1、深度优先的查询
图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点A出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和a有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
显然,深度优先搜索是一个递归的过程。
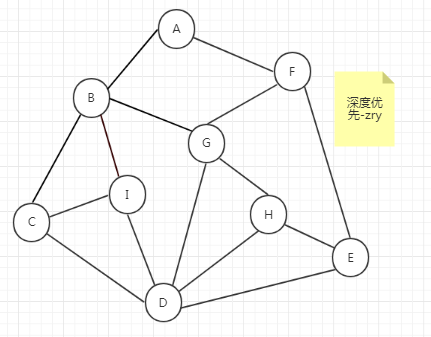
转化为树的结构:


2、总结
深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历(我们前面使用的是先序遍历)。具体说明如下:
先序遍历:对任一子树,先访问根,然后遍历其左子树,最后遍历其右子树。
中序遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树。
后序遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
3、分析
深度优先搜素算法:不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
通常深度优先搜索法不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。
所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
