本文作者简介:王夜笙,就读于郑州大学信息工程学院,感兴趣的方向为逆向工程和机器学习,长期从事数据抓取工作(长期与反爬虫技术作斗争~),涉猎较广(技艺不精……),详情请见我的个人博客~
感谢怡轩同学的悉心指导~
之前拜读了靳志辉(@rickjin)老师写的《正态分布的前世今生》,一直对正态分布怀着一颗敬畏之心,刚好最近偶然看到python标准库中如何生成服从正态分布随机数的源码,觉得非常有趣,于是又去查找其他一些生成正态分布的方法,与大家分享一下。
利用中心极限定理生成正态分布
设X1,X2,⋯,Xn为独立同分布的随机变量序列,均值为μ,方差为σ2,则
具有渐近分布N(0,1),也就是说当n→∞时,
换句话说,n个相互独立同分布的随机变量之和的分布近似于正态分布,n越大,近似程度越好。当然也有例外,比如n个独立同分布的服从柯西分布随机变量的算术平均数仍是柯西分布,这里就不扩展讲了。
根据中心极限定理,生成正态分布就非常简单粗暴了,直接生成n个独立同分布的均匀分布即可,看代码
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
def getNormal(SampleSize,n):
result = []
for i in range(SampleSize):
# 利用中心极限定理,[0,1)均匀分布期望为0.5,方差为1/12
iid = (np.mean(np.random.uniform(0,1,n))-0.5)*np.sqrt(12*n)
result.append(iid)
return result
# 生成10000个数,观察它们的分布情况
SampleSize = 10000
# 观察n选不同值时,对最终结果的影响
N = [1,2,10,1000]
plt.figure(figsize=(10,20))
subi = 220
for index,n in enumerate(N):
subi += 1
plt.subplot(subi)
normal = getNormal(SampleSize, n)
# 绘制直方图
plt.hist(normal,np.linspace(-4,4,81),facecolor="green",label="n={0}".format(n))
plt.ylim([0,450])
plt.legend()
plt.show()得到结果如下图所示
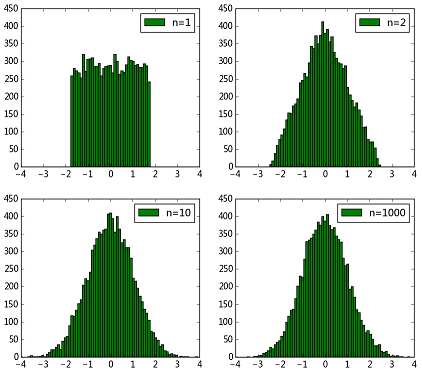 可以看到,
可以看到,n=1时其实就是均匀分布,随着n逐渐增大,直方图轮廓越来越接近正态分布了~因此利用中心极限定理暴力生成服从正态分布的随机数是可行的。但是这样生成正态分布速度是非常慢的,因为要生成若干个同分布随机变量,然后求和、计算,效率是非常低的。
利用逆变换法生成正态分布
假设u=F(x)是一个概率分布函数(CDF),F−1是它的反函数,若U是一个服从(0,1)均匀分布的随机变量,则F−1(U)服从函数F给出的分布。例如要生成一个服从指数分布的随机变量,我们知道指数分布的概率分布函数(CDF)为F(x)=1–e–λx,其反函数为F−1(x)=−ln(1−x)λ,所以只要不断生成服从(0,1)均匀分布的随机变量,代入到反函数中即可生成指数分布。
正态分布的概率分布函数(CDF)如下图所示,
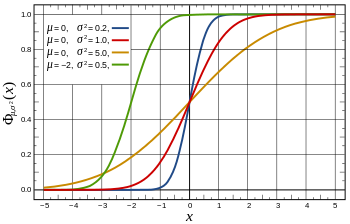 在
在y轴上产生服从(0,1)均匀分布的随机数,水平向右投影到曲线上,然后垂直向下投影到x轴,这样在x轴上就得到了正态分布。
当然正态分布的概率分布函数不方便直接用数学形式写出,求反函数也无从说起,不过好在scipy中有相应的函数,我们直接使用即可。
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
def getNormal(SampleSize):
iid = np.random.uniform(0,1,SampleSize)
result = norm.ppf(iid)
return result
SampleSize = 10000000
normal = getNormal(SampleSize)
plt.hist(normal,np.linspace(-4,4,81),facecolor="green")
plt.show()结果如下图所示,
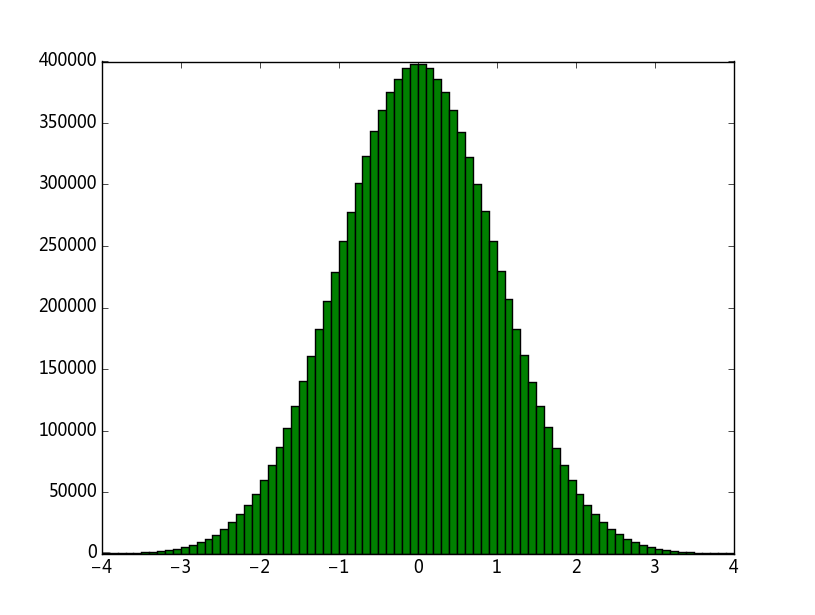 以上两个方法虽然方便也容易理解,但是效率实在太低,并不实用,那么在实际中到底是如何生成正态分布的呢?
以上两个方法虽然方便也容易理解,但是效率实在太低,并不实用,那么在实际中到底是如何生成正态分布的呢?
Box–Muller算法
说来也巧,某天闲的无聊突然很好奇python是如何生成服从正态分布的随机数的,于是就看了看random.py的代码,具体实现的代码就不贴了,大家自己去看,注释中有下面几行
# When x and y are two variables from [0, 1), uniformly # distributed, then # # cos(2*pi*x)*sqrt(-2*log(1-y)) # sin(2*pi*x)*sqrt(-2*log(1-y)) # # are two *independent* variables with normal distribution
顿时感觉非常神奇,也就是说当x和y是两个独立且服从(0,1)均匀分布的随机变量时,cos(2πx)⋅–2ln(1–y)−−−−−−−−−√和sin(2πx)⋅–2ln(1–y)−−−−−−−−−√是两个独立且服从正态分布的随机变量!
后来查了查这个公式,发现这个方法叫做Box–Muller,其实本质上也是应用了逆变换法,证明方法比较多,这里我们选取一种比较好理解的
我们把逆变换法推广到二维的情况,设U1,U2为(0,1)上的均匀分布随机变量,(U1,U2)的联合概率密度函数为f(u1,u2)=1(0≤u1,u2≤1),若有:
其中,g1,g2的逆变换存在,记为
且存在一阶偏导数,设J为Jacobian矩阵的行列式
则随机变量(X,Y)的二维联合密度为(回顾直角坐标和极坐标变换):
根据这个定理我们来证明一下,
求反函数得
计算Jacobian行列式