写这个编译器的目的,是为了完成编译原理课上老师布置的大作业,实际上该大作业并不是真的实现一个编译器,而我选择硬刚,是为了完成我的小愿望--手写内核,编译器和CPU。我花了整个上半学期,写完了WeiOS,为了让它支持更多的用户态程序,甚至是基本的程序开发,必须给它量身打造一个编译器。于是这个编译器被提上日程。
因为我要复习考研和专业课过多,我打消了手写词法分析和语法分析的念头,转而使用FLEX和YACC,等到有时间再完成手工的版本--我认为也不是很难,如果用递归下降的话。
全部代码都在该处 https://github.com/mynamevhinf/CMinusCompiler
词法分析
因为是精简的C语言,所以只支持基本的符号(Token),像”++”, “--”和位操作都不予考虑。另外,只支持int和void类型。于是便构成了以下符号集:
number [1-9][0-9]*
letter [a-zA-Z]
Identifier {letter}({letter}|{number})*
Newline
whitespace [ ]+
保留字:
If else while int void return
运算和界限符号:
<= >= != == + - * / < > ; , ( ) { } [ ]
主体函数是getToken(),这个函数封装了FLEX原生的yylex函数。而yyparser也将直接调用该函数。它的主要工作是在开始第一次词的检索前,初始化相关变量。然后在每次被调用的时候,返回符号的类型给yyparser,并且把构成符号的字符串临时保存在tokenString字符数组中。所以这函数相当于什么事情都没有干。
另外注意的是注释的两个符号,我直接在词法分析处理注释了。行注释是”//”,利用FLEX自带的input()函数(如果有的话,没有就写一个)一直读到’ ’出现。然后就是段注释符”/*”和”*/”,相似的做法。
语法分析
以下是BNF格式的语法规则:
Program -> declaration_list
declaration_list -> declaration_list declaration | declaration
declaration -> var_declaration | func_declaration
type_specifier -> INT | VOID
var_declaration -> type_specifier VARIABLE ; | type_specifier VARIABLE [ NUM ] ;
func_declaration -> type_specifier VARIABLE ( params ) compound_stmt
Params -> params_list | VOID
params_list -> params_list , param | param
Param -> type_specifier VARIABLE | type_specifier VARIABLE [ ]
compound_stmt -> { local_declarations stmt_list }
local_declarations -> local_declarations var_declaration | /* empty */
stmt_list ->stmt_list stmt | stmt
Stmt -> expr_stmt | if_stmt | return_stmt | compound_stmt | iteration_stmt
expr_stmt -> expr ; | ;
if_stmt ->IF ( expr ) stmt | IF ( expr ) stmt ELSE stmt
iteration_stmt -> WHILE ( expr ) stmt
return_stmt ->RET ; | RET expr ;
Expr -> var = expr | simple_expr
Var -> VARIABLE | VARIABLE [ NUM ]
Call -> VARIABLE ( args )
Args -> arg_list | /* empty */
arg_list -> arg_list , expr | expr
simple_expr -> NUM | var | call | ( expr ) | - simple_expr
| simple_expr + simple_expr
| simple_expr - simple_expr
| simple_expr * simple_expr
| simple_expr / simple_expr
| simple_expr < simple_expr
| simple_expr > simple_expr
| simple_expr >=simple_expr
| simple_expr <= simple_expr
| simple_expr != simple_expr
| simple_expr == simple_expr
我用globl.h中的TreeNode结构来保存语法树中的每一个节点。而一些为空的转换,我打算还是用一个该结构来表示,但是类型标记为None(也许有点浪费内存).
我实现的C-还算是个比较完整的程序语言,所以很有必要生成AST(抽象语法树),那么语法树中共有几种类型的节点呢?按理说应每种语法规则对应一种类型,例如参数列表,声明语句,普通语句和表达式等都对应一个节点类型,详细可以参见NodeType枚举类型。Parser.c文件是处理与语法树相关的函数,目前来说当中几个函数还没写清楚,TreeNode需要大改一下我估计,过几天也许就明了了。--2018/05/29
2018/05/30
没想到只过了一天不到,就完成了语法分析部分,总体上来说还是很简单的。
有些语法规则导出两种相似的子规则,用专业术语来讲就是就是要做左因子消除,但好像yacc已经代替我们做了这个工作--我猜测它在底下优化了我们混乱的语法规则,包括左递归也解决了。据来说就是if_stmt导出的两种情况,我并不打算在StmtType枚举中添加新的枚举类型来处理,而是利用原有的结构,用nkids来辨别是哪种情况。而在处理var_declaration第二种导出的规则时,原有的结构不够用了,因为我要存储VARIABLE和NUM,很显然一个attr联合体不够用,所以我引入了第二个联合体分别来存储两个值。分别叫attrA和attrB。有些时候这样做也无法解决结构上的问题,才不得不用两个枚举类型来解决。现在我也不确定这样做是否多余,毕竟我也是第一次写编译器,但它确实解决了当下的问题。
我删除了封装yylex()的getToken()函数,并解决了注释代码的问题,现在可以支持/**/的段注释和//行注释了。另外,我不想让我代码变得冗余,所以我把构建符号表(Symbol table)的任务放在了语义分析,直接放在语法分析中虽然节约了时间,但实在是难以维护。
最后根目录下source*.c都成功地进行了语法分析,可能也只是表面上...
语义分析还没学,翻书去了...
2018/06/02
经过两天的学习,我知道了符号表基本的构建方式和运行时环境的搭建。但是还来不及完全转换成代码。今天我抽了一点时间写了符号表的管理函数。我的编译器有多级符号表:一个全局符号表以及每个函数一个局部符号表。在全局符号表中,每个属于函数的变量名,都有一个指针指向其局部符号表。而局部符号表通过Parent字段与父符号表相连,在当前符号表无法检索到符号信息的时候,就会去搜寻父符号表,层层递增。由于C语言本身的规定,和我的懒惰,我不支持动态作用域,也就是说对一切外部(相对与当前代码块)的符号引用而言,其偏移和效果都是固定的;也不支持函数声明嵌套,也就是说对于任何局部符号表,其父符号表都指向全局符号表。因此我觉得这样简单的实现方式是可行的。
符号表的基本数据结构是哈希表。具体实现不做阐述,我只写了插入和寻找的函数,因为这个烂编译器暂时不支持类型声明和类型别名,所以我没有写删除。
这里留下一个问题,除了全局声明函数,代码块--也就是被{}包围起来的部分,也需要局部符号表,而且是支持嵌套的。那么我该如何解决这种相当于“匿名”函数的符号表问题,我还没有思路。或许可以给它们各自赋予决不会引起冲突的名字?又或者是留到代码生成阶段再处理,这样就不必缓存“匿名”符号表了,直接生成代码就完事了。
主要代码都在symbol.c 和 symbol.h里面。
2018/06/07
经过几天的咸鱼和跟进,我完成了类型检查和符号表生成,中间代码生成。
关于类型检查,是完全仿造gcc的,检查顺序是后序遍历,例如表达式:
a = test() + b;
我们必须先检查test()是否有返回值,然后b是什么类型的数据,如果test()返回值是void,那么这个语句就可以直接判断为错误了。若两个加数通过检查,而a是数组类型的话,也会报错。
由上所述,类型检查必须是后序遍历,而我生成符号表的时候采取先序遍历,这里就产生了矛盾。解决的方法是,我对语法树中的表达式(expr)类型的节点,通通执行后续遍历,而其他如If语句,while语句等采取常规做法。原因是我在表达式的语句中,不可能出现声明新函数或者变量的语句,反而是要检查所用的变量和函数在之前是否声明,如果没有就报错,因此后序遍历是可行的。
也就是说我的buildSymtab()函数不是安装树状递归展开的,而且名不副实,因为它除开生成符号表,还同时完成了类型检查工作。其实我是想把这两个步骤分开的,用2-pass来完成,代码也比较精简,想砍掉哪部分也很方便。但由于当时写的太爽了,不想再写类似于buildSymtab()这样结构的函数了,所以直接做完了。
上一篇遗留的问题,匿名代码块怎么办?我的处理方法是为它们生成单独的符号表,并且在语法分析阶段,调用randomFuncName()函数为每一个匿名代码块生成一个名字,类似真正的函数那样管理,这个名字不是真正随机的,因为它是AAAnonymous*的形式,但无所谓了,反正这编译器也烂。
具体的代码在analyzer.c里,相关结构的定义在analyzer.h中。
接下来是一张类型检查的贴图: 左边是我的fcc,右边是gcc,错误和警告都检测出来了,但是他们比我提示信息更加多...

运行时环境(run-time):
当然是选择和C语言一样啊,没有什么好说的。
要提的一点还是匿名代码块的问题,对于这种代码块中声明和定义的“局部变量”,我观察了gcc的做法,他们把这些“局部变量”当作了其所属的函数的局部变量,举个例子:
void test()
{
int j;
{
int i;
}
}
那么在函数test()为局部变量分配空间的时候,不是分配4个字节,而是8个字节。所以我也这么干。因为语法的原因,函数体本身声明局部变量肯定在匿名代码块之前,故当我们处理到匿名代码块的时候,必须要返回去更改所属函数的局部变量信息(用于代码生辰的时候分配具体空间)。之前我的FuncProperty结构并没有维护参数个数和局部变量大小的信息,所以我做了一些更改,添加了nparams和nlocalv域。
中间代码
本来我都不打算写中间代码,直接生成x86的汇编代码,但老师说不给我分,我就写了。然后我看了一下vsl的中间代码,我很郁闷遂决定自己创造一套新的三地址码,我觉得还挺有意思的,我甚至都考虑用这套三地址码写一个虚拟机,直接在虚拟机上面跑。。。
折中了一下,我的这套三地址码已经非常像x86的汇编代码了,除了一些没用的临时寄存器。其对于我来说,最大的作用就是把树形的信息,转换成了链状的,接下来顺着三地址码构成的链表翻译就好了。相关代码见irgen.c而数据结构等在irgen.h.下面是一个源代码文件(source2.c)以及其生成的三地址码(midcode.f)的部分。
source2.c:
int jb; int x[10]; /* void test(void) { } */ int minloc(int a[], int low, int high) { int i; int x; int k; k = low; x = a[low]; i = low + i; /* k = a; ok = 10; i = a[test()]; */ while (i < high) { if (a[i] < x) { x = a[i]; k = i; } i = i + 1; } return k; } void sort(int a[], int low, int high) { int i; int k;
midcode.f:
1 program: 2 glob_var jb 4 3 glob_var x 40 4 5 _minloc: 6 loc_var 16 7 k = low 8 mull t0 low 4 9 addl t1 &a t0 10 x = t1 11 addl t2 low i 12 i = t2 13 L0: 14 lt t3 i high 15 if_false t3 goto L1 16 mull t4 i 4 17 addl t5 &a t4 18 lt t6 t5 x 19 if_false t6 goto L2 20 mull t7 i 4 21 addl t8 &a t7 22 x = t8 23 k = i 24 L2: 25 addl t9 i 1 26 i = t9 27 goto L0 28 L1: 29 ret k 30 31 _sort: 32 loc_var 16 33 i = low 34 L3: 35 subl t10 high 1 36 lt t11 i t10 37 if_false t11 goto L4 38 loc_var 16 39 begin_args
可以看到真的是一一对应的,虽然还有个小Bug,但是我懒得管了。
2018/06/11
我的寄存器分配函数写得有点混乱,当然如果我不想做那些奇奇怪怪的优化,就不会存在这个问题。我写得很难受,但也比较享受。我现在是考虑把对中间变量的处理也统一起来,但是还没有思路...
isReside():判断一个地址是否驻留在寄存器中,如果该地址类型为TempPtr或TempReg,
regWriteBack(RegPtr Rp, RegPtr Rbp,FILE *fp): 把Rp寄存器的内容写会所属变量的内存地址。一定要先判断Hp是否为空,若为空就表示当前存了一个中间变量!!!! 如果不为空,但是没被修改过--就是dirty为0,也没必要写回去!!!
regReadIn(RegPtr Address *addr, FILE *fp): 把地址addr所属的变量的值读到到Rp指向的寄存器中,并更新相关内容.如果该变量/中间变量已存在寄存器中,则调用regMoveReg()直接从原寄存器移动.如果不在,则根据addr的类型采取不同的操作.我暂时处理了一般变量和常数的读取。
regBindVar(RegPtr Rp, Address *addr, HashList Hp, int dirty):如函数名,把addr,Hp,dirty赋给寄存器Rp.函数体内检测是否有其他寄存器已保存了该变量,调用FreeReg()把其addr和Hp域清空.
RegPtr regSearchOne(HashList Hp, FILE *fp):为第一个操作数搜寻合适的寄存器.我判断的是addr这个域,但感觉好像不够圆满...
2018/06/14
懒得写了,终于完成了代码生成,我自己写的那套寄存器分配,也很好用,甚至超过了vsl作者们写的算法= =
但是遗留了一个问题,就是我在代码生成的时候,忘记考虑到代码重入性的问题了,在生成循环代码块的时候,根据前文的数据流生成了代码,本意是尽量减少内存存取的次数,但是我没有考虑到,在真正运行的过程中,每次循环开始的时候,寄存器中存储的信息不一定是“第一次"进入循环块时的信息,因此我生成的代码有语义错误,只有偶尔情况下才是正确的。我不打算改这个bug了,老师说这个涉及到龙书上讲解的数据流分析,但我还要考研,所以推迟了吧,等真正需要的时候再搞这个。
下面是测试代码,就是一个简单的选择排序 source2.c
/* A program to perform selection sort on a 10
element array. */
/*
void test(void)
{
}
*/
int minloc(int a[], int low, int high)
{
int i; int x; int k;
k = low;
x = a[low];
i = low + i;
while (i < high) {
if (a[i] < x) {
x = a[i];
k = i;
}
i = i + 1;
}
return k;
}
void sort(int a[], int low, int high)
{
int i;
int k;
i = low;
while (i < high - 1) {
int t;
k = minloc(a, i, high);
t = a[k];
a[k] = a[i];
a[i] = t;
i = i + 1;
}
}
我生成的汇编代码 source2.s:
.file "testfile/source2.c" .text .globl minloc .type minloc, @function minloc: pushl %ebp movl %esp, %ebp subl $16, %esp movl 12(%ebp), %eax movl %eax, -12(%ebp) movl 12(%ebp), %edx leal 0(,%edx,4), %ebx movl 8(%ebp), %ecx addl %ecx, %ebx movl (%ebx), %ebx movl %ebx, -8(%ebp) movl -4(%ebp), %eax addl %eax, %edx movl %edx, -4(%ebp) .L0: cmpl 16(%ebp), %edx jge .L1 leal 0(,%edx,4), %eax addl %ecx, %eax movl (%eax), %eax cmpl -8(%ebp), %eax jge .L2 leal 0(,%edx,4), %ebx addl %ecx, %ebx movl (%ebx), %ebx movl %ebx, -8(%ebp) movl %edx, -12(%ebp) .L2: movl -4(%ebp), %edx addl $1, %edx movl %edx, -4(%ebp) jmp .L0 .L1: movl -12(%ebp), %eax leave ret .globl sort .type sort, @function sort: pushl %ebp movl %esp, %ebp subl $16, %esp movl 12(%ebp), %eax movl %eax, -4(%ebp) .L3: movl 16(%ebp), %edx subl $1, %edx cmpl %edx, %eax jge .L4 movl 16(%ebp), %ebx pushl %ebx pushl %eax movl 8(%ebp), %ecx pushl %ecx call minloc addl $12, %esp movl %eax, -8(%ebp) leal 0(,%eax,4), %edx addl %ecx, %edx movl (%edx), %edx movl %edx, -12(%ebp) movl -4(%ebp), %eax leal 0(,%eax,4), %edx addl %ecx, %edx movl -8(%ebp), %eax leal 0(,%eax,4), %ebx addl %ecx, %ebx movl (%edx), %edx movl %edx, (%ebx) movl -4(%ebp), %eax leal 0(,%eax,4), %ecx movl 8(%ebp), %eax addl %eax, %ecx movl -12(%ebp), %eax movl %eax, (%ecx) movl -4(%ebp), %eax addl $1, %eax movl %eax, -4(%ebp) jmp .L3 .L4: leave ret
最后上测试结果,难得的正确了一次:
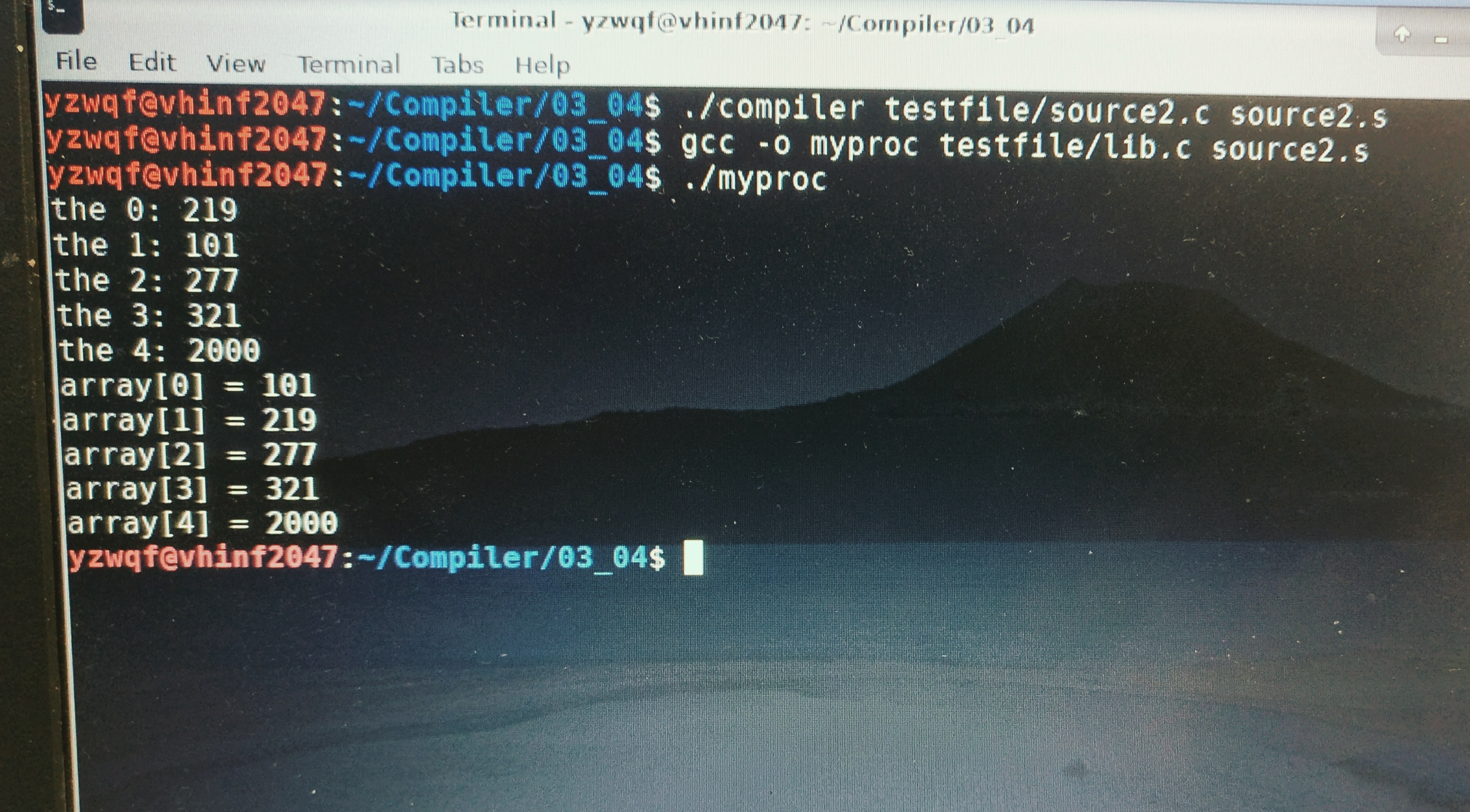
2018/06/24
本来不打算写了,但是在满分的激励下我做了以下修改,并最终解决了上面的Bug
1.被调用函数保存可能改变的所有寄存器。
2.实现循环代码的语义正确(其实就是保证了可重入性)。
当然还有一个问题就是,栈内容初始化。因为物理页面分配的不确定性,因此会留下上一个进程的数据,所以必须在程序一开始对可能用到的栈空间进行初始化。严格来说,这并不是我的问题。
最后附上一张成功运行的图:
