test1 set name = (SELECT mark FROM test2 WHERE test2.id=test1.id) WHERE test1.id=(select DISTINCT id from test2 where test2.id=test1.id)
各种删除--待更新
无聊试验了一下


aaa1比aaa创建的要快,没想到重复操作不简洁还是有点时间消耗的,每种创建10个,aaa1快了0.0001秒。创建表对于速度还是不要求,但如果是公司大数据大量的插入更新将会很明显,有一个代码优化的意识很重要。
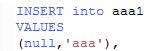
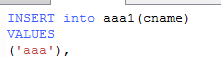
然后这个,第二种竟然比第一种还要快。。
--倒叙查询 id倒叙且只显示前十条 select * from sc order by id desc limit 0,10;