分类变量的处理
编码方式:
>> one-hot编码
>> 虚拟编码:one-hot编码对于k类别的变量编辑一个长度为k的特征向量,实际上自由变量只有k-1个。虚拟编码对于k类别的变量编辑一个长度为k-1的特征向量,使得编码更具有解释性
>> 效果编码:与虚拟编码类似,区别在于参照类由全部由-1的向量表示,示例如下所示:

存在的问题:
one-hot编码有冗余(特征向量线性相关带来的影响),使得同一个问题有多个有效的模型,这种非唯一性有时候比较难以解释。
虚拟编码可以生成唯一解释的模型,但是不容易处理缺失数据,因为全零向量以及默认为参照类。
效果编码能处理缺失数据,但是全-1组成的向量是个密集向量,不易于计算与存储。
当类别的数量变得非常大的时候,三种编码的方式都会出现问题。
处理大型分类变量
>> 特征散列化 。散列函数是一种确定性函数(类似于哈希的操作),将一个可能无界的整数映射到一个有限的整数范围 [1, m] 中。因为输入域可能大于输出范围,所以可能有多个值被映射为同样的输出,这称为碰撞。均匀散列函数可以确保将大致相同数量的数值映射到 m 个分箱中。特征散列化可以添加正负号,这样可以确保散列后特征之间的内积等于初始特征内积的期望。散列后的内积是初始内积的$O(frac{1}{sqrt{m}})$,通常需要根据误差能够接受的程度来选择m的大小。特征散列化对计算能力大有裨益,但牺牲了直观的用户可解释性。
>> 分箱计数。不使用分类变量的值作为特征,使用目标变量去这个值的条件概率作为特征。除了历史点击率之外,对数优势比也是一个不错的特征。


假设有 10 000 个用户,one-hot 编码会生成一个长度为 10 000 的稀疏向量,只在对应当前 数据点的列上有一个 1。分箱计数会将所有 10 000 个二值列编码为一个单独的特征,是 0 和 1 之间的一个实数值。简而言之,分箱计数将一个分类变量转换为与其值相关的统计量,它可以将一个大型的、 稀疏的、二值的分类变量表示(如 one-hot 编码生成的结果)转换为一个小巧的、密集的、 实数型的数值表示。(也就是将一个分类变量中的所有取值转为[0,1]之间的概率值,也即是上文中提到的统计量,能够比较轻巧的表示特征)
如何解决稀有类:在预测广告点击率问题中,设想一个一年只登录一次的用户:只有极少的数 据能用来可靠地估计这个用户的广告点击率。
>>back-off,这是一种将所有稀有类的计数累加到一个特殊分箱中的简单技术,如果类别的计数大于一个确定的阈值,那么就使用它自己的 计数统计量;否则,就使用 back-off 分箱的统计量。示例图如下所示:
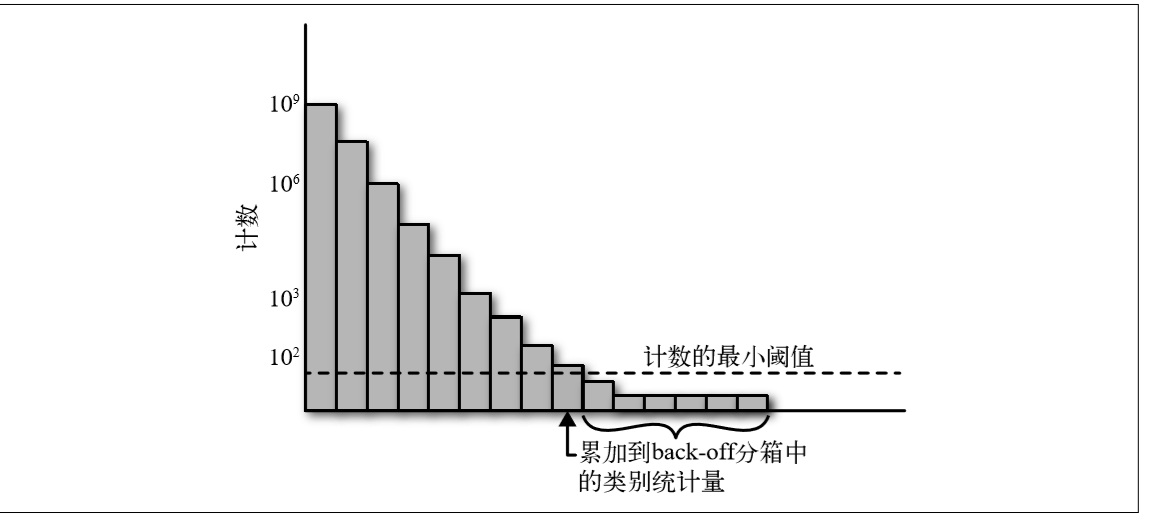
>>最小计数图。不论稀有类还是频繁类,所有类别都通过多个散列函数进行映射,每个散列函数的输出范围m都远远小于类别数量k。在计算统计量时,需要使用所有散列函数进行 计算,并返回结果中最小的那个统计量。这种方法的有效之处在于,散列函数的数量乘以散列表大小 m 之后,不但 可以小于类别数量 k,而且能保持非常低的碰撞概率。
防止数据泄露
数据泄露会使模型中包含一些不应该有的信息(包含输出信息的输入),这些信息会使模型获得某种不现实的优势(比如以及知道结果的考试)。如果在分箱计数过程中使用当前数据点的标签来计算输入统计量,就会造成直接的数据泄露。解决这个问题的第一个方法是严格的隔离计数收集的数据以及训练使用的数据,使用过去的数据点进行计数,使用当前的数据点进行训 练(将分类变量映射到我们前面收集到的历史统计量上),再使用未来的数据点进行测试。 这可以解决数据泄露问题,但会引发前面提过的流程延迟问题(输入统计量以及模型会滞 后于当前数据)。(利用时间窗口来合理的划分各个数据)另一个解决方法是使用Laplace(0,1) 分布添加 一个小的随机噪声,就足以弥补任何来自单数据点的潜在泄露。这种思想可以和留一计数 方法结合起来,构成用于当前数据的统计量。
无界计数
当提供的历史数据越来越多的时候,计数就会无限增长。一般的处理方式是进行归一化处理或者是强加一个计数的边界。这两种方法都不能够保证输入的分布保持不变(例如,去年的芭比娃娃已经过时了,人们不会 再点击那些广告)。需要对模型进行维护,以适应输入数据分布中这些更加基本的改变, 或者将整个流程转换为在线学习模式,使得模型能持续地适应输入变化。
小结:


