摘要:
问题:There is a need that 以一个更全面/更综合的方式来展现搜索结果。对此,作者正在开发一个系统,called “Cronopath”,这个系统将产生一个时间线,通过决定每个文档中的时间帧,并且连接时间线上的元素到相应的文档中。 本文,作者提出了评估自动生成时间线的质量的指南,基于一系列的共同特征。
引言:
Cronopath System
我们已经开发出了自动生成时间线的系统(参考“Timeline Extraction from Hyperlinked Text Corpora”,不可见, 收费),接下来我们要做的就是设计出一套标准/指南,来评估自动生成的时间线。
通过观察现有的时间线,我们发现手动创建的时间线都有一系列的特征,而这些特征正好可以作为评估的标准。 我们假设时间线是从一个支持的文档的数据集中产生的,这些文档首先被处理以提取命名实体和一系列的时间戳以及之间的关系。 接着,每个文档被处理以识别一个时间范围来缩短文件可能创立的时间,结合“时间表达式分析”技术(参考“TIDES 2005 Standard for the Annotation of Temporal Expressions”)和“文本的时间分类”技术(参考“Temporal Classification of Texts”)。 同时,“多文档的摘要技术”也是需要的,用来提取/生成相关的句子来作为时间线每段时间的标签。
接下来,我们将讨论时间线的特征/组成:
1. 什么是Timeline, 如图1所示。
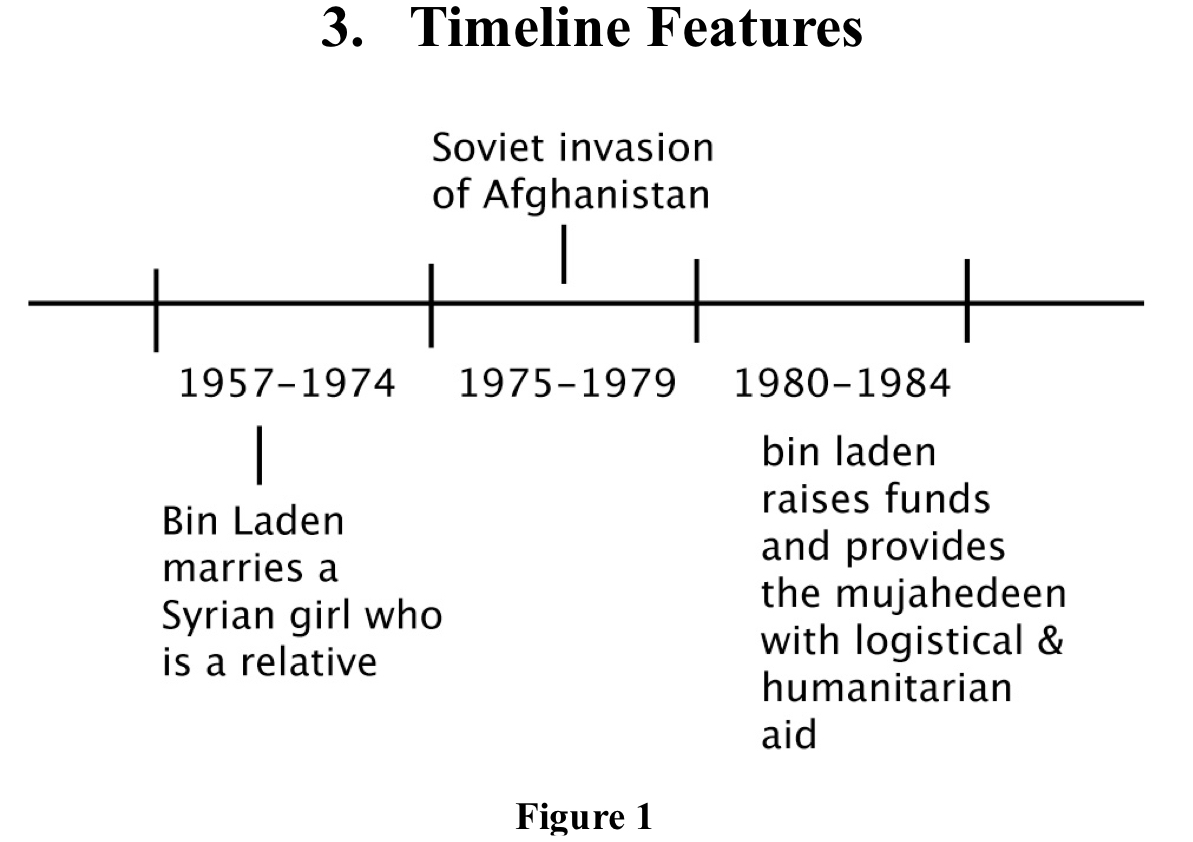
2. 什么是TimeFrame: 时间线里的时间间隔,例如,图1中的 1957-1974是一个timeframe,1975-1979,1980-1984,这都是timeframe
3. 什么是Label:每一个timeframe的内容摘要。
重要的特征:
1. Accuracy: a. 每一个相关的文档都被包含在时间帧里面, b. 时间线包含正确的文本标签, c. 时间线包含文档中最重要的方面/事实
2. presentation. 表现形式,是以图形显示,还是以时间轴显示,显示的帧数,单位大小等等
Evaluation Guideline
一. ACCURACY
1. Is Timeframe for each timeline dcoument correct?
评估的方法很直观:: 检查每一个timeframe链接的文档中,是否列举了该时间点,例如1956-1974所对应的文档中,应该出现1956,1957,1958.....1974。(问题,如果只有起始点跟终止点呢? 比如 : 1956: Sb entered the high school. 1959: Sb graduated from the high school. )
2. Does the timeline label reflect the document that it represent?
一个很普通的做法是: 直接在文档中搜索这个label --- 通常效果不太好
还可以就是,通过document重新计算出summary, 然后将summary与label进行对比 ----uncessarily complex
作者提出,寻找n-grams(参考 "An introduction to information Extraction") 从label中。理论上,label会跟documents有重叠的内容。 可以通过调整权制,n越大,N-gram的值越高。这需要创建一个手动的算法。
3. 时间线包含了文档最重要的内容/事件吗?
这是最困难的一个问题 without using an information extraction engin. 一个简单的方法是在文档中关于重叠的词使用频度计数(包括用于标签的n-gram,更大的n值有着更大的权重)。一般而言,人们期望出现在标签中的词语有着更高的出现频度。然而,没有出现在时间线上,但是有着很高出现率的事件/事实不能通过这个方法被找到。(大致意思就是,我们只能判断这个时间线的label是否是重要的事件,但是不能说,重要的事件都被它包含了。) 另一个判断事件是否是全局重要的方法是:把这个标签,输入到另一个搜索引擎中,例如Google,记录词条返回的数量。
二. PRESENTATION
虽然时间线的展现包含了更多的个人审美,但是有几点需要注意:
1. 保持每个时间帧的单元数相同,一般而言都是10个。
2. 保证标签的字体大到足以识别,而且仅仅显示一部分时间线,其他的通过点击滚动来展现
3. 一般而言都是水平时间线。
基于网页的时间线评估语义库
wikipedia 维基百科有几百个基于文档的时间线,http://en.wikipedia.org/wiki/Timelines. 我们正在收集这些文档以及时间线,然后建立数据集。这些可以数据集可以用来自动创建时间线。可以把生成的时间线与wikipedia的时间线进行对比(即使wikipedia时间线的权威性有待商榷)。
结论
在Cornopah的下一个阶段, 我们将评估自动生成的时间线,用本文提出的指导方针。我们感觉,自动生成时间线将会在未来成为一个流行的趋势来展现与总结信息。
评论:1. 关于时间线的基本描述以及特征总结的很简洁明了,适合新学者阅读
2. 关于本文的贡献不太明确:首先,这个系统到底有没有被开发出来; 其次,为什么把系统作为一个论文,把评估的指导方针作为一个论文,然后将评估的结果作为下一篇论文? 如果将整个内容,结合起来,发一篇paper或许会更好。
参考文献:Evaluating Automatically Generated Timelines from the Web. Roberta Catizone. et.