Doris存储文件格式优化
GROUPING SETS 设计文档
GROUP BY GROUPING SETS 是对 GROUP BY 子句的扩展,它能够在一个 GROUP BY 子句中一次实现多个集合的分组。其结果等价于将多个相应 GROUP BY 子句进行 UNION 操作。
SELECT k1, k2, SUM(k3) FROM t GROUP BY GROUPING SETS ( (k1, k2), (k2), (k1), ( ) );
以上 SQL 等价于 如下SQL
SELECT k1, k2, SUM( k3 ) FROM t GROUP BY k1, k2
UNION
SELECT k1, null, SUM( k3 ) FROM t GROUP BY k1
UNION
SELECT null, k2, SUM( k3 ) FROM t GROUP BY k2
UNION
SELECT null, null, SUM( k3 ) FROM t
ROLLUP 子句
ROLLUP 是对 GROUPING SETS 的扩展。
SELECT a, b,c, SUM( d ) FROM tab1 GROUP BY ROLLUP(a,b,c)
以上等价于 如下SQL
GROUPING SETS (
(a,b,c),
( a, b ),
( a),
( )
)
CUBE 子句
CUBE 也是对 GROUPING SETS 的扩展。
CUBE ( e1, e2, e3, ... ) 其含义是 GROUPING SETS 后面列表中的所有子集。
相当于如下
GROUPING SETS (
( a, b, c ),
( a, b ),
( a, c ),
( a ),
( b, c ),
( b ),
( c ),
( )
)
元数据设计文档
- FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。
- BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
- bdbje:Oracle Berkeley DB Java Edition (opens new window)。在 Doris 中,我们使用 bdbje 完成元数据操作日志的持久化、FE 高可用等功能。
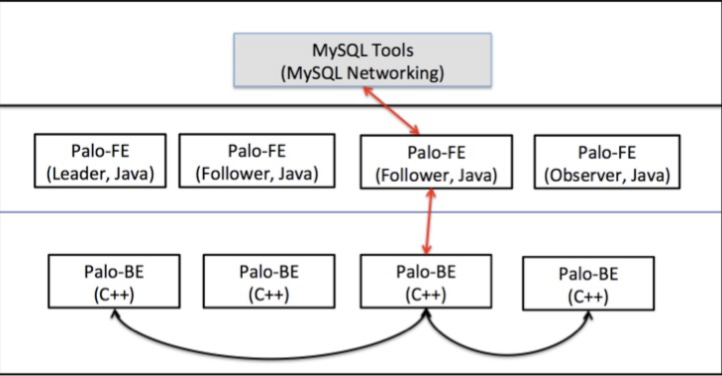
1、FE 节点分为 follower 和 observer 两类。各个 FE 之间,通过 bdbje(BerkeleyDB Java Edition (opens new window))进行 leader 选举,数据同步等工作。
2、follower 节点通过选举,其中一个 follower 成为 leader 节点,负责元数据的写入操作。当 leader 节点宕机后,其他 follower 节点会重新选举出一个 leader,保证服务的高可用。
3、observer 节点仅从 leader 节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
Doris 的元数据是全内存的。每个 FE 内存中,都维护一个完整的元数据镜像。