概述
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
Spark SQL的特点
容易整合(集成)
统一的数据访问方式
兼容Hive
标准的数据连接
基本概念:Datasets和DataFrames
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优
化。DataFrames可以从各种来源构建,
例如:
结构化数据文件
hive中的表
外部数据库或现有RDDs
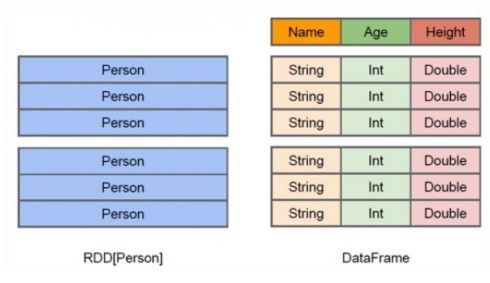
DataFrame多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。
DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的
特点是提升执行效率、减少数据读取以及执行计划的优化
Dataset是数据的分布式集合。Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一
级的抽象。它提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后
的执行引擎的优点。
创建DataFrames
通过Case Class创建DataFrames
- 定义case class
case class Emp(empno:Int,ename:String, job:String, mgr:String, hiredate:String, sal:Int, comm:String,deptno:Int)
2、读取 HDFS 数据转换为 Emp 对象的 RDD
val allEmp = sc.textFile("hdfs://172.24.28.65:9000/tmp/upload/emp.csv").map(_.split(",")).map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
3、 将对象 RDD 转化为 DataFrame
val allEmpDf = allEmp.toDF
//定义case class代表schema结构
case class Student(stuID:Int,stuName:String,stuAge:Int)
//创建SparkSession
val spark = SparkSession.builder().master("local").appName("SparkSQLDemo2").getOrCreate()
//从指定文件中读取数据,生成对应的RDD
val studentRDD = spark.sparkContext.textFile("D:\\temp\\student.txt").map(_.split(" "))
//将数据的RDD和case class关联起来
val dataRDD = studentRDD.map(x => Student(x(0).toInt, x(1), x(2).toInt))
//生成DataFrame,通过RDD生成DataFrame,导入隐私转换
import spark.sqlContext.implicits._
val studentDF = dataRDD.toDF()
//注册表,视图
studentDF.createOrReplaceTempView("student")
//执行sql
spark.sql("select * from student").show()
//释放资源
spark.stop()
#### 什么是SparkSession.
Spark session available as 'spark'.
spark 2.0以后 统一的访问方式. 通过SparkSession对象能够访问所有Spark模块
#### 指定schema,创建DataFrame
1, 创建StructType,来定义Schema结构信息
import org.apache.spark.sql.types._
val myschema = StructType(List(StructField("empno", DataTypes.IntegerType), StructField("ename", DataTypes.StringType),StructField("job", DataTypes.StringType),StructField("mgr", DataTypes.StringType),StructField("hiredate", DataTypes.StringType),StructField("sal", DataTypes.IntegerType),StructField("comm", DataTypes.StringType),StructField("deptno", DataTypes.IntegerType)))
2, 读入数据切分数据, 并将RDD中的数据映射撤 ROW
import org.apache.spark.sql.Row
val rowRDD = sc.textFile("hdfs://172.24.28.65:9000/tmp/upload/emp.csv").map(_.split(",")).map(x=>Row(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
3,创建 DataFrames
val df = spark.createDataFrame(rowRDD,myschema)
```scala
//创建SparkSession
val spark = SparkSession.builder().master("local").appName("SparkSQLDemo1").getOrCreate()
//从指定文件中读取数据,生成对应的RDD
val studentRDD = spark.sparkContext.textFile("D:\\temp\\student.txt").map(_.split(" "))
//创建schema,通过StructType
val schema =types.StructType(
List(
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)
)
)
//将RDD映射到RowRDD行的数据上
val rowRDD = studentRDD.map(student => Row(student(0).toInt, student(1), student(2).toInt))
//生成DataFrame
val studentDF =spark.createDataFrame(rowRDD,schema)
//将DF注册成表/视图
studentDF.createOrReplaceTempView("student")
//执行SQL
val result = spark.sql("select * from student").show()
//释放资源
spark.stop()
使用JSon文件来创建DataFame
val df = spark.read.json("/sss/sss")
在DataFrame中使用SQL语句
① 将DataFrame注册成表(视图):df.createOrReplaceTempView("emp")
② 执行查询:spark.sql("select * from emp").show
spark.sql("select * from emp where deptno=10").show
spark.sql("select deptno,sum(sal) from emp group by deptno").show
Global Temporary View
在Spark SQL中,如果你想拥有一个临时的view,并想在不同的Session中共享,而且在application的运行周期内可用,那么就需要创建一个全局的临时view。
① 创建一个普通的view和一个全局的view
df.createOrReplaceTempView("emp1")
df.createGlobalTempView("emp2")
② 在当前会话中执行查询,均可查询出结果。
spark.sql("select * from emp1").show
spark.sql("select * from global_temp.emp2").show
③ 开启一个新的会话,执行同样的查询
spark.newSession.sql("select * from emp1").show (运行出错)
spark.newSession.sql("select * from global_temp.emp2").show
创建Datasets
DataFrame的引入,可以让Spark更好的处理结构数据的计算,但其中一个主要的问题是:缺乏编译时
类型安全。为了解决这个问题,Spark采用新的Dataset API (DataFrame API的类型扩展)。
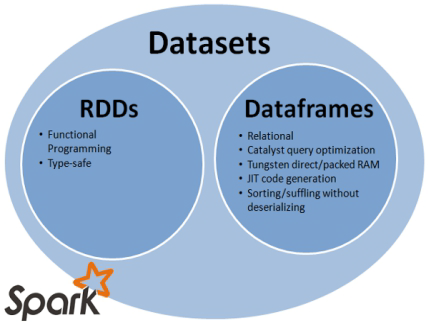
Dataset是一个分布式的数据收集器。这是在Spark1.6之后新加的一个接口,兼顾了RDD的优点(强类
型,可以使用功能强大的lambda)以及Spark SQL的执行器高效性的优点。所以可以把DataFrames看
成是一种特殊的Datasets,即:Dataset(Row)
创建DataSet,方式一:使用序列
1, 定义case class
case class MyData(a:Int,b:String)
2, 生成序列,并创建DataSet
val ds = Seq(MyData(1,"Tom"),MyData(2,"Mary")).toDS
创建DataSet,方式二:使用JSON数据
1、定义case class
case class Person(name: String, gender: String)
2、通过JSON数据生成DataFrame
val df = spark.read.json(sc.parallelize("""{"gender": "Male", "name": "Tom"}""" :: Nil))
3、将DataFrame转成DataSet
df.as[Person].show
df.as[Person].collect
创建DataSet,方式三:使用HDFS数据
1、读取HDFS数据,并创建DataSet
val linesDS = spark.read.text("hdfs://hadoop111:9000/data/data.txt").as[String]
linesDS.flatMap(.split(" ")).map((,1)).groupByKey(x => x._1).count
使用数据源
什么是parquet文件?
Parquet是列式存储格式的一种文件类型,列式存储有以下的核心:
可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如
Run Length Encoding和Delta Encoding)进一步节约存储空间。
只读取需要的列,支持向量运算,能够获取更好的扫描性能。
Parquet格式是Spark SQL的默认数据源,可通过spark.sql.sources.default配置
通用的Load/Save函数
读取Parquet文件
val usersDF = spark.read.load("/root/resources/users.parquet")
显式指定文件格式:加载json格式
val usersDF = spark.read.format("json").load("/root/resources/people.json")
存储模式(Save Modes)

查询一下用户的名字和喜欢的颜色 并保存
userDF.select($"name",$"favorite_color").write.save("/root/tools/temp/result111")
userDF.select($"name",$"favorite_color").write.format("csv").save("/root/tools/temp/result0927")
userDF.select($"name",$"favorite_color").write.csv.save("/root/tools/temp/result0927")
使用JDBC
Spark SQL同样支持通过JDBC读取其他数据库的数据作为数据源。
方法一:
val oracleDF = spark.read.format("jdbc").
option("url","jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com").
option("dbtable","scott.emp").
option("user","xxx").
option("password","xxx").
load
方法二:
import java.util.Properties
定义属性:
val oracleprops = new Properties()
oracleprops.setProperty("user","XX")
oracleprops.setProperty("password","x'x")
读取数据:
val oracleEmpDF =
spark.read.jdbc("jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com",
"scott.emp",oracleprops)
使用Hive Table
配置Spark SQL支持Hive
只需要将以下文件拷贝到$SPARK_HOME/conf的目录下,即可
$HIVE_HOME/conf/hive-site.xml
$HADOOP_CONF_DIR/core-site.xml
$HADOOP_CONF_DIR/hdfs-site.xml
使用Spark Shell操作Hive
启动Spark Shell的时候,需要使用--jars指定mysql的驱动程序
使用spark-sql操作Hive
启动spark-sql的时候,需要使用--jars指定mysql的驱动程序
性能优化
在内存中缓存数据
性能调优主要是将数据放入内存中操作。通过spark.cacheTable("tableName")或者dataFrame.cache()。使用spark.uncacheTable("tableName")来从内存中去除table。
spark.sqlContext.cacheTable("emp")
spark.sqlContext.clearCache
性能优化相关参数
将数据缓存到内存中的相关优化参数
spark.sql.inMemoryColumnarStorage.compressed
默认为 true
Spark SQL 将会基于统计信息自动地为每一列选择一种压缩编码方式。
spark.sql.inMemoryColumnarStorage.batchSize
默认值:10000
缓存批处理大小。缓存数据时, 较大的批处理大小可以提高内存利用率和压缩率,但同时也会带来
OOM(Out Of Memory)的风险。
其他性能相关的配置选项(不过不推荐手动修改,可能在后续版本自动的自适应修改)
spark.sql.files.maxPartitionBytes
默认值:128 MB
读取文件时单个分区可容纳的最大字节数
spark.sql.files.openCostInBytes
默认值:4M
打开文件的估算成本, 按照同一时间能够扫描的字节数来测量。当往一个分区写入多个文件的时候会使
用。高估更好, 这样的话小文件分区将比大文件分区更快 (先被调度)。
spark.sql.autoBroadcastJoinThreshold
默认值:10M
用于配置一个表在执行 join 操作时能够广播给所有 worker 节点的最大字节大小。通过将这个值设置为
-1 可以禁用广播。注意,当前数据统计仅支持已经运行了 ANALYZE TABLE COMPUTE STATISTICS
noscan 命令的 Hive Metastore 表。
spark.sql.shuffle.partitions
默认值:200
用于配置 join 或聚合操作混洗(shuffle)数据时使用的分区数。