学了两天, 感觉python很简单, 就想做一个爬虫,我喜欢弄博文, 就想着爬取博客园首页的Java博文, 目前已经实现爬取200页的博文, 一页20条, 爬了4000, 效果还不错, 下面就讲一下爬取的需求:
(1).爬取网页
(2).保存网页内容,包括图片,文本等
(3).实现本地打开, 无乱码, css格式正确
(4).能够断点爬取
(5).除了Java目录外, 可以扩展到其他语言目录
完成这些功能, 以后就可以每天看大量的博文了,看一篇, 删一篇,mmp(弄不好的,加群解决!!!)
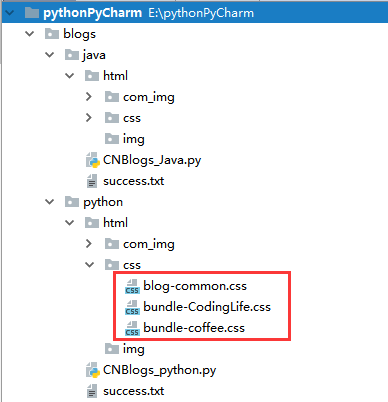
目录结构:
如果爬取网页遇到错误, 就在success.txt中手动添加这个出错的url吧, 算是放弃!!!
css文件夹: 上图中的css是从博客园的博文中head标签中下载的:

com_img文件夹: 是css文件夹中需要的img背景图和其他图片等
img文件夹: 是存放下载的html文件中的图片, 实现本地化
success.txt : 是保存下载过的html的url, 支持断点下载
网页下载路径:

下面是代码, 都加注释, 很简单:欢迎加入:123300273, 学习交流!!!
from bs4 import BeautifulSoup import urllib.request import re import uuid import socket socket.setdefaulttimeout(10.0)# 设置图片下载超时 # 进度 def Schedule(a, b, c): # a:已经下载的数据块 # b:数据块的大小 # c:远程文件的大小 per = 100.0 * a * b / c if per > 100: per = 100 print('%.2f%%' % per) ##获取目标页面的源码 def getHtml(url): page = urllib.request.urlopen(url) ##打开页面 html = page.read() ##获取目标页面的源码 return html def getBlogsURL(html): # reg = 'src="(.+?.png)"' ##正则表达式筛选目标图片格式,有些是'data-original="(.+?.jpg)"' # img = re.compile(reg) # < a class ="titlelnk" href="https://www.cnblogs.com/coderJiebao/p/Netty07.html" target="_blank" > Netty入门(七)使用SSL / TLS加密Netty程序 < / a > img = re.compile(r'<a class=.+?href="(.+?)" target') html = html.decode('utf-8') ##编码方式为utf-8 imglist = re.findall(img, html) ##解析页面源码获取图片列表 # print(imglist) # x = 0 # length = len(imglist) # for i in range(6): ##取前6张图片保存 # imgurl = imglist[i] # # imgurl = re.sub('"(.*?)"',r'1',imgurl) #取单引号里的双引号内容 # # print(imgurl) # urllib.request.urlretrieve(imgurl, './helloworld1/%s.jpg' % x, Schedule) ##将图片从远程下载到本地并保存 # x += 1 return imglist def getBody(html): soup = BeautifulSoup(html, 'html.parser') # 文档对象 #标题 divTitle = soup.find_all('div', class_="postTitle") if (len(divTitle) == 0): divTitle = soup.find_all('h1', class_="postTitle") if (len(divTitle) == 0): divTitle = soup.find_all('h2') if (len(divTitle) == 0): divTitle = soup.find_all('div',class_="posttitle") if (len(divTitle) == 0): divTitle = soup.find_all('h1', class_="block_title") if (len(divTitle) == 0): return #内容 divBody =soup.find_all('div',class_="postBody") if (len(divBody) == 0): divBody = soup.find_all('div',class_="blogpost-body") if (len(divBody) == 0): return divBody_set = str(divBody[0]) imageEntityArray = divBody[0].find_all('img') for image in imageEntityArray: link = image.get('src') count2 = str(uuid.uuid1()) try: print("图片:" + str(link)) if not ("i.imgur.com" in link or "http://www.ityouknow.com/assets/images/2017/jvm/jvm05.png" in link ) : # urllib.request.urlretrieve(link, 'html/img/%s.jpg' % count2, Schedule) urllib.request.urlretrieve(link, 'html/img/%s.jpg' % count2) except Exception: print("错误:" + str(link)) divBody_set=divBody_set.replace(str(link),'img/%s.jpg' % count2) # print("标题:"+str(divTitle)) # print("内容:"+str(divBody_set)) img = re.compile(r'>(.+?)<') html = html.decode('utf-8') ##编码方式为utf-8 imglist = re.findall(img, html) ##解析页面源码获取图片列表 x=imglist[0]
x=x.replace("/", " ") x=x.replace(":", " ") x=x.replace("*", " ") x=x.replace("|", " ") x=x.replace("~", " ") x=x.replace("?", " ") x=x.replace("?", " ") x=x.replace("?", " ") x=x.replace("\", " ") x=x.replace("$", " ") x=x.replace(""", " ") x=x.replace("<", " ") x=x.replace(">", " ") file = open("html/%s.html" % x, "w",encoding='utf-8') file.write('<html lang="zh-cn"><head><meta charset = "utf-8" > <link type = "text/css" rel = "stylesheet" href = "css/bundle-coffee.css"><link type = "text/css" rel = "stylesheet" href = "css/bundle-CodingLife.css"><link type = "text/css" rel = "stylesheet" href = "css/blog-common.css"></head>') file.write('<body style=" 68%;margin:0 auto;"><div id="topics">') file.write(str(divTitle[0])) file.write(str(divBody_set)) file.write('</div></body></html>') file.close() # img = re.compile(r'<div class="postBody">(.+?)') # html = html.decode('utf-8') ##编码方式为utf-8 # imglist = re.findall(img, html) ##解析页面源码获取图片列表 # count = 1 # for body in imglist: # print(str(count) + ":" + body) # # urllib.request.urlretrieve(url, './helloworld1/%s.jpg' % count, Schedule) # count = count + 1 def getURLTXT(): listURl=[] f=open("success.txt", "r",encoding='utf-8') lines=f.readlines() for line in lines: listURl.append(str(line)) f.close() return listURl def setURLTXT(url): f = open("success.txt", "a", encoding='utf-8') f.write(url) f.close() def comparisonURL(url,listURl): if str(url)+" " in listURl: return True def main(url): html = getHtml(url) imglist= getBlogsURL(html) return imglist if __name__ == '__main__': imglist=[]
#自己修改要下载多少页, 有的目录下载的页面没有200页, 要注意!!! for i in range(200): url="https://www.cnblogs.com/cate/java/"+str(i) print("读取第"+str(i) + "页:" + url) imglist=imglist+main(url) count = 1 for url in imglist: print(str(count) + ":" + url) # urllib.request.urlretrieve(url, './helloworld1/%s.jpg' % count, Schedule) listURl=getURLTXT() if not comparisonURL(url, listURl): try: html = getHtml(url) except Exception: print("错误:" + url) getBody(html) setURLTXT(url+" ") count = count + 1