三,论文研读
- 论文名称:马瑞民,李向云.Web日志挖掘数据预处理技术的研究[J].计算机工程与设计,2007(10):102358-2360.
- 研究对象
对Web日志挖掘中数据预处理技术的研究,相比博文二的论文研读这篇博文的不同之处在于,该文章提出一种算法,简化了预处理的过程,只需要4个阶段工作便可得到用户的数据。 - 研究动机
对传统5阶段Web日志挖掘中数据预处理进行改进,提出只需根据网站拓扑结构,不需要使用路径补充技术,由用户访问序列直接生成事务的算法。 - 文献综述
Web日志挖掘流程(研究框架)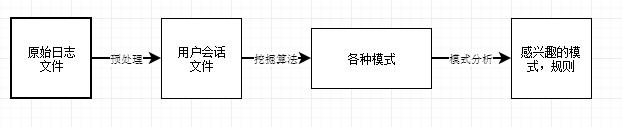
Web日志挖掘预处理流程
数据清理
用户识别
会话识别
用户访问序列获得事务算法
事务识别是从用户访问会话序列中找出有意义的页面访问序列,即用户访问事务。之前数据预处理中事务识别之前是使用路径补充技术来补全访问日志中没有记录的用户请求,获得用户完整的访问路径,正确识别有意义的用户访问路径,然后采用最大向前引用路径来定义事务。
从用户访问序列获得事务的算法(STT),根据网站拓扑结构,不需要补充回退路径,得到用户访问路径,对其进行识别,最终得到访问事务数据。
STT算法
STT算法首先把网站的树形拓扑结构转换成二叉树的结构,然后在二叉树结构上根据用户的会话序列得到事务序列。
获得最大向前参引路径的算法如下:
IniStack(St); //初始化栈
P=T; //P 指向二叉树的根结点
flag=0;
While (S!=Null) //判断用户访问序列是否结束
{ if (flag0)
If (P) { //如果根的当前结点与用户访问序列中的当前结点相同,将其加入到 Path 中
If (P->dataS)
{ 把 P 加入到 Path 中,S++;
if (flag0) Flag=1;}
push(St,P); //把当前结点压入栈中
P=P->lchild;} //指向 P 的左孩子结点
else { pop(St,P); //栈顶元素出栈并赋给 P
P=P->rchild; } //指向 P 的右孩子结点
else if (P) { if (P->dataS)
{ 把 P 加入到 Path 中,S++;
push(St,P);
P=P->lchild; }
Else { push(St,P);
P=P->rchild; }
Else { if (P 的前一个结点是左结点) 保存当前路
径 Path;
pop(St,P);
if (P 在 path 中)从 path 中删去 P;
P=P->rchild;}
if(StackEmpty(St)) //如果栈空但访问序列并未结束,则
将 P 指向树根结点,flag 赋为 0
{ P=T; flag=0; }
}
- 研究方案设计
- 使用数据集
- 研究结论
使用STT算法使预处理过程得到简化,提高了日志挖掘的效率。 - 学习心得
这篇文章较博文二那篇有改进之处,简化了预处理的过程,在算法实现上还要再看看。