1 背景
1.1 什么是leader选举
在zookeeper集群中,每个节点都会投票,如果某个节点获得超过半数以上的节点的投票,则该节点就是leader节点了
1.2 zookeeper集群选举leader节点的目的又是什么
zookeeper集群,有好几个节点。每个节点都可以接收请求,处理请求。那么,如果这个时候分别有两个客户端向两个节点发起请求,请求的内容是修改同一个数据,就会出现问题,所以,需要leader节点进行管理分发
1.3 如何进行选举
zookeeper提供了三种选举机制
- LeaderElection
- AuthFastLeaderElection
- FastLeaderElection
默认的算法是FastLeaderElection,所以本文主要分析它的选举机制
2 FastLeaderElection选举算法
2.1 简述
首先所有Server提议自己要成为leader,同时,通过异步的通信方式来收集其它节点的选票,同时在分析选票时又根据投票者的当前状态来作不同的处理,直到有一个server获取票数获取过半,选举结束。
2.2 几个原则
注:我表示当前节点
- 默认推荐自己
- 每当我接收到其它的被推举者,我都要回馈一个信息,表明我还是不是推举我自己。如果被推举者没我大,我就一直推举我自己当leader
- 一旦我不再推举我自己了(这时我发现别人推举的人比我编号大),我就把我的票箱清空,重新发起一轮投票(这时我的票箱一定有两票了)
- 一旦我发现收到的推举信息中投票轮要高于我的投票轮,我也要清空我的票箱。并且还是投当初我觉得我要推荐的那个人(除非当前的人比我最初的推荐编号大,我就顺带更新我的推荐)
- 不断的重复上面的过程,不断的告诉别人“我的投票是第几轮”、“我推举的人是谁”。直到我的票箱中“我推举的人”收到了大于 N /2的推举投票
- 这时我就可以决定我是flower还是leader了。并且不论随后收到谁的投票,都向它直接反馈“我的结果”
2.3 选举的流程图
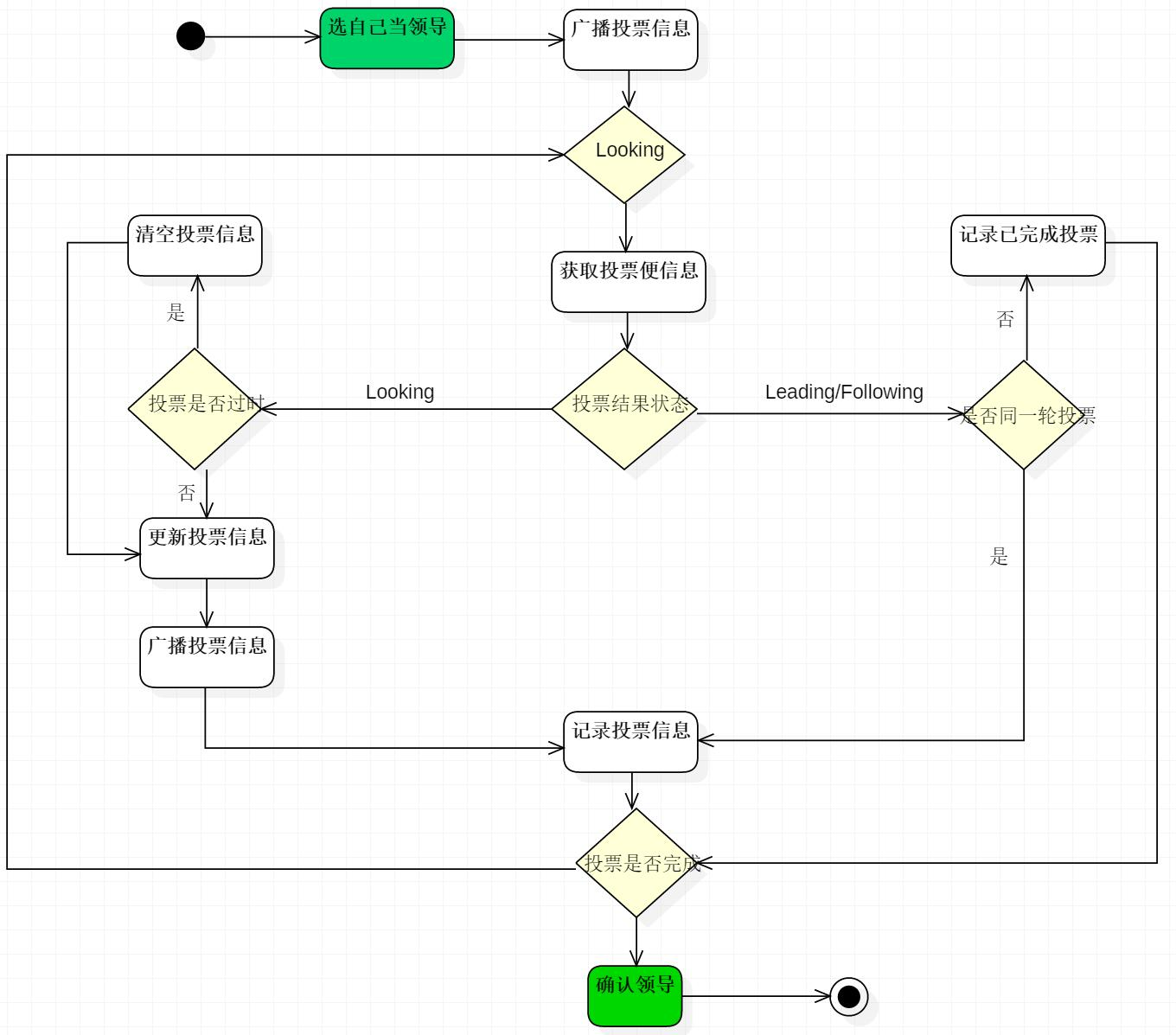
状态变化:

2.5 结果
理想结果:
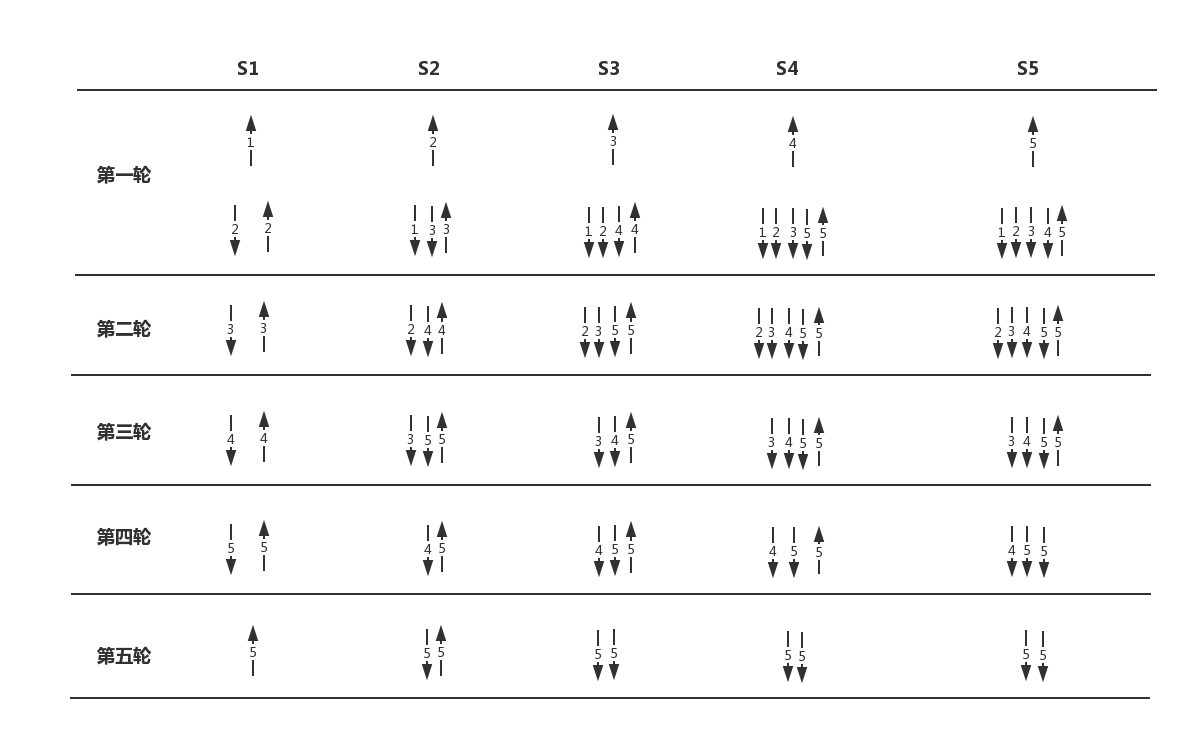
更现实的结果:
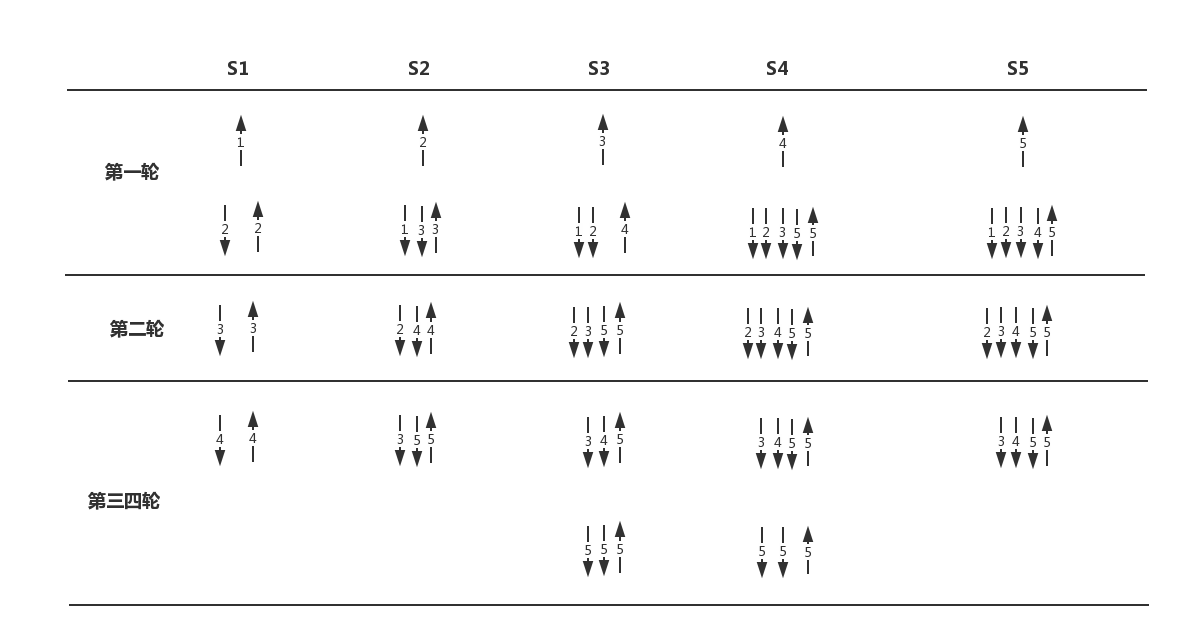
2.6 实现原理
2.6.1 名词定义
- Serverid:在配置server时,给定的服务器的标示id。
- Zxid:服务器在运行时产生的数据id,zxid越大,表示数据越新。
- Epoch:选举的轮数。随着选举的轮数++
- Server状态:LOOKING,FOLLOWING,LEADING
2.6.2 如何处理
每个Server都一个接收线程池和一个发送线程池, 在没有发起选举时,这两个线程池处于阻塞状态,直到有消息到来时才解除阻塞并处理消息,同时每个Serve r都有一个选举线程
- 主动发起选举端(选举线程)的处理
首先自己的 logicalclock加1,然后生成notification消息,并将消息放入发送队列中, 系统中配置有几个Server就生成几条消息,保证每个Server都能收到此消息,如果当前Server 的状态是LOOKING就一直循环检查接收队列是否有消息,如果有消息,根据消息中对方的状态进行相应的处理
- 主动发送消息端(发送线程池)的处理
将要发送的消息由Notification消息转换成ToSend消息,然后发送对方,并等待对方的回复
- 被动接收消息端(接收线程池)的处理
将收到的消息转换成Notification消息放入接收队列中,如果对方Server的epoch小于logicalclock则向其发送一个消息(让其更新epoch);如果对方Server处于Looking状态,自己则处于Following或Leading状态,则也发送一个消息(当前Leader已产生,让其尽快收敛)