transformers较为知名的应用是BERT,Transformers可以看成是seq2seq model,特点在于this model leverages mass “self-attention” layers,seq2seq在What-is-seq2seq篇已经解释过,接下来将对`self-attention`进行描述
注:本片博客是看李宏毅老师教学视频后的课程笔记
一、Sequence
对一个句子,之前多是使用RNN(Recurrent Neural Network)进行single direction or bidirection 处理,但是RNN的计算不容易并行化,如下图1中所示:
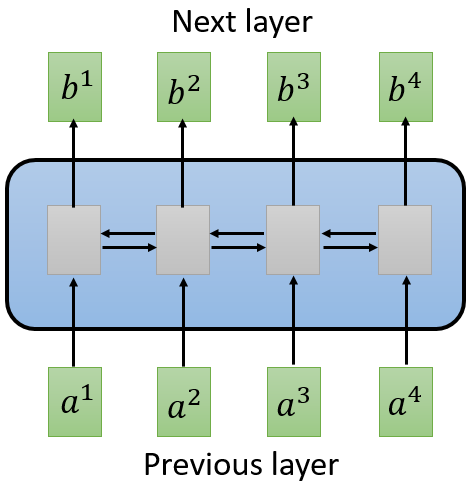
图 1 RNN model
当为单向时,已知b1,b2才可得b2;已知b1,b2,b3才可得b3,也就是说,如果是双向,它需要看完整条sequence。用CNN去解决这个问题时,如下图2所示,图中:
Step1. 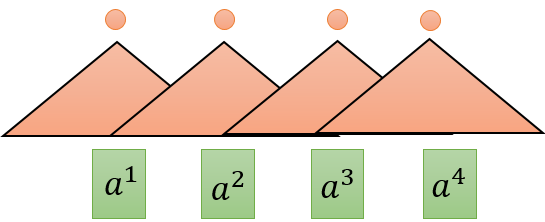
Step2.
图 2 CNN model
filter(橙色三角形,CNN中的概念),filter与step选取的subsequent进行inner product 得出一个数值(橙色圆形表示),filters in higher layer can consider longer sequence
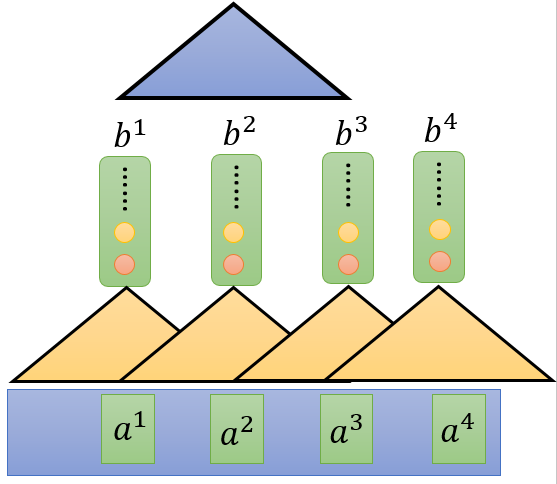
图 3 CNN model layers
也就是对于一个长句子,它需要很多层的叠加,才能看完整个句子,有点耗时耗力。
二、self-attention
基于上述的研究过程及其问题,self-attention目的做到rnn做到的,所以self-attention layer 的output和input和rnn是一样的输入一个sequence,输出another sequence,首次在`https://arxiv.org/abs/1706.03762`中提出的。
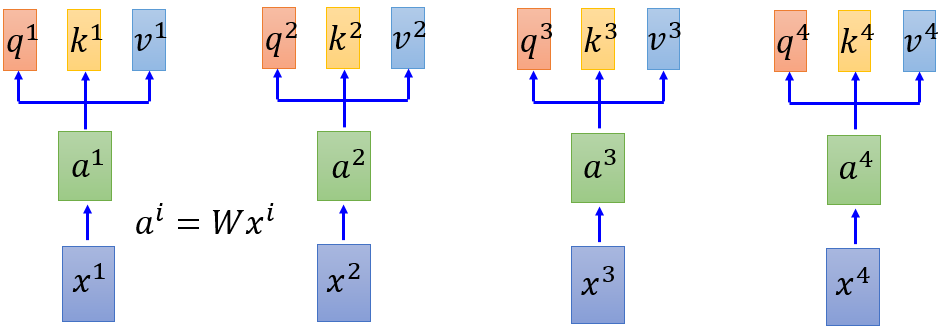
图 4 self-attention(a)

Step1. 每个query q 去对每个key k 做attention (attention的作用是对所输入的向量计算其相似度,output a score )
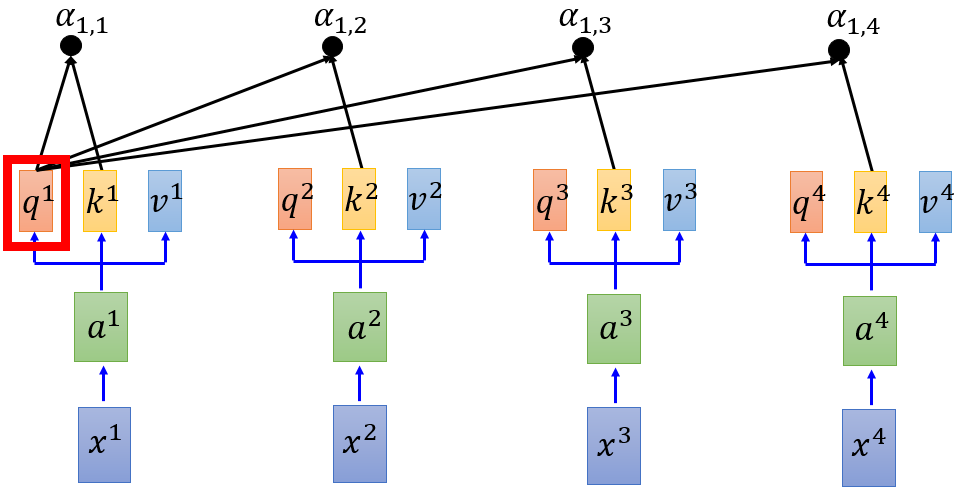
这里使用 Scaled Dot-Product Attention :$ a_{1,i}= frac{q^1*k^i}{sqrt{d}}$ ,其中d是和q,k的dimension。
Step2. soft-max
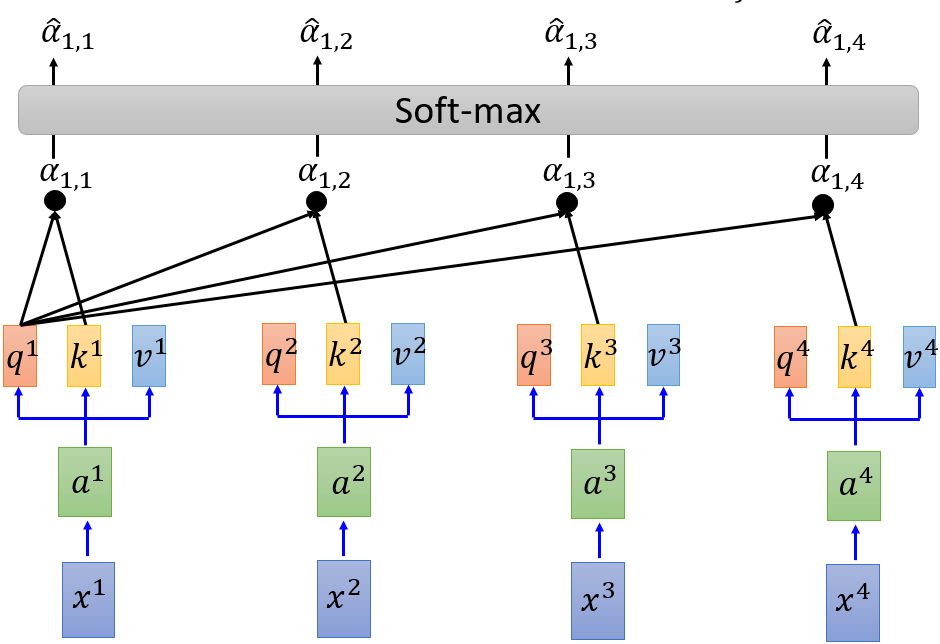
图 5 self-attention(b)
其中,$ hat{a}_{1,i}= frac{exp(a_{1,i})}{sum_{j}exp(a_{1,j})}$
Step3. key k
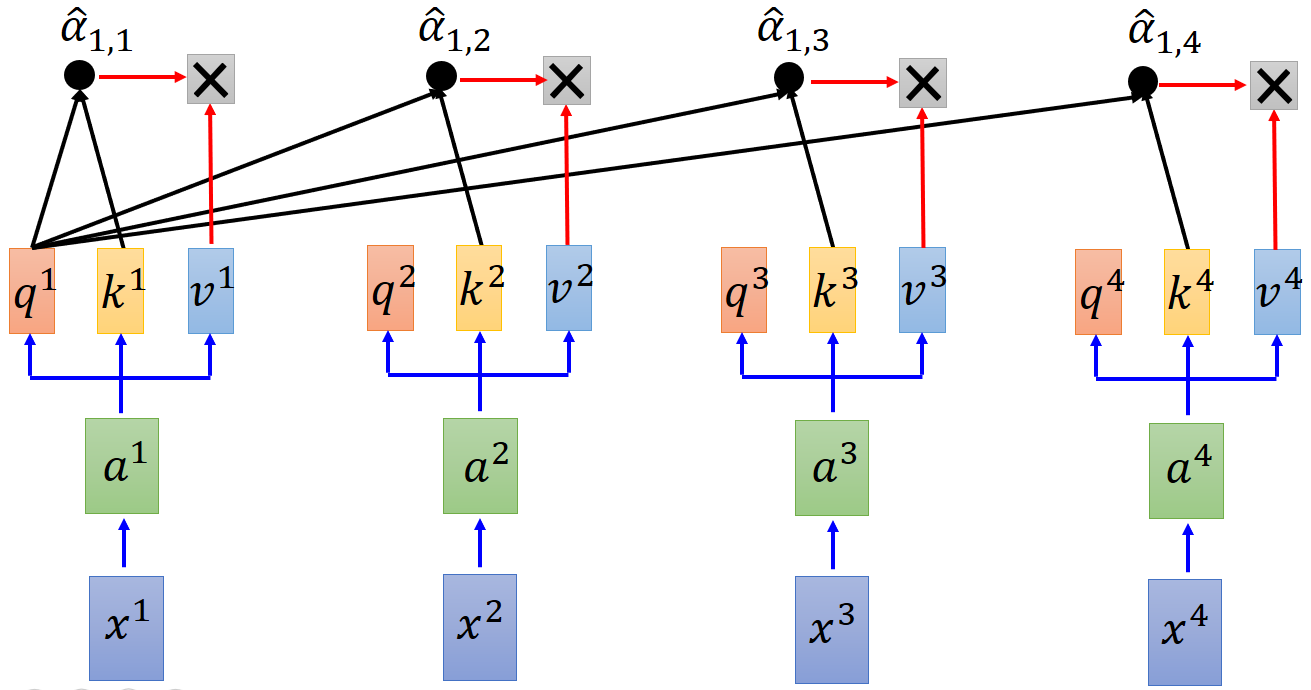
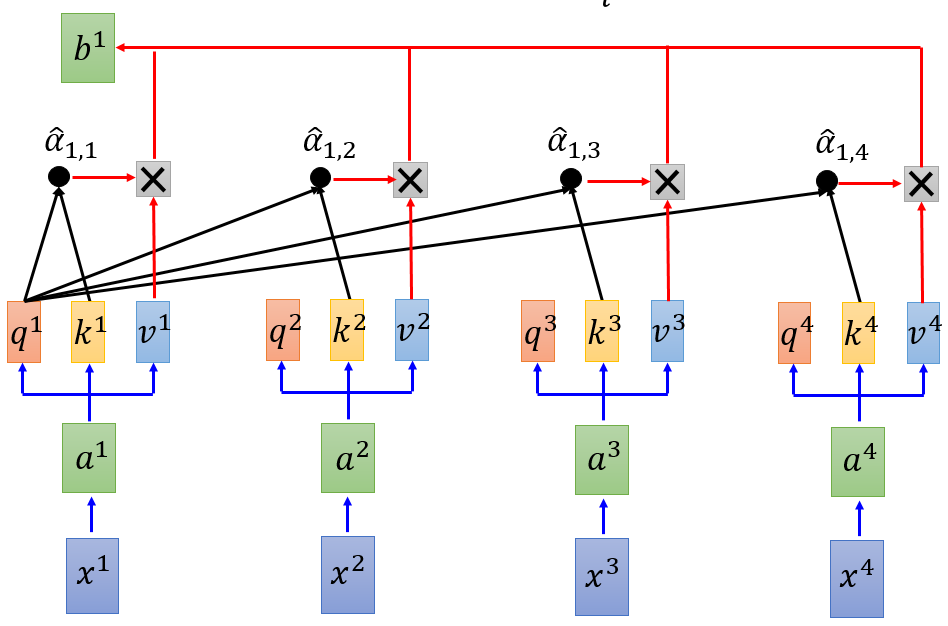
图 6 self-attention(c)
其中,$$ b^{1}=sum_{i}hat{a}_{1,i}v^i $$,$b^1$considers the whole sequence,$v^i$的值是由$a^i$transformation而来,如果要考虑某个$a^i$,只需调整$ hat{a}_{1,i} $
同理,并行计算$b^{2}$,$b^{3}$,$b^{4}$,...,$b^{n}$同样平行计算
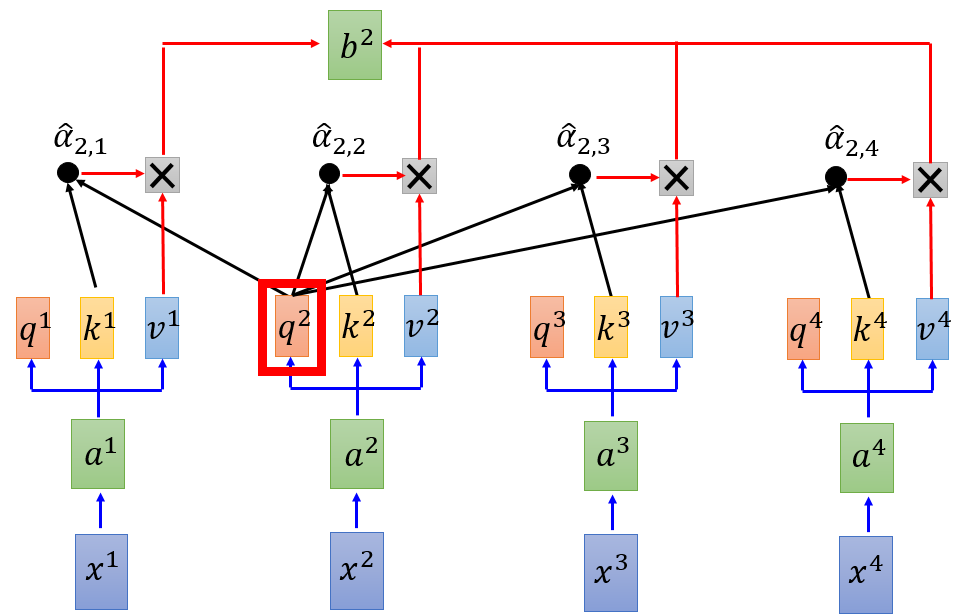
图 7 平行化计算(a)
可能上述中平行化还不是很明显,以下面形式表达更为明了
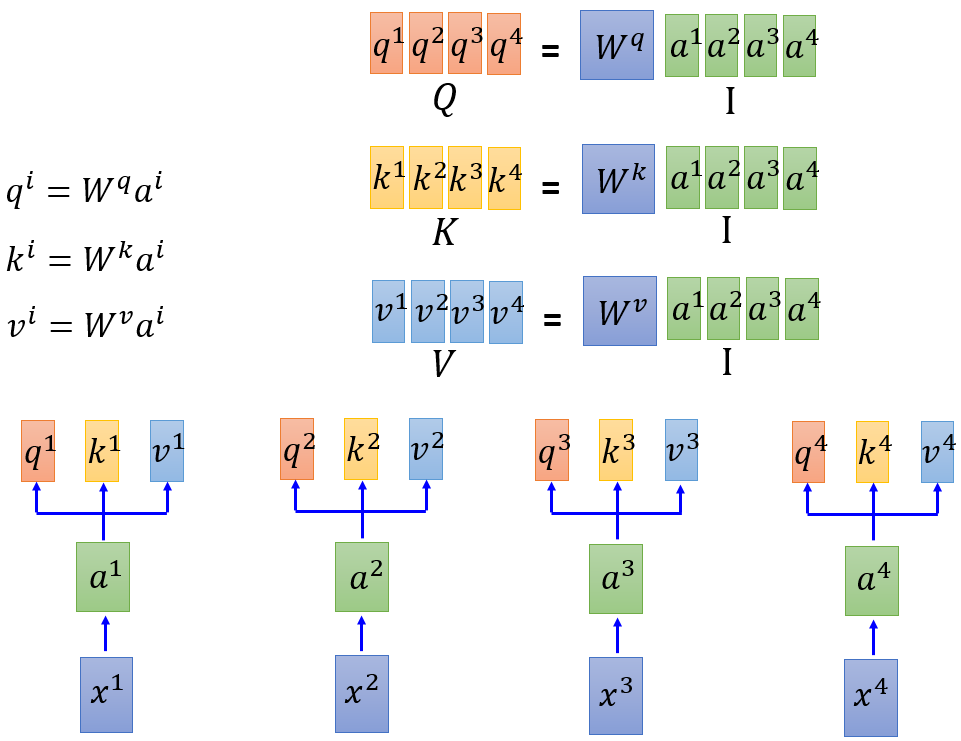

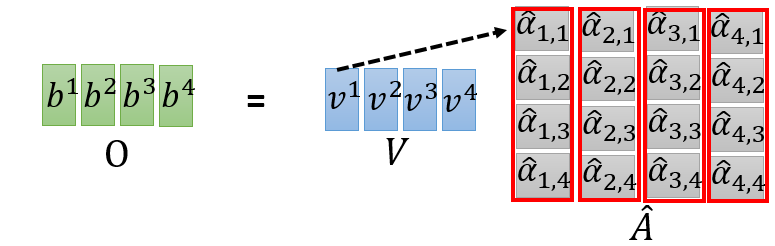
图 8 平行化计算(b)
那么整个self attention过程就可以简化为(GPU可以加速矩阵乘法):
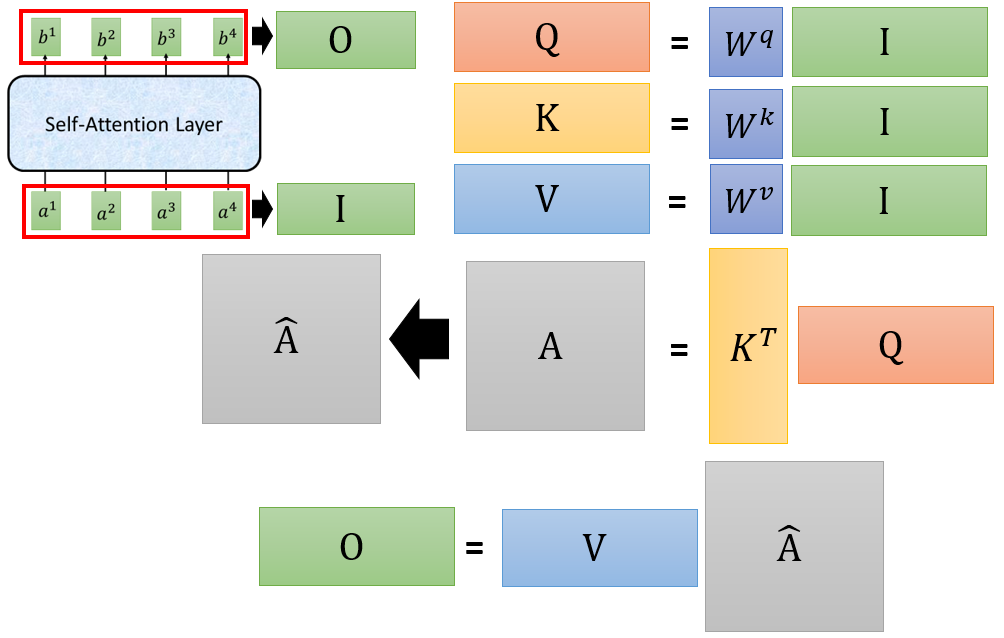
图 9 平行化计算(c)
三、Multi-head self-attention
self attention的变形--Multi-head self attention,以2 heads 为例
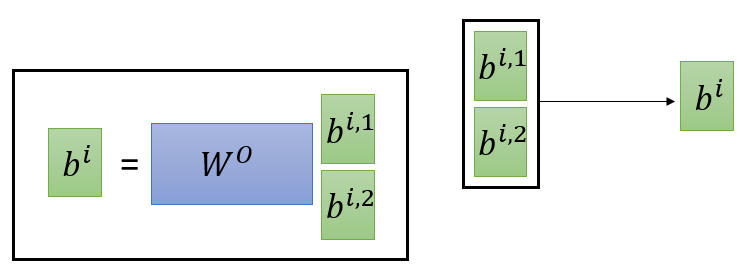
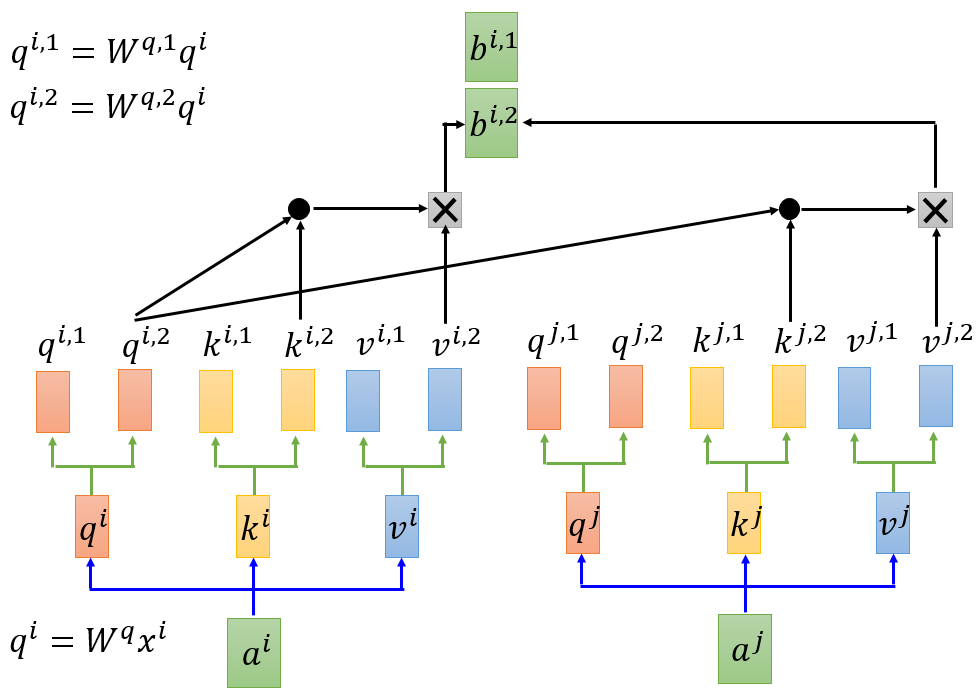
图 10 Multi-head
$W^{0}$在降维中使用,因为$b^{i,1}$和$b^{i,2}$的连接
四、Positional Encoding
在self attention中,么有位置信息,原始paper中是手动s设置position information $e^i$
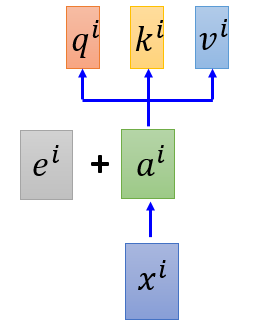
图 11 位置信息(a)
这里关于“+”,可以理解成,在each $x^i$ 后appends a one-hot vector $p^i$,$p^i$中记录了位置信息
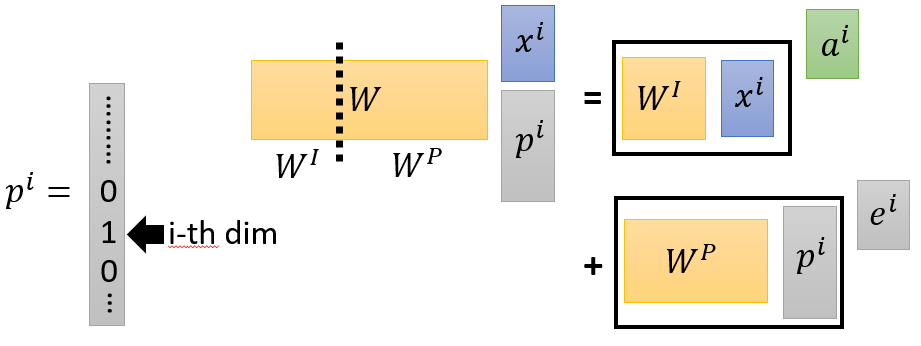
图 12 位置信息(b)
$W^p$为公式计算所得,它的含义如下所示,图意不理解
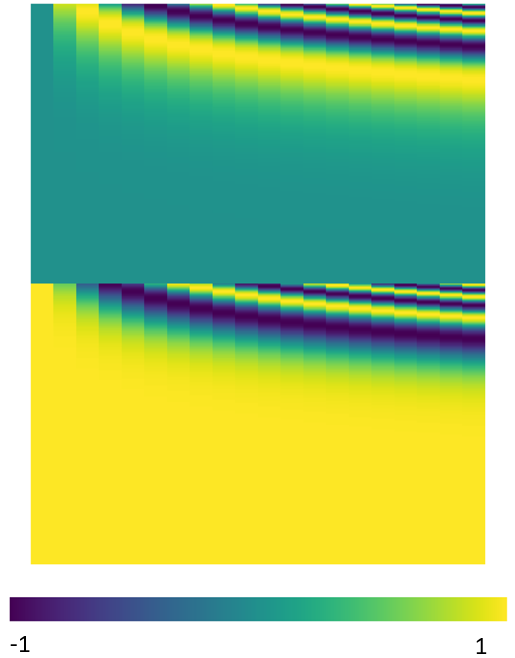
五、Seq2seq with Attention
一般的Seq2seq model是用RNN做的,如果结合attention则是这样的效果,[google提供了可视化效果展示](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
)
六、transformers 架构图
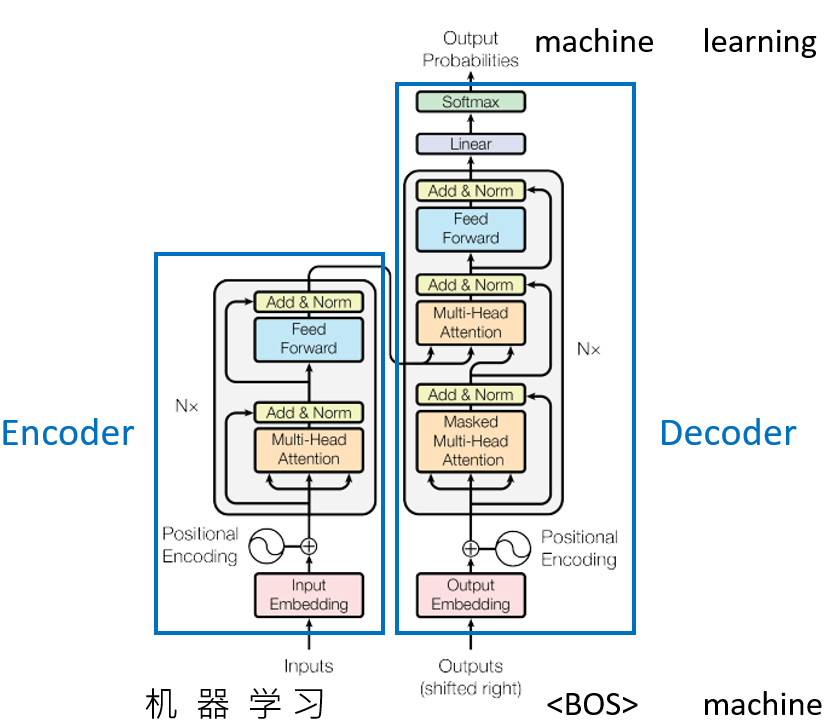
这个图实际为Seq2seq model,以中译英为例(机器学习--> machine learning),对这个图更为详细的解释便是:
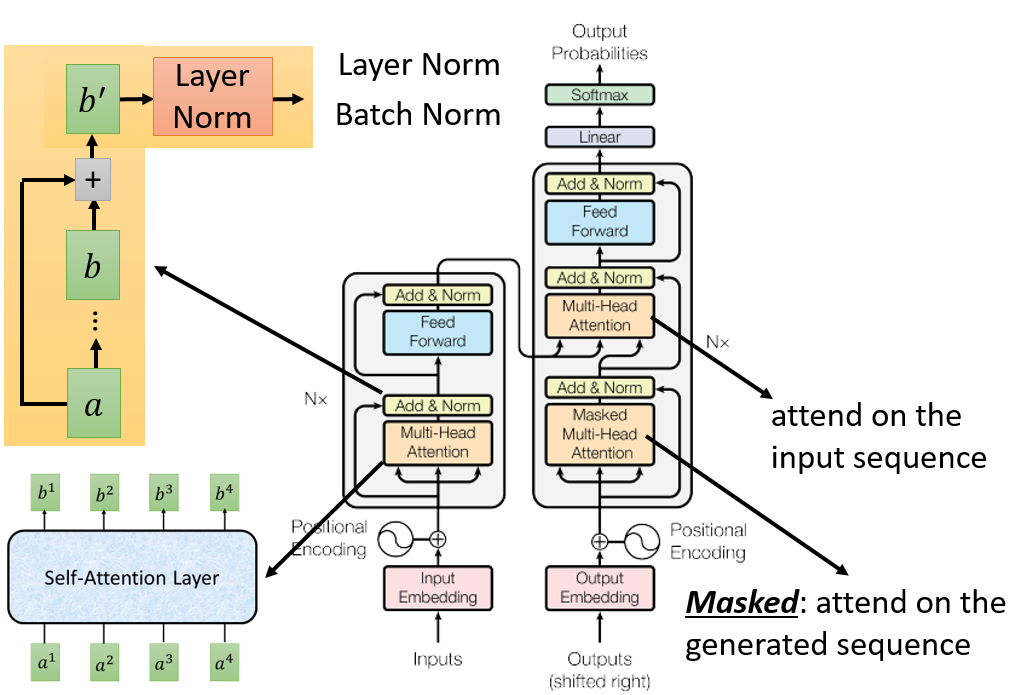
`Add & Norm` 意为将raw input和产生的input加起来,然后做Norm。Norm有Layer Norm(https://arxiv.org/abs/1607.06450)和Batch Norm(https://www.youtube.com/watch?v=BZh1ltr5Rkg),至于其中的Masked是只attend on the generated sequence,以最近的timestep和已翻译出来的最为下一次词翻译的参考依照。