学习笔记:deeplearning.ai的《卷积神经网络》
一. 卷积层Convolutional layers
卷积神经网络中含有卷积层、池化层、全连接层。
全连接层与卷积层区别在于Z=W*X+b这一块:全连接层的*是乘法运算,卷积层的*是卷积运算。
卷积层的特点:
- 参数共享
- 稀疏连接、局部不变性:输出层的特征只取决于输入层的少数特征(就是过滤器的大小的特征)
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器
池化层作用是进行特征选择,降低特征数量,从而减少参数数量。
1. 边缘检测
卷积运算 * ,过滤器filter与数据集进行卷积运算。当过滤器为下图格式时,可作为边缘检测

边缘检测主要分为垂直边缘检测、水平边缘检测;还有其他的各种角度的边缘检测——就是让过滤器参数取不用的值。输出矩阵元素为0,代表没有边缘;元素为正:“1”所在边亮、“0”所在边暗;元素为负的:“1”所在边暗,“0”所在边亮
2. Padding
填充图像为了解决图片在卷积运算时会不断变小的问题
填充后再处理图片:((n+2p−f+1)×(n+2p−f+1))
因此,在进行卷积运算时,我们有两种选择:
- Valid 卷积:p=0,直接卷积。
- Same 卷积:进行填充,并使得卷积后结果大小与输入一致,这样 (p=frac{f−1}{2})
在计算机视觉领域,(f)通常为奇数。
原因:
- Same 卷积中(p)能得到自然数结果
- 滤波器有一个便于表示其所在位置的中心点。
3. Stride
步长:每次移动的距离
4. 立体卷积
立体卷积运算中:过滤器和输入通道维度必须相同;输出通道维度取决于过滤器的数量
一般经过几层卷积后,输出的高度和宽度逐渐减小,深度(通道长度)逐渐增大。

二. 池化层Pooling layers
-
池化层分为Max pooling(取最大值)和Average pooling(取平均值)。
-
池化过程的特点之一是,它有一组超参数,但是并没有参数需要学习。池化过程的超参数包括滤波器的大小(f)、步长(s),以及选用最大池化还是平均池化。而填充(p)则很少用到。
-
池化层不需要学习参数。与卷积层不同的是池化层与输入层的通道数相同,是用过滤器分别对每一层进行池化。
池化与下采样
下采样:缩小图像
上采样:放大图像
卷积过程导致的图像变小是为了提取特征;池化下采样是为了降低特征的维度,虽然结果都是图像或者特征图变小,但是目的是不一样的。
为什么要池化下采样?
- 减少需要处理的特征图的元素个数,降低特征维度,减少计算量、防止过拟合
- 通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构。
三. Classic networks
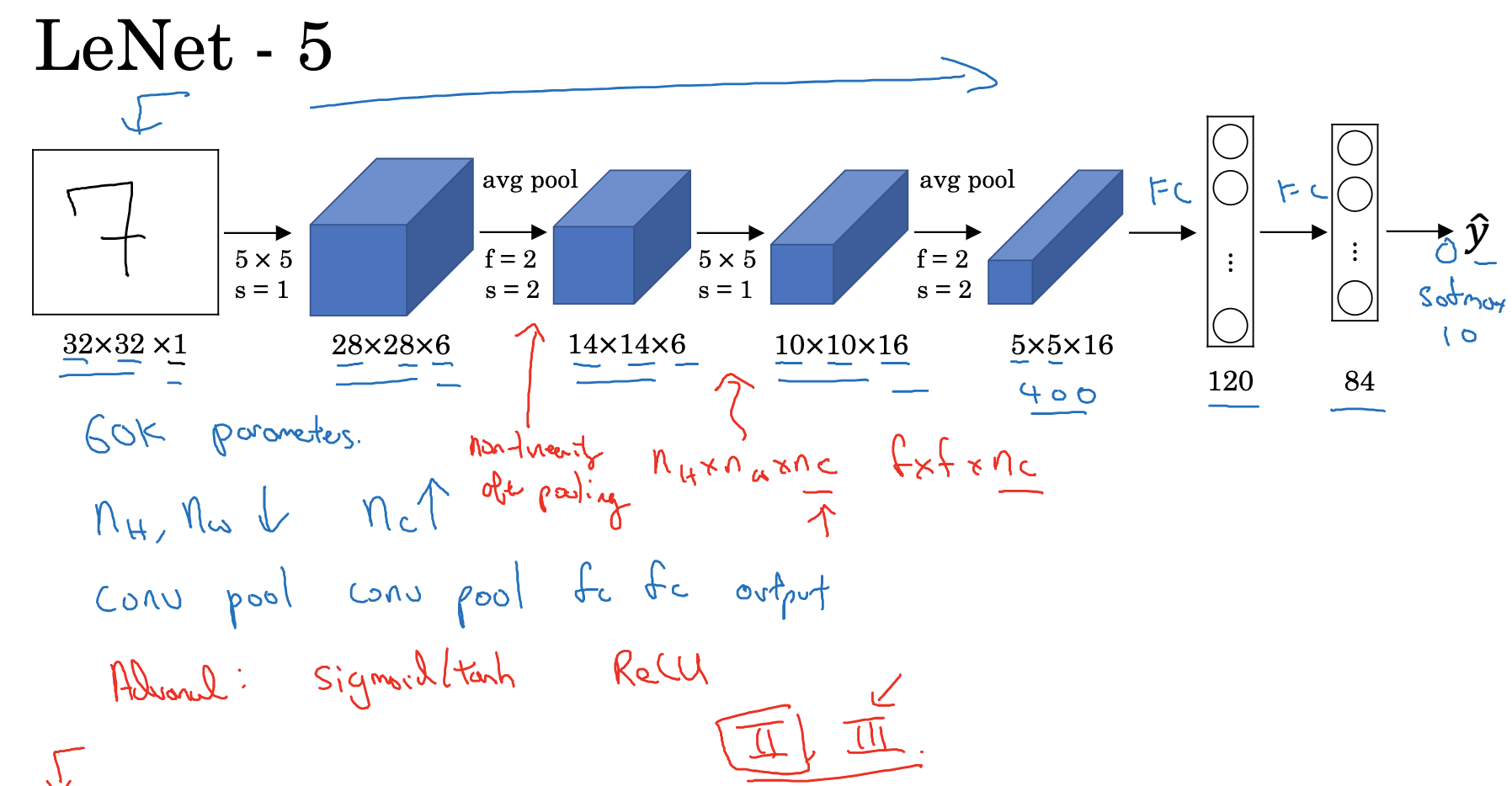
1. LeNet-5
特点:
- LeNet-5 针对灰度图像而训练,因此输入图片的通道数为 1。
- 该模型总共包含了约 6 万个参数,远少于标准神经网络所需。
- 典型的 LeNet-5 结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为 CONV layer->POOL layer->CONV layer->POOL layer->FC layer->FC layer->OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。
- 当 LeNet-5模型被提出时,没有padding方法,所以高度宽度都在不断变小,其池化层使用的是平均池化,而且各层激活函数一般选用 Sigmoid 和 tanh。现在,我们可以根据需要,做出改进,使用最大池化并选用 ReLU 作为激活函数。
相关论文:LeCun et.al., 1998. Gradient-based learning applied to document recognition。吴恩达老师建议精读第二段,泛读第三段。
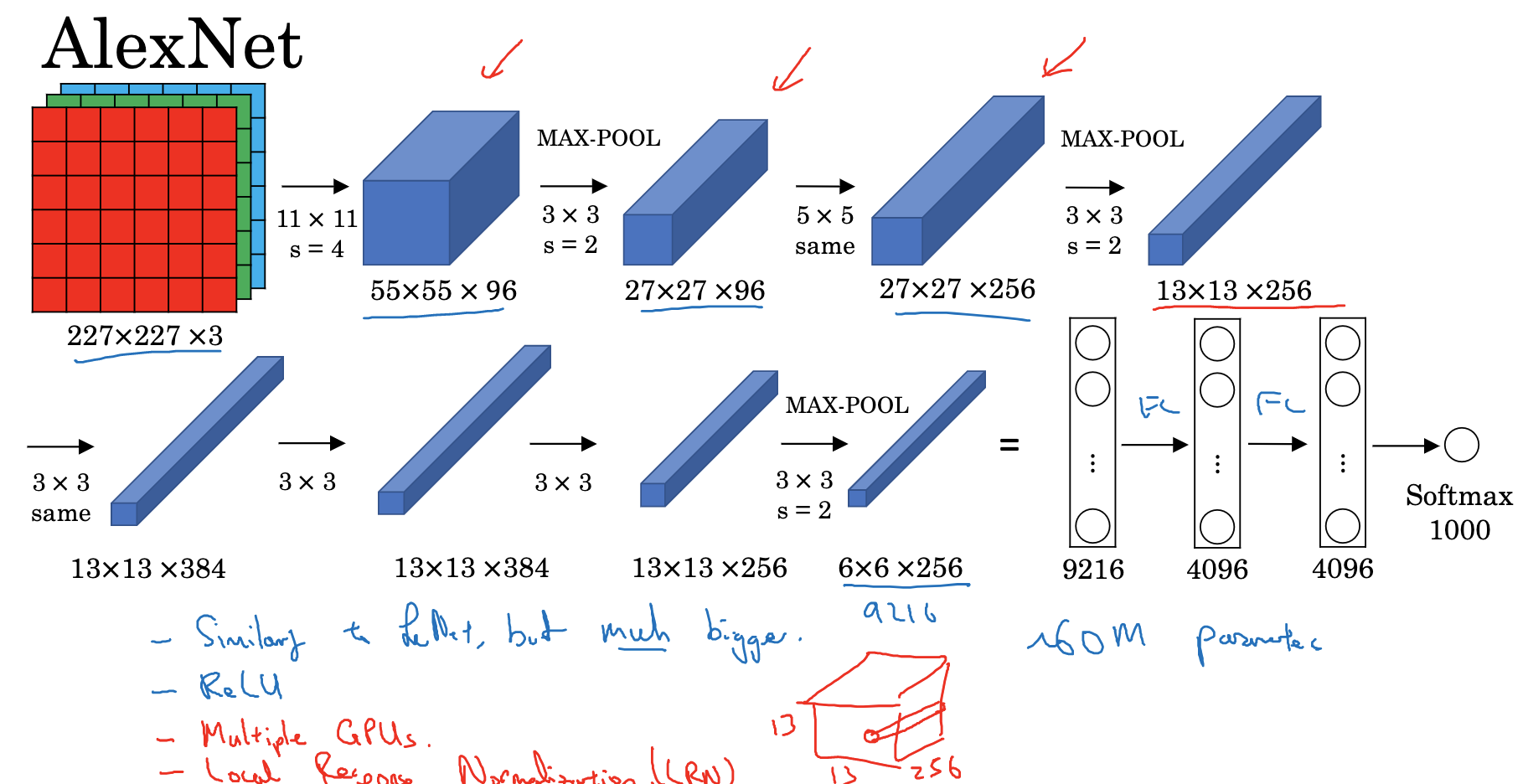
2. AlexNet
特点:
- AlexNet 模型与 LeNet-5 模型类似,但是更复杂,包含约 6000 万个参数。另外,AlexNet 模型使用了 ReLU 函数。
- 使用了padding,valid卷积和same卷积+池化层+全连接层结合的方式
- 当用于训练图像和数据集时,AlexNet 能够处理非常相似的基本构造模块,这些模块往往包含大量的隐藏单元或数据。
相关论文:Krizhevsky et al.,2012. ImageNet classification with deep convolutional neural networks。这是一篇易于理解并且影响巨大的论文,计算机视觉群体自此开始重视深度学习。
3. VGG
特点:
- VGG 又称 VGG-16 网络,“16”指网络中包含 16 个卷积层和全连接层。
- 没有使用valid卷积。并且same卷积时通道的增加和池化层高度宽度的减小都是成倍的
- 超参数较少,只需要专注于构建卷积层。
- 结构不复杂且规整,在每一组卷积层进行滤波器翻倍操作。
- VGG 需要训练的特征数量巨大,包含多达约 1.38 亿个参数。
相关论文:Simonvan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition。

四. ResNet残差网络
residual blocks残差块
skip connectin 跳远连接:把a[l]增加到计算a[l+2]的非线性处理中去
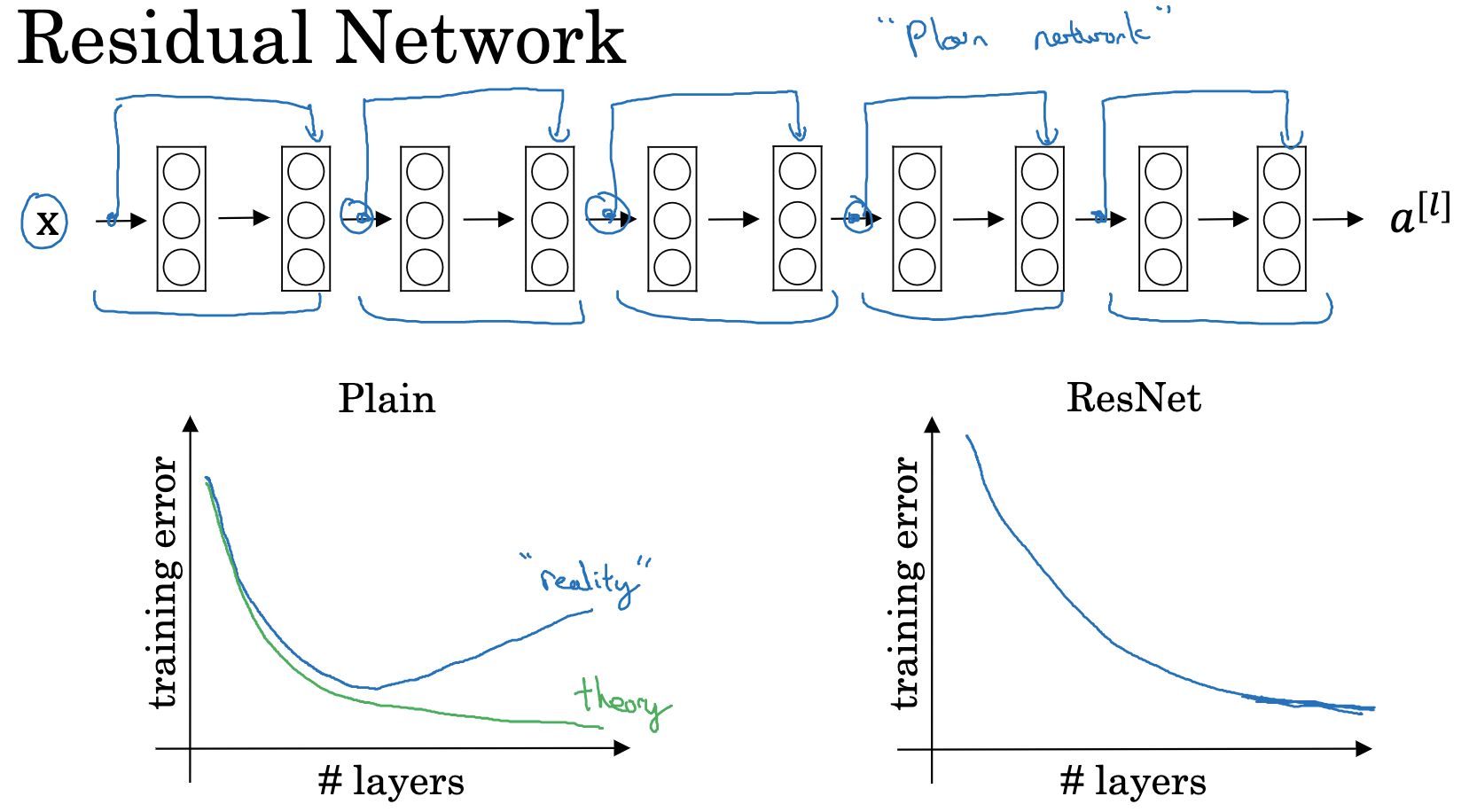
因为存在梯度消失和梯度爆炸问题,网络越深,就越难以训练成功。增加残差块有助于解决这个问题,,甚至可以提高效率。
卷积层通常使用 Same 卷积以保持维度相同,而不同类型层之间的连接(例如卷积层和池化层),如果维度不同,则需要引入矩阵(W_s)。
五. network in network
1*1的过滤器可以用于压缩、保持或增加输入层的通道数量而不改变高度和宽度——取决于过滤器的数量
虽然same卷积层也可以做到,但是1*1可以大幅减小计算成本
1*1卷积核在Inception等地方有了很重要的作用
六. Inception
参考博客:Inception论文笔记
1. 为什么用Inception
提高网络最简单粗暴的方法就是提高网络的深度和宽度,即增加隐层和以及各层神经元数目。但这种简单粗暴的方法存在一些问题:
-
会导致更大的参数空间,更容易过拟合
-
需要更多的计算资源网络越深,梯度容易消失,优化困难(这时还没有提出BN时,网络的优化极其困难)
Inception可以用于避免这些问题
2. Inception结构
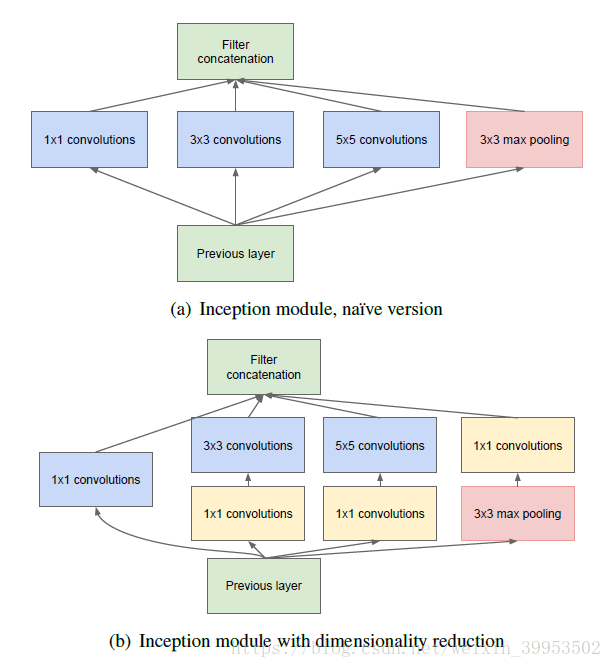
首先看第一个结构,有四个通道,有1*1、3*3、5*5卷积核,该结构有几个特点:
- 使用这些大小卷积核,没有什么特殊含义,主要方便对齐,只要padding = 0、1、2,就可以得到相同大小的特征图,可以顺利concat。
- 采用大小不同的卷积核,意味可以得到不同尺度的特征。
- 采用比较大的卷积核即5*5,因为有些相关性可能隔的比较远,用大的卷积核才能学到此特征。
但是这个结构有个缺点,5*5的卷积核的计算量太大。那么作者想到了第二个结构,用1*1的卷积核进行降维。
这个1*1的卷积核,它的作用就是:
- 降低维度,减少计算瓶颈
- 增加网络层数,提高网络的表达能力
那么在具体的卷积神经网络中,Inception应该放在哪里,作者的建议,在底层保持传统卷积不变,在高层使用Inception结构。
3. Inception作用
Inception的作用就是替代了人工确定卷积层中过滤器的类型或者是否创建卷积层和池化层,让网络自己学习它具体需要什么参数。这样不仅自动选择了卷积层,还通过不同的卷积层的concat得到了不同尺度的特征。
七. 应用:目标检测
1. 基础
Object localization 目标定位
Landmark detection 特征点检测
Bounding Box边框
YOLO(You Only Look Once)算法
图片分类的卷积模型,输入要目标检测的图片,用基于滑动窗口的目标检测(Sliding Windows Detection)来获得结果。前提是将fc层转换为卷积层
2. IoU
计算预测边框和实际边框交集(I)与并集(U)之比:
IoU 的值在 0~1 之间,且越接近 1 表示目标的定位越准确。IoU 大于等于 0.5 时,一般可以认为预测边框是正确的,当然也可以更加严格地要求一个更高的阈值。
3. 非最大值抑制
非极大值抑制(Non-max Suppression)会通过清理检测结果,找到每个目标中点所位于的网格,确保算法对每个目标只检测一次。
进行非极大值抑制的步骤如下:
- 将包含目标中心坐标的可信度 PcPc 小于阈值(例如 0.6)的网格丢弃;
- 选取拥有最大 PcPc 的网格;
- 分别计算该网格和其他所有网格的 IoU,将 IoU 超过预设阈值的网格丢弃;
- 重复第 2~3 步,直到不存在未处理的网格。
上述步骤适用于单类别目标检测。进行多个类别目标检测时,对于每个类别,应该单独做一次非极大值抑制。
4. anchor box
进行多目标检测时,图像中的目标则被分配到了包含该目标中点的那个网格以及具有最高 IoU 值的该网格的 Anchor Box。