二,论文研读总结
-
论文名称:韩法旺. Web日志挖掘数据预处理过程研究[J]. 南京工业职业技术学院学报, 2012, 12(2):53-56.
-
研究对象
对web日志挖掘数据预处理的研究,同时结合所看专著第三章数据预处理,进行研读。 -
研究动机
web日志文件的格式是半结构化的,并且日志中的数据也不够完整,由此要对web文件进行预处理转化为挖掘算法易于使用的,具有良好格式的数据, -
文献综述
预处理一般过程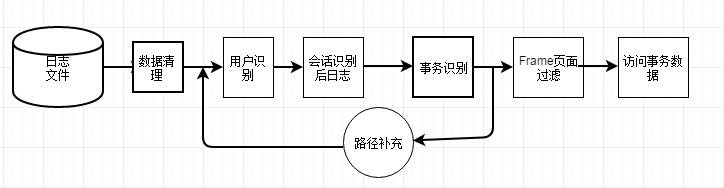
对web数据进行预处理过程包括数据清理,用户识别,会话识别,事务识别,路径补充,Frame页面清理。
数据清理
把web日志中和挖掘目的无关的数据项清除,把对挖掘目的有用的数据转换成数据挖掘需要的格式。通常删除特定的后缀名,及无用记录,减少数据量。
用户识别
识别每个访问网站的用户,将用户和访问网站相关联,发现访问特点,用户模式分析。参考用户识别规则。
会话识别
基于时间间隔,连续请求两个web页面时间差值超过T,就认为该用户开启了新的会话。还有一篇文献对此进行了改进。
会话识别算法
Function Distance(H,f)
H为按照时间排序会话历史记录;f 为网页文件
Set min=∞
For each H i ∈H do
If f j ∈ H i
d i =H, size()-H i ,index(f)
t i =H i ·t n -H i ·t j
if(d i <min)
assign-i
min-d i
else if(d i =min)
if(t i <t assign )
assign=i
return assign
end
Distance()函数
Heuristic Identify
1.让H i ={f 1 ,f 2 ……f n }是一个时间序列的会话历史记录。
2.让 1 j , f j , r j , t j 分别表示为一条日志记录实体、 referrer 和时
间。
3.T 表示时间间隔, 当时间间隔大于 T 时, 表示开始新的会
话。一般 T 都用 30分钟, 而最好时间间隔为 25.5分钟。
4.数据按照 IP 地址、 Agent 和时间排序。
5.for each unique IP/Agent pair do
6. for each I j do
7. if[ (t j -t j-1 )<T] V r j ∈{H 0 , ……, H m }then
8. i++;
9. Add I j to H i
10. Else
11. Assign-Distance (H, r j )
12. Add r j to H assign
路径补充
针对会话识别过程中重要的请求没被记录,大多数访问路径是不完整的。路径补充的任务就是将遗漏的请求补充到用户会话中,具体有两种方法:(1)如果请求的页面不能从用户最后一个请求直接访问,就检查日志中的这个请求从哪里来,如果存在于用户最近最近访问记录,假设是由用户“后退”操作造成。(2)假定用户访问记录多于一个页面连接到这个请求页面,就按最接近它的当前页面,是新请求页面的来源。
事务识别
把单独的数据事件集成事务,在进行相应的数据挖掘和分析。
Frame页面过滤
消除frame页面对挖掘结果的影响,提高web日志挖掘结果的兴趣性。
- 使用数据集
- 研究结论
- 学习心得
该论文就整体介绍了,对web日志挖掘数据预处理的一般过程,得出预处理过程的一般模型,结合其他文献可以更深入的了解各个过程的实现细节。