Apache Kafka
1. Kafka简介、优势、以及使用场景
Kafka的优势:
- 开源
- 分布式,弹性架构,fault tolerant
- 水平扩展:
- 可以扩展到100个brokers
- 可以扩展到每秒百万级条消息
- 高性能(延迟少于10ms)-- 实时
使用场景:
- 消息系统
- 活动追踪(Activity Tracking)
- 从各个不同的地点收集指标信息(IOT)
- 应用日志收集
- 流处理(使用Kafka Streams API 或 Spark 等)
- 系统依赖之间的解耦
- 与Spark,Flink,Storm,Hadoop以及许多其他Big Data技术集成
场景举例:
- Netflix使用Kafka做实时推荐(比如看节目的同时为你推荐节目)
- Uber使用Kafka收集用户,出租车以及路程的实时信息,并据此计算、预测车辆需求,以及计算实时的(加/减)价格
- LinkedIn使用Kafka防止spam,收集用户交互信息以做更好的实时connection recommendation
2. Kafka术语
2.1. Topics,partitions以及offsets
- Topics:一个特定的数据流
- 类似于一个数据库中的一个表(无约束的表)
- 可以创建任意多个
- 一个topic由它的名字作为识别
- Topics被split成partitions
- 每个partition都是有序的
- 在一个partition中的每条消息都有一个递增id(incremental id),称为offset(可以增至到无限大)
例如:以下是一个Kafka Topic,包含三个Partitions(由创建时指定)。每个partitions中的messages都有一个递增id,即为消息的offset:
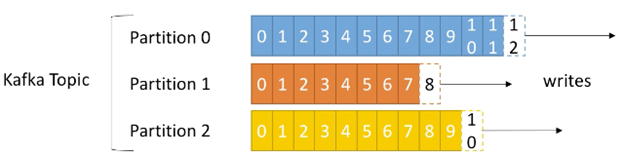
基于上图的Kafka Topic,需要注意以下几点:
- Offset仅对一个特定的partition有意义
- 也就是说,在partition 0 中的offset 3 与partition 1 中的 offset 3 并不是同样的消息
- “有序”仅在partition中有保障(并不能跨paritions)
- 数据仅被保留一定的时间(默认是一周),但是offset会一直增长
- 一旦数据被写入到一个partition,它就不会被改变(例如update数据等)(immutability性质)
- 除非给定了一个key,否则数据被随机的分配到一个partition中
2.2. Brokers 与 Topics
那topics 是由什么支持(hold)的呢?答案是brokers。
- 一个Kafka 集群(cluster)由多个brokers(servers)组成。一个broker对应一个server
- 每个broker由它的ID(Integer)作为标志符
- 每个broker包含某些topic partitions。例如,一个topic的多个partitions分布在多个brokers中。
- 在连接到任何一个broker(称为一个bootstrap broker)上后,客户端既连接到整个集群
- 一般3个brokers是一个比较好的开始,不过一些大的集群有超过100个brokers
在接下来的例子中,我们会为brokers的id选择从100开始:

假设我们现在 Topic-A有3个partitions,Topic-B有2个partitions,则partitions的一种分布为:

Kafka会自动将partitions跨集群分布,所以在每个broker上,都会放置Topic-A的一个partition。对于Topic-B,它会任选两个brokers放置它的两个partitions。而若是有一个Topic-C有3个partitions,则其中一个broker会有两个partitions。
2.3. Topic Replication
Topic Replication的主要功能是为了防止一个broker宕机后,此broker上的数据仍可以在其他地方被访问。
Topic replication factor
Topics应配置一个 > 1的replication factor(一般为2或3),这样在一个broker宕机后,另一个broker可以仍提供这部分数据。下面是一个例子,Topic-A有两个partition,且replication factor配置为2:
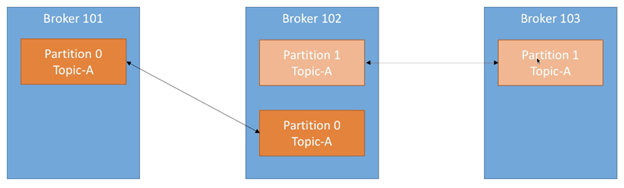
假设我们此时丢失了broker 102:

可以看到Broker 101 与 Broker 103 仍可以提供Topic-A的所有partition数据。
Partitions中的leader
在topic replication中,任意时刻,对于一个给定的partition:
- 仅有一个broker可以作为此partition的人leader
- 仅此leader 可以接收此partition的数据并提供数据
- 另外的brokers会同步数据
所以每个partition会有一个leader以及多个ISR(in-sync replica),例如:
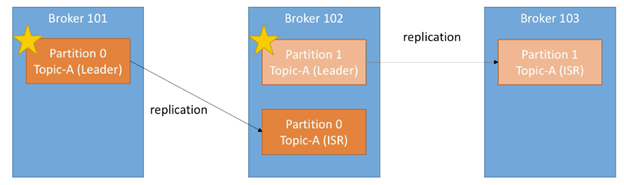
谁决定leader与ISR?答案是zookeeper。
如果一个broker down,则会发生election(zookeeper)。假设broker 101 宕机,则broker 102 会变为Topic-A 中Parition 0的leader。之后若是broker 101 恢复,则它会在同步数据后再次尝试成为leader。Leader 与 ISR的角色是由zookeeper 决定的。
2.4. Producers
- Producers写数据到(由partitions组成的)topics中
- Producers可以自动了解到需要向哪个broker和partition写入数据,并不需要指定特定broker
- 在broker failure时,producers会自动recover
下面是一个Producer例子:

若是未指定message的key,则producer会以轮询的方式向这些Partition写入消息。所以,在producer向kafka写入数据时,是以load balance 的方式写入的。
Producers可以选择是否为数据的写入接收ack,有以下几种ack的选项:
- acks=0:producers不等待ack(可能会造成数据丢失)
- acks=1:producers会等待leader 的ack(有限数据丢失)
- acks=all:leader与replicas 的 ack(无数据丢失)
Producers: Message keys
- Producers在发送message时可以选择指定一个key,类型可以为string、number等
- 如果key=null,则数据以轮询的方式发送(例如broker 101,然后broker 102,然后broker 103)
- 如果一个key已经被发送,则所有具有相同key的message均会发送到同一个partition中
- 使用key的基本场景是:对于一个特定的字段,消息需要有序
下面举个例子,以truck_id 为key:

truck_id_123 的数据会一直发送到partition 0(假设)
truck_id_234 的数据会一直发送到 partition 1(假设)
而key的分发是由hash决定的,根据hash值,然后对partitions的数量取模。
2.5. Consumers
- Consumers从一个topic(以topic name作为识别)读数据
- Consumers知道从哪个broker读数据
- 在broker failure时,consumers知道如何recover
- 在每个partition中,数据都是按顺序读取
下面是一个Consumer的示意图:

Consumer Groups
Consumers如何从所有的partition中读取数据?=> Consumer Groups
- Consumers以consumer groups的方式读取数据
- 在一个group中,每个consumer从一个独立的partition中读数据
- 如果consumers的数目超过了partitions数目,则一些consumers会成为inactive
下面举个例子,我们有一个Topic-A,它包含3个partitions。如果consumer group 中有两个consumers(consumer-group-application-1),则其中一个consumer会从两个partition中读数据。
如果consumer group中有3个consumers(consumer-group-application-2),则每个consumer均会对应一个partition。如果consumer group中仅有一个consumer,则此consumer会从所有partition中读数据。如下图所示:
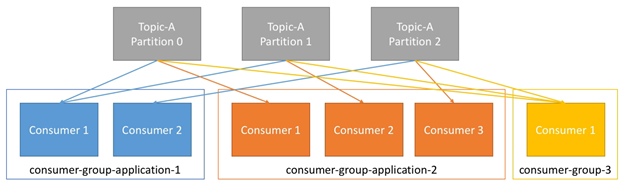
需要注意的是:Consumers会自动使用一个GroupCoordinator和一个ConsumerCoordinator,用于将一个consumer分配给一个partition。
如果有过多的consumers(比partition数目更多),则一些consumers会成为inactive状态:

2.6. Consumer Offsets
- Kafka存储offsets,用于表示一个consumer group 已经读取到的位置
- Committed offsets 存储在一个Kafka的topic中,名为__consumer_offsets
- 当一个group中的一个consumer已经处理了从Kafka收到的数据后,它会committing the offsets
- 如果一个consumer died,它可以在之后从committed offsets的地方继续读取数据并处理
下图是一个例子:
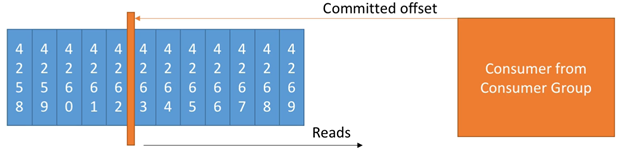
Delivery semantics for consumers
Consumer 决定何时commit offsets,这里有3中delivery 语义:
- 最多一次(At most once):
- 在message被接收后,立即commit offsets
- 如果成功接收,但是处理失败,则message会丢失(不会再次读取此message并处理)
- 至少一次(At least once)(优先选项):
- 在message被应用处理后,再commit offsets
- 如果处理失败,则message会重新再读取
- 这个会导致messages的重复处理,需要确保处理逻辑是idempotent(再次处理messages并不会影响系统结果)
- 精确一次(Exactly once):
- 可以由Kafka => Kafka 的workflow 实现(使用Kafka Streams API)
- 对于Kafka => 外部系统的workflow,建议使用idempotent consumer
2.7. Kafka Broker Discovery
- 每个Kafka broker也被称为一个“bootstrap server”
- 也就是说,仅需要连接到一个broker,即可连接到整个集群
- 每个broker知道所有brokers,topics,以及partitions的信息(metadata)
如下图所示,broker discovery的流程如下:
- 客户端连接到一个bootstrap server,并请求metadata
- Bootstrap server 会返回所有brokers以及它们的ip地址
- 客户端连接需要的brokers
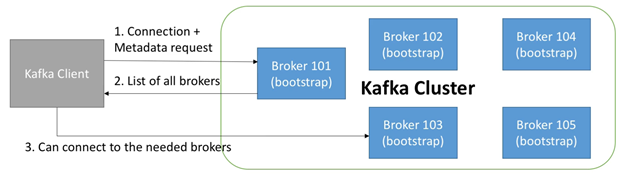
2.8. Zookeeper
- Zookeeper 管理brokers(维护brokers的一个list)
- 协助执行partition的leader election
- Zookeeper向Kafka发送各种changes的提醒消息(例如,新topic,broker dies,broker comes up,delete topics,等等…)
- Kafka 无法脱离zookeeper 工作
- Zookeeper一般会有单数个数的servers(3,5,7等)
- Zookeeper有一个leader(处理写),其余servers为followers(处理读)
- 在Kafka > v0.10 的版本中,zookeeper不再存储consumer的 offsets
下面是一个例子:
不同的brokers可以连接到不同的zookeeper,但是仅有leader zookeeper处理写,follower zookeeper仅处理读。Zookeeper 会向kafka通知集群中的变化(例如新的broker,broker 宕机等)

Kafka Guarantees
Kafka可以保证以下场景:
- Messages按照它们被发送的顺序添加到一个topic-partition中
- Consumers按序读取一个topic-partition中的messages
- 指定replication factor 为N,则producers与consumers可以容忍最多N-1个brokers 宕机。一般指定replication factor 为3:
- 允许一个broker临时下线做维护
- 同时也允许另一个broker意外宕机
- 只要一个topic的partition数目是一定的(没有新的partitions),则同样key的message会永远发送到同一个partition中
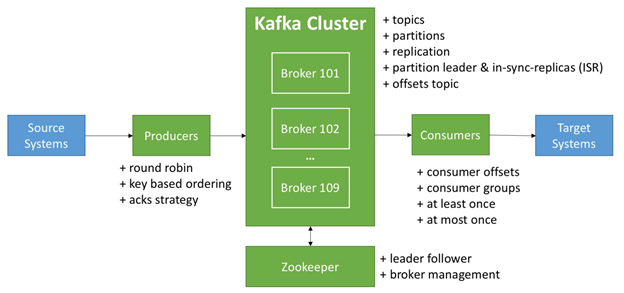
3. 总结
下面是对Kafka中术语的一个总结,可以对比此图再熟悉一下Kafka中的各个术语: