一、scrapy选择器
1.使用Xshell工具命令窗口中测试选择器(不用连接远程ip,直接在本地输入以下命令即可)
1 scrapy shell https://www.toutiao.com/
2.接着,当shell载入后,您将获得名为 response 的shell变量,其为响应的response, 并且在其 response.selector 属性上绑定了一个selector。
官方文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/selectors.html

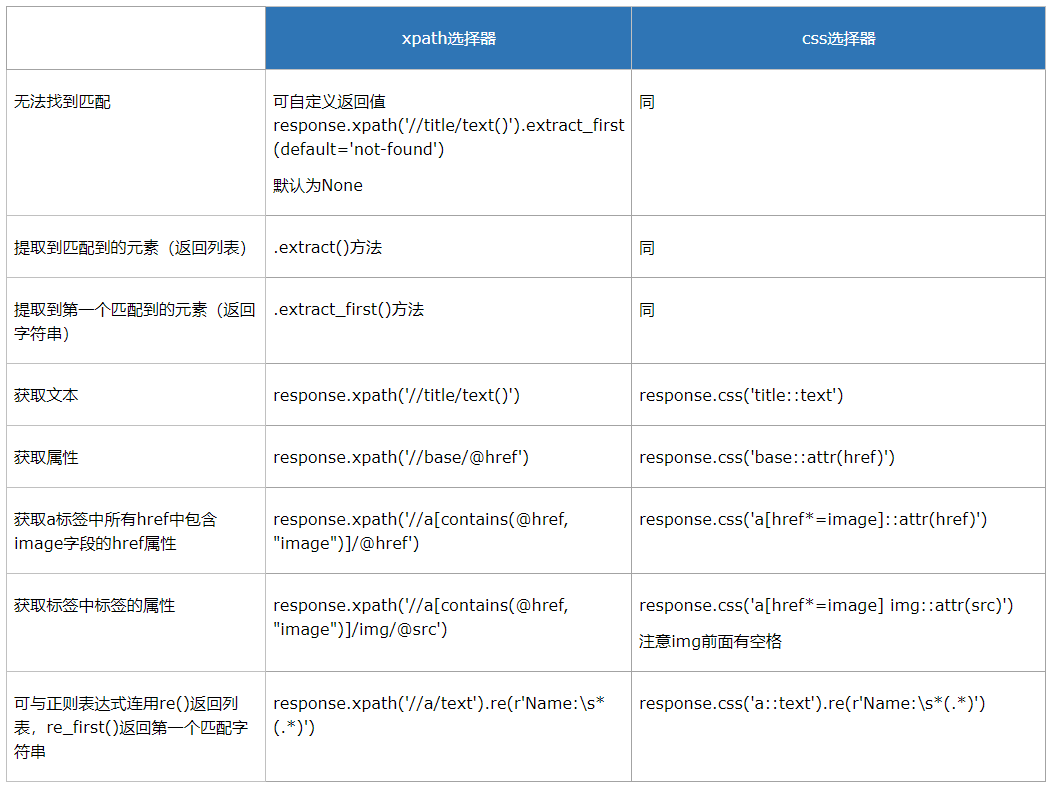
二、xpath、css
xpath的常用方法:
Xpath常用的方法: nodeName 选取此节点的所有节点 / 从根节点选取 // 从匹配选择的当前节点选择文档中的节点,不考虑它们的位置 . 选择当前节点 .. 选取当前节点的父节点 @ 选取属性 * 匹配任何元素节点 @* 匹配任何属性节点 Node() 匹配任何类型的节点
xpath的用法,获取同级标签的文本(获取下图中第二个a标签),如下示例:

scrapy->xpath代码:
response.xpath('//footer/a[2]/span/text()').extract()
三、爬虫过程遇到的一些问题
3.1、当我们爬取某些网站有图片并且使用img标签,使用src属性时,如下图例子:

如果直接使用response.xpath("//img[@class='board-img']/@src").extract(),获取结果为空,这时我们就要了解一下懒加载技术了,也就是说用到的时候再去加载,只显示可视区的内容,当你滑动到可视区的内容才设置真正的路径。
正确的实现方式:可将src属性改为data-src,当内容进入可视区时,js会动态给img添加一个src属性,如下:
response.xpath("//img[@class='board-img']/@data-src").extract()