textContent主要用法
备注:工作要取富文本里面的内容,但是只取开头前50个左右字符串,就想到textContent,大致总结了一下,大家可以借鉴参考一下textContent有更加信息的内容。
<一> textContent介绍
浏览器支持:IE9~11、FireForx、Chrome
赋值操作:先将ASCII实体对应的字符(<、>、&、'和")转换为实体名,然后把处理后的值赋予给innerHTML属性。
取值操作:textContent的取值实际上就是对innerHTML的属性值进行一系列处理,然后返回,具体步骤如下
1. 对HTML标签进行剔除;
2. 将ASCII实体转换为相应的字符。
注意:
a). 对HTML标签是剔除不是解析,也不会出现CSS解析和渲染的处理,因此<br/>等元素是不生效的。
b). 不会剔除格式信息和合并连续的空格,因此 、 、 和连续的空格将生效。
<二> textContent测试
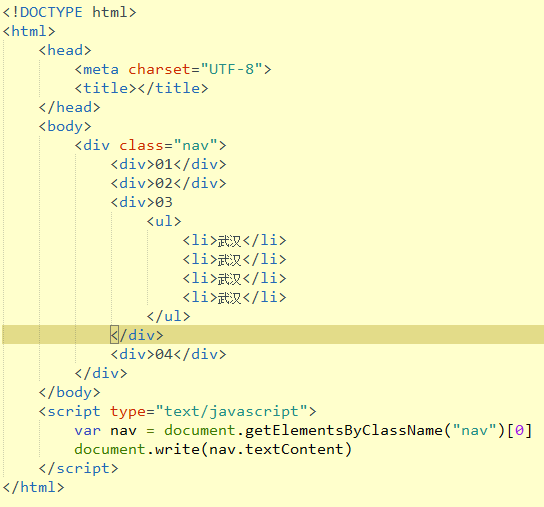
得到的结果是: 01 02 03 武汉 武汉 武汉 武汉 04