进程:
优点:同时利用多个CPU,同时进行多个操作
缺点:耗费资源(需要重新开辟内存空间)
线程:
优点:共享内存,IO操作时,创造并发操作
缺点:抢占资源
总结:1.进程并不是越多越好,CPU=进程个数, 线程也不是越多越好,如请求上下文切换耗时
2.进程线程的目的提高执行效率
3.计算机中最小的执行单位是线程
4.IO操作利用CPU
A:IO密集型(不用CPU) 使用多线程
B:计算密集型(用CPU)多进程
GIL:全局解释器锁为了锁线程, 作用就是保证同一时刻只有一个线程可以执行代码,因此造成了我们使用多线程的时候无法实现并行。
线程锁:如果多个线程同时修改某个数据,为了防止错误,需要使用锁
主线程等待,子线程执行:
join()
join(2)可以传入参数最多等2s
import threading import time globals_num = 0 lock = threading.RLock() def fun(): lock.acquire()#获得锁 global globals_num globals_num += 1 time.sleep(1) print(globals_num) lock.release()#释放锁 for i in range(10): t = threading.Thread(target=fun) t.start()
#打印:
1
2
3
4
5
6
7
8
9
10
#创建线程 import time import threading def f0(): pass def f1(a1,a2): time.sleep(10) f0() t = threading.Thread(target=f1,args=(123,456))#创建线程执行f1函数,把123,4546传给f1 t.setDaemon(True)#设为True直接执行 # t.setDaemon(False)#设为False等候10秒 t.start() t = threading.Thread(target=f1,args=(123,456))#创建线程执行f1函数,把123,4546传给f1 t.setDaemon(True) # t.setDaemon(False) t.start() t = threading.Thread(target=f1,args=(123,456))#创建线程执行f1函数,把123,4546传给f1 t.setDaemon(True) # t.setDaemon(False) t.start()
Event:
线程间的通讯,一个线程发送一个event,其它线程等待这个信号,用于主线程控制其它线程执行
event.wait():堵塞线程
evnet.set():标识wei位设未True
event.clear():标识位设未False
event.isSet():判断标识位是否为True
import threading def do(event): print("start") event.wait()#红灯wait等待, 绿灯执行 print("execute") event_obj = threading.Event() for i in range(5): t = threading.Thread(target=do, args=(event_obj,)) t.start() event_obj.clear()#event默认为False, 让灯变红 inp = input("input:") if inp == "true": event_obj.set()#让灯变绿执行 #线程执行的时候,如果flag为False,则线程阻塞,为True,线程不会阻塞,提供本地和远程的并发性 # start # start # start # start # start # input:true # execute # execute # execute # execute # execute
threading.Condition: 条件变量condition内部是含有锁的逻辑,不然无法保证线程之间同步
import queue#队列,线程安全,这个模型也叫生产者-消费者模型 import threading message = queue.Queue(10)#数值小于或者等于0,队列大小没有限制。 def producer(i):#生产者 print("put:",i) # while True: message.put(i) def consumer(i):#消费者 # while True: msg = message.get() print(msg) for i in range(12): t = threading.Thread(target=producer,args=(i,)) t.start() for i in range(10): t = threading.Thread(target=consumer,args=(i,)) t.start() # put: 0 # put: 1 # put: 2 # put: 3 # put: 4 # put: 5 # put: 6 # put: 7 # put: 8 # put: 9 # put: 10 # put: 11 # 0 # 1 # 2 # 3 # 4 # 5 # 6 # 7 # 8 # 9
get,等
get_nowait,不等
#创建进程 import multiprocessing import time def f1(a1): time.sleep(2) print(a1) if __name__ == "__main__":#windows下运行进程必须加if __name__ == "__main__": t = multiprocessing.Process(target=f1, args=(11,)) # t.daemon = True#默认False, 定义为True主进程终止全部结束 t.start() t.join()#与线程join类似,主线程等待,子线程执行 t2 = multiprocessing.Process(target=f1, args=(12,)) # t2.daemon = True t2.start() print("end")#主进程
from multiprocessing import Process li = [] def foo(i): li.append(i) print("zc",li) if __name__ == "__main__": for i in range(10): p = Process(target=foo,args=(i,)) p.start() # 每个进程创建自己的列表,进程之间数据,内存不能共享,先调那个由CPU决定所以结果是无序的 # zc [0] # zc [1] # zc [2] # zc [3] # zc [4] # zc [5] # zc [6] # zc [7] # zc [8] # zc [9]
import threading li = [] def foo(i): li.append(i) print("zc",li) if __name__ == "__main__": for i in range(10): p = threading.Thread(target=foo,args=(i,))#threading.Thread线程内存共享,是共同一个li p.start() # zc [0] # zc [0, 1] # zc [0, 1, 2] # zc [0, 1, 2, 3] # zc [0, 1, 2, 3, 4] # zc [0, 1, 2, 3, 4, 5] # zc [0, 1, 2, 3, 4, 5, 6] # zc [0, 1, 2, 3, 4, 5, 6, 7] # zc [0, 1, 2, 3, 4, 5, 6, 7, 8] # zc [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
from multiprocessing import Process #多进程 Multiprocessing 模块 def f(name): print("hello",name) if __name__ == "__main__": p = Process(target=f, args=("bob",)) # Process类进程对象,创建子进程的时候,只需要传入一个执行函数和函数的参数即可完成 #target 函数名,需要调用的函数 #args 函数需要的参数,以 tuple 的形式传入 p.start()#star() 方法启动进程 p.join()#join() 方法实现进程间的同步,等待所有进程退出。 # p.close()#阻止多余的进程涌入进程池 Pool 造成进程阻塞。
import multiprocessing import os def run_proc(name): print('Child process {0} {1} Running '.format(name, os.getpid())) # os.getpid()获取当前进程id os.getppid()获取父进程id if __name__ == '__main__': print('Parent process {0} is Running'.format(os.getpid())) for i in range(5): p = multiprocessing.Process(target=run_proc, args=(str(i),)) print('process start') p.start() p.join() print('Process close') # Parent process 27428 is Running # process start # process start # process start # process start # process start # Child process 0 27176 Running # Child process 1 23384 Running # Child process 3 11524 Running # Child process 2 11560 Running # Child process 4 24904 Running # Process close
#进程间内存数据共享方式1 from multiprocessing import Process,Value,Array #Value(内存数据共享),Array(数组,与列表相似) def f(n,a): n.value = 3.1415 for i in range(len(a)): a[i] = -a[i] if __name__ == "__main__": num = Value("d",0.0) arr = Array("i",range(10)) p = Process(target=f,args=(num,arr))#进程1 a = Process(target=f,args=(num,arr))#进程2 p.start() a.start() p.join() a.join() print(num.value) print(arr[:]) # 3.1415 # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 数据共享后负负得正 #进程间内存数据共享方式2 from multiprocessing import Process, Manager def f(d,l): d[l] = "1" d["2"] = 2 d[0.26] = None l.reverse() if __name__ == "__main__": with Manager() as manager: d = manager.dict() l = manager.list(range(10)) p = Process(target=f,args=(d,l))#创建进程处理函数里面的d,l变量 p.start() p.join() print(d) print(l) #{<ListProxy object, typeid 'list' at 0x24626a370b8>: '1', '2': 2, 0.26: None} # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
进程池:
python提供了进程池,Pool
from multiprocessing import Pool import time def f1(a): time.sleep(1) print(a) return 1000 def f2(arg): print(arg)#arg值是f1的返回值 if __name__ == "__main__": Pool = Pool(5)#创建5个进程池 for i in range(40):#5个5个执行 Pool.apply_async(func=f1, args=(i,),callback=f2) #1.每个任务并发执行,先执行5个当有进程的时候再执行5个.内部没有join()方法需要定义如下: #2.可以设置回调函数callback print("1111111111111111") # Pool.apply(func=f1, args=(i,)) #一个一个申请执行,一个执行完才执行下一个,内部有join()方法,不用定义 Pool.close()#执行完后终止 # Pool.terminate()#立即终止 Pool.join()#进程池的join方法一个一个执行,join方法前面必须先定义close,terminate方法
简单版线程池:
import queue import threading import time class ThreadPool(object): #创建线程池类 def __init__(self, max_num=20): #创建一个最大长度为20的队列 self.queue = queue.Queue(max_num) #创建一个队列 for i in range(max_num): #循环把线程对象加入到队列中 self.queue.put(threading.Thread) #把线程的类名放进去,执行完这个Queue,20个队列指向同一个Thread类 def get_thread(self): #定义方法从队列里获取线程 return self.queue.get() #在队列中获取值 def add_thread(self): #线程执行完任务后,在队列里添加线程 self.queue.put(threading.Thread) def func(pool,a1): time.sleep(1) print(a1) pool.add_thread() #线程执行完任务后,队列里再加一个线程 p = ThreadPool(10) #执行init方法; 一次最多执行10个线程 for i in range(100): thread = p.get_thread() #线程池10个线程,每一次循环拿走一个拿到类名,没有就等待 t = thread(target=func, args=(p, i,)) #创建线程; 线程执行func函数的这个任务;args是给函数传入参数 t.start() #激活线程 #输出无序的0-99数 # 对象等于类后面加括号 # 对象是线程
复杂版线程池:
线程池要点:
1,创建线程池时,是在需要执行线程的时候创建线程,而不是创建好最大队列等待执行
2,创建一个回调函数,检查出剩余队列的任务,当线程执行完函数的时候通知线程池,
3,使用线程池时让其循环获取任务,并执行
4,线程池,让其自行的去激活线程,执行完成后,关闭退出
import queue import threading import time import contextlib StopEvent = object() class ThreadPool(object): def __init__(self, max_num): self.q = queue.Queue() # 最多创建的线程数(线程池最大容量) self.max_num = max_num self.terminal = False #如果为True 终止所有线程,不在获取新任务 self.generate_list = [] # 真实创建的线程列表 self.free_list = []# 空闲线程数量 def run(self, func, args, callback=None): """ 线程池执行一个任务 :param func: 任务函数 :param args: 任务函数所需参数 :param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数) :return: 如果线程池已经终止,则返回True否则None """ if len(self.free_list) == 0 and len(self.generate_list) < self.max_num: self.generate_thread() #创建线程 w = (func, args, callback,) #把参数封装成元祖 self.q.put(w) #添加到任务队列 def generate_thread(self): """ 创建一个线程 """ t = threading.Thread(target=self.call) t.start() def call(self): """ 循环去获取任务函数并执行任务函数 """ current_thread = threading.currentThread # 获取当前线程 self.generate_list.append(current_thread) #添加到已经创建的线程里 event = self.q.get() # 取任务并执行 while event != StopEvent: # 是元组=》是任务;如果不为停止信号 执行任务 func, arguments, callback = event #解开任务包; 分别取出值 try: result = func(*arguments) #运行函数,把结果赋值给result status = True #运行结果是否正常 except Exception as e: status = False #表示运行不正常 result = e #结果为错误信息 if callback is not None: #是否存在回调函数 try: callback(status, result) #执行回调函数 except Exception as e: pass if self.terminal: # 默认为False,如果调用terminal方法 event = StopEvent #等于全局变量,表示停止信号 else: # self.free_list.append(current_thread) #执行完毕任务,添加到闲置列表 # event = self.q.get() #获取任务 # self.free_list.remove(current_thread) # 获取到任务之后,从闲置列表中删除;不是元组,就不是任务 with self.worker_state(self.free_list, current_thread): event = self.q.get() else: self.generate_list.remove(current_thread) #如果收到终止信号,就从已经创建的线程列表中删除 def close(self): #终止线程 num = len(self.generate_list) #获取总共创建的线程数 while num: self.q.put(StopEvent) #添加停止信号,有多少线程添加多少表示终止的信号 num -= 1 def terminate(self): #终止线程(清空队列) self.terminal = True #把默认的False更改成True while self.generate_list: #如果有已经创建线程存活 self.q.put(StopEvent) #有几个线程就发几个终止信号 self.q.empty() #清空队列 @contextlib.contextmanager def worker_state(self, state_list, worker_thread): state_list.append(worker_thread) try: yield finally: state_list.remove(worker_thread) def work(i): print(i) pool = ThreadPool(10) for item in range(50): pool.run(func=work, args=(item,)) # 将任务放在队列中 # 着手开始处理任务 # - 创建线程 # - 有空闲线程,择不再创建线程 # - 不能高于线程池的限制 # - 根据任务个数判断 # - 线程去队列中取任务 pool.terminate()
协程:
Python的 greenlet就相当于手动切换,去执行别的子程序,在“别的子程序”中又主动切换回来
greenlet协程例子:
# 协程就是:把线程分块,不让线程等待,让线程遇到IO请求先执行1,或先执行2,或先执行3叫做协程 from greenlet import greenlet # greenlet 其实就是手动切换;gevent是对greenlet的封装,可以实现自动切换 # import gevent def test1(): print("123") gr2.switch() # 切换去执行test2 print("456") gr2.switch() # 切换回test2之前执行到的位置,接着执行 def test2(): print("789") gr1.switch() # 切换回test1之前执行到的位置,接着执行 print("666") gr1 = greenlet(test1) # 创建的协程,启动一个协程 注意test1不要加() gr2 = greenlet(test2) # gr1.switch() # 123 # 789 # 456 # 666
gevent 实现协程:
Gevent 是一个第三方库,可以轻松通过gevent实现协程程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
gevent会主动识别程序内部的IO操作,当子程序遇到IO后,切换到别的子程序。如果所有的子程序都进入IO,则阻塞。
协程之gevent例子:
import gevent def func1(): print("func1 running") gevent.sleep(2) # 内部函数实现io操作 print("switch func1") def func2(): print("func2 running") gevent.sleep(1) print("switch func2") def func3(): print("func3 running") gevent.sleep(0) print("func3 done..") gevent.joinall([gevent.spawn(func1), gevent.spawn(func2), gevent.spawn(func3), ]) # func1 running # func2 running # func3 running # func3 done.. # switch func2 # switch func1
同步与异步性能区别:
同步: 发一个请求需要等待返回, 所有的操作都做完,才返回给用户结果。即写完数据库之后,在响应用户,用户体验不好。使用场景:银行转账,数据库保存操作
异步: 发一个请求不需要等待返回,不用等所有操作等做完,就响应用户请求。即先响应用户请求,然后慢慢去写数据库,用户体验较好。 使用场景:为了避免短时间大量的数据库操作,就使用缓存机制,也就是消息队列。先将数据放入消息队列,然后再慢慢写入数据库。
import gevent def task(pid): """ Some non-deterministic task """ gevent.sleep(0.5) print('Task %s done' % pid) def synchronous(): for i in range(1, 10): task(i) def asynchronous(): threads = [gevent.spawn(task, i) for i in range(10)] gevent.joinall(threads) print('Synchronous:') synchronous() print('Asynchronous:') asynchronous() # Synchronous: # Task 1 done # Task 2 done # Task 3 done # Task 4 done # Task 5 done # Task 6 done # Task 7 done # Task 8 done # Task 9 done # Asynchronous: # Task 0 done # Task 1 done # Task 2 done # Task 3 done # Task 4 done # Task 5 done # Task 6 done # Task 7 done # Task 8 done # Task 9 done
上面程序的重要部分是将task函数封装到greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
遇到Io阻塞时会切换任务之【爬虫版】
from urllib import request
import gevent,time
from gevent import monkey
monkey.patch_all() # 把当前程序中的所有io操作都做上标记
def spider(url):
print("GET:%s" % url)
resp = request.urlopen(url)
data = resp.read()
print("%s bytes received from %s.." % (len(data), url))
urls = [
"https://www.python.org/",
"https://www.yahoo.com/",
"https://github.com/"
]
start_time = time.time()
for url in urls:
spider(url)
print("同步耗时:",time.time() - start_time)
async_time_start = time.time()
gevent.joinall([
gevent.spawn(spider,"https://www.python.org/"),
gevent.spawn(spider,"https://www.yahoo.com/"),
gevent.spawn(spider,"https://github.com/"),
])
print("异步耗时:",time.time() - async_time_start)
# GET:https://www.python.org/
# 48814 bytes received from https://www.python.org/..
# GET:https://www.yahoo.com/
# 492112 bytes received from https://www.yahoo.com/..
# GET:https://github.com/
# 81165 bytes received from https://github.com/..
# 同步耗时: 43.494789600372314
# GET:https://www.python.org/
# GET:https://www.yahoo.com/
# GET:https://github.com/
# 492000 bytes received from https://www.yahoo.com/..
# 59868 bytes received from https://github.com/..
# 48814 bytes received from https://www.python.org/..
# 异步耗时: 21.32669472694397
通过gevent实现【单线程】下的多socket并发
server端:
import sys import socket import time import gevent from gevent import socket, monkey monkey.patch_all() def server(port): s = socket.socket() s.bind(('0.0.0.0', port)) s.listen(500) while True: cli, addr = s.accept() gevent.spawn(handle_request, cli) def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(9999)
client端:
import socket HOST = 'localhost' # The remote host PORT = 9999 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"), encoding="utf8") s.sendall(msg) data = s.recv(1024) # print(data) print('Received', repr(data)) s.close()
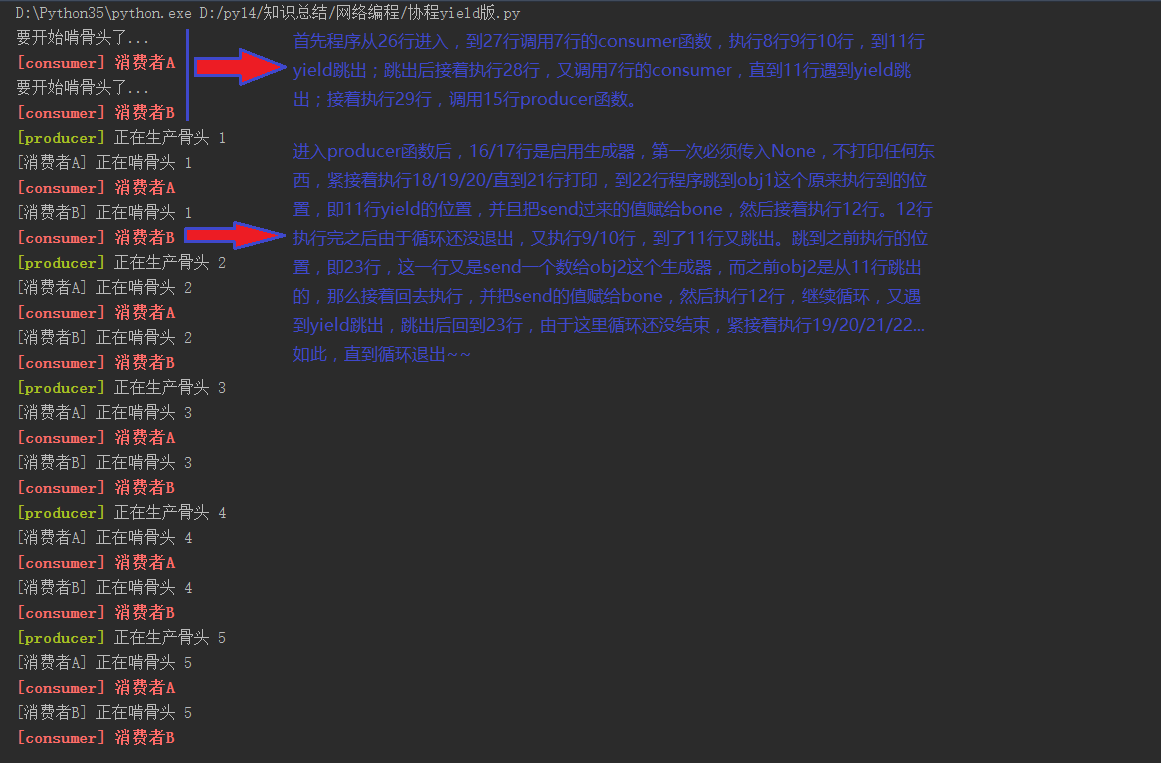
yield实现协程
前文所述“子程序(函数)在执行过程中可以中断去执行别的子程序;别的子程序也可以中断回来继续执行之前的子程序”,那么很容易想到Python的yield,显然yield是可以实现这种切换的。
使用yield实现协程操作例子:
def consumer(name): print("要开始啃骨头了...") while True: print("�33[31;1m[consumer] %s�33[0m " % name) bone = yield print("[%s] 正在啃骨头 %s" % (name, bone)) def producer(obj1, obj2): obj1.send(None) # 启动obj1这个生成器,第一次必须用None <==> obj1.__next__() obj2.send(None) # 启动obj2这个生成器,第一次必须用None <==> obj2.__next__() n = 0 while n < 5: n += 1 print("�33[32;1m[producer]�33[0m 正在生产骨头 %s" % n) obj1.send(n) obj2.send(n) if __name__ == '__main__': con1 = consumer("消费者A") con2 = consumer("消费者B") producer(con1, con2)