topic
在kafka中消息是按照topic进行分类的;每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic
parition
一个topic可以配置几个parition,每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的,如下图:
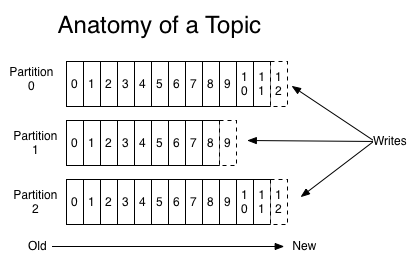
producer能指定将此消息发送到哪个parition(也可以采取随机、哈希、轮训等策略):
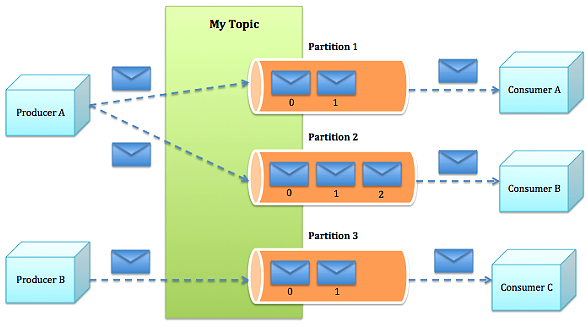
producer发送消息到broker时,会根据paritition机制选择将其存储到哪一个partition。如果partition机制设置合理,所有消息可以均匀分布到不同的partition里,这样就实现了负载均衡。如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而有了partition后,不同的消息可以并行写入不同broker的不同partition里,极大的提高了吞吐率。
consumer group
producer发送的消息分发到不同的parition中,consumer接受数据的时候是按照group来接受,kafka确保每个parition只能同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费
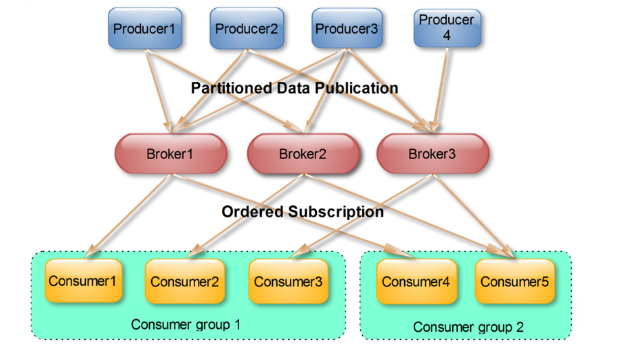
consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。
consumer group特性:
-
consumer group下可以有一个或多个consumer instance
-
group.id是一个字符串,唯一标识一个consumer group
-
consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
消费者位置(consumer position)
很多消息引擎都把这部分信息保存在服务器端(broker端)。这样做的好处当然是实现简单,但会有三个主要的问题:
- broker从此变成有状态的,会影响伸缩性;
- 需要引入应答机制(acknowledgement)来确认消费成功。
- 由于要保存很多consumer的offset信息,必然引入复杂的数据结构,造成资源浪费。
而Kafka选择了不同的方式:每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了;同时可以引入checkpoint机制定期持久化,简化了应答机制的实现。
老版本的位移是提交到zookeeper中的,目录结构是:/consumers/<group.id>/offsets/<topic>/<partitionId>,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。因此kafka提供了另一种解决方案:增加__consumeroffsets topic,将offset信息写入这个topic,摆脱对zookeeper的依赖(指保存offset这件事情)。__consumer_offsets中的消息保存了每个consumer group某一时刻提交的offset信息。