1. 流处理的场景
我们在定义流处理时,会认为它处理的是对无止境的数据集的增量处理。不过对于这个定义来说,很难去与一些实际场景关联起来。在我们讨论流处理的优点与缺点时,先介绍一下流处理的常用场景。
- 通知与警报:可能流应用最明显的例子就是通知(notification)与警报(alerting)。
- 实时报道:许多公司会使用流系统来跑一个实时的、让每个员工都可以看到的dashboard。例如,一个报告实时游客的dashboard
- 增量ETL:其中一个最常见的流应用就是:减少各个公司在抽取数据到一个数据仓库中时都必须忍受的延迟。Spark 批处理经常用于ETL的工作负载,将原始数据转换成一个结构化的格式,例如Parquet,使得后续的query更高效。使用structured streaming,这些jobs可以与新数据在秒级时间内结合,让下游用户可以更快地query这些数据。在这个使用场景下,非常关键的一点是:数据在处理时必须满足exactly-once,并且在一种fault-tolerant 形式下。我们不希望任何数据在被放入数据仓库前丢失,也不希望任何数据被放入两次。还需要满足的一点是,流系统在对数据仓库执行update时,必须是事物地,这样才不会导致运行其上的query只访问到部分写入的数据。
- 实时更新数据:例如有一个dashboard给用户query数据,流系统可以保持数据的最新版本。一般在这种场景下需要流应用能对一个key-value store(或是其他系统)执行增量更新,作为同步。一般还需要这些更新是事务的,如ETL里一样,防止应用崩溃。
- 实时决策:例如信用卡欺诈,需要基于历史的状态,来判断信用卡的transaction 是否涉嫌欺诈
- 在线机器学习:类似于实时决策,不过实时决策是hard-code 规则,而在线机器学习是使用持续的数据更新模型,系统更为复杂。一般涉还涉及到多个用户、与static数据集的join、与机器学习库集成等等。
2. Continues Vs Micro-Batch Execution
Continues 是一次处理一个record。
优点是:提供尽可能低的latency(如果整体input rate 相对较低的话)
缺点是:吞吐(throughput)不够高,因为在处理每个record时,会引入额外的overhead(例如调用操作系统发送网络包到下游)
限制是:operators的拓扑一般是固定的,在runtime时不能被拿走,除非停止整个系统,否则会引入负载不均衡的问题。
Micro-batch系统是等待聚集一个小的batch之后(例如500ms的数据),再使用分布式的tasks对每个batch并行处理。
优点是:
- 对每个节点,都能达到高吞吐,并且还能执行批处理中的优化(例如向量化处理),并且不会引入额外的per-record overhead。所以它可以使用更少的节点处理相同速率的数据。
- 还能使用动态的load balance 技术,处理变化的负载(例如增加节点或减少节点)。
缺点是:下游应用会有更高的延时(latency),因为需要等待一个micro-batch的数据聚集。
在实际应用中,如果一个流应用是非常大规模的、甚至需要做分布式计算的,则倾向于高吞吐优先。
在选择两种模式时,主要的选择因素是:latency以及total costs of operation(TCO)。Micro-batch一般可以完美的deliver latencies 100ms 到 1s左右(取决于 application)。在达到这种延迟时,一般也需要更少的节点达到与continues模式同样的吞吐,所以它的运作成本也相对更低(包括更低的维护成本,因为节点更少)。若是需要更低的延时,则应考虑continues processing system;或者使用micro-batch系统与一个fast serving layer 结合,以提供低延时的queries(例如,将数据输出到MySQL或者Cassandra,它们可以为客户端提供milliseconds级别的服务)
3. Structured Streaming基础
Structured Streaming 是基于Spark SQL 引擎而构建的流处理框架,它直接使用了已有的Spark structured API(DataFrames,Datasets,以及SQL)。
Structured Streaming的核心思想是:将流数据视为一个数据持续追加的表。然后job会定期检查新的输入数据,处理,更新一些内部状态(存储在一个state store中),并更新它的结果。它的API很重要的一个特点是:我们并不需要更改代码来分别batch或是stream处理,仅需要指定query是运行为batch还是streaming模式即可。在Structured Streaming内部会自动决定如何增量处理我们的query,例如:在新数据到 达时,高效地更新它的结果,并且会议fault-tolerant的方式运行。
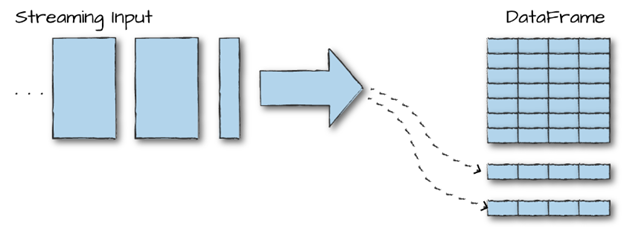
简单地说,Structured Streaming就是”your DataFrame,but streaming“。
4. 核心概念
1. Transformation 与 Action:Transformation 与 Spark中的常见transformation 差不多,而对于Action,在Structured Streaming中仅有一个action,就是starting a stream,它会开始持续运行并输出结果。
2. Input Sources
Structured Streaming 支持多种输入源,对于Spark 2.2 版本来说,支持Kafka、位于分布式文件系统(例如HDFS、S3)上的文件(Spark仅持续读取一个文件夹中的新文件)、socket source(用于测试)
3. Sinks
Sinks 指定的是流输出的目的地。Sinks和处理引擎同时也负责可靠地追踪数据完整的处理过程。下面是Spark 2.2 支持的output sinks:
- Kafaka
- 几乎任何文件格式
- 一个foreach sink,用于运行测试计算输出
- Console sink(用于测试)
- Memory sink(用于debug)
4. 输出模式(output modes)
为Structured Streaming job 定义了sink后,仅完成了一半的输出配置。我们还需要定义Spark如何向sink写入数据。例如,我们是想要追加新数据?还是根据输入的数据流更新已有数据(例如更新一个给定web page 的点击量)?我们需要每次都完整地重写结果集吗(例如,使用计算出来的完整点击量,覆盖之前的文件内容)?诸如此类,我们需要定义一个输出模式(output mode),类似于static Structured APIs 中的output modes。
支持的输出模式有:
- Append:仅追加新纪录到output sink中
- Update:更新有变动的records
- Complete:重写整个输出
这里很重要的一点是,对于特定queries、以及特定sinks,仅支持特定的output modes。例如,假设我们的job仅在stream上执行一个map操作。输出的数据则会随着输入的数据不断到来而趋近与无穷,此时使用Complete 则是不合理的,因为它每次都会将所有数据写入到一个新文件中。而若是我们的job执行的是一个聚合操作,仅聚合数据到一个有限数量的keys中,则Complete和Update就是合适的,但是Append就不合适,因为有些key的值需要随时间更新。
5. 触发器(Triggers)
Output modes 定义的是输入如何输出,而triggers定义的是数据何时输出,也就是说,Structured Streaming什么时候应该检查新输入数据并更新它的结果。默认情况下,Structured Streaming会在完成处理了上一组输入数据后,立即look for 新的输入records。不过,若是sink是一组文件,则这个行为会导致写入大量的小的输出文件。所以,Spark 也支持基于处理时间来触发trigger(仅以固定时间频率look for 新数据)
6. Event-Time Processing
Structured Streaming 也支持event-time processing(也就是基于record内自带的时间戳处理乱序数据)
7. Event-Time 数据
Event-time 表示的是嵌入到数据中的time字段。也就是说,在处理时并非按照record到达的时间,而是record生成的时间,因为records可能会由于网络等原因造成乱序到达。在Structured Streaming中表示event-time非常简单,因为这个系统是将输入数据视为一个table,所以event-time就是table中的一个字段而已。所以应用可以执行grouping、aggregating、以及windowing,使用标准SQL操作符即可。不过在Structured Streaming 内部,它在知道了一个column是一个event-time 字段后,会执行一些特别的actions,包括优化query执行、或是决定什么时候可以放心的忽略一个time window有关的state。大部分这些actions由watermarks控制
8. Watermarks
Watermarks是流系统里的一个功能,可以允许我们指定how late they expect to see data in event time。例如,在一个处理手机终端日志的系统中,我们可能会预期日志能达到最高30分钟的延迟到达(由于上传中的delay)。对于支持event time 的系统,包括Structured Streaming,一般会允许设置watermarks,用来限制它们需要remember old data的时长。Watermarks 也可以用于控制什么时候为一个特定的event time window输出一个结果(例如等待直到它的watermark过去后)。