事务(transaction)是数据库管理系统的执行单位,可以是一个数据库操作(如Select操作)或者是一组操作序列。事务ACID属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
| Isolation level | Dirty reads | Non-repeatable reads | Phantoms |
|---|---|---|---|
| Read Uncommitted | may occur | may occur | may occur |
| Read Committed | don't occur | may occur | may occur |
| Repeatable Read | don't occur | don't occur | may occur |
| Serializable | don't occur | don't occur | don't occur |
| A事务 | B事务 |
| 读余额为2000元 | |
| 转出1000元 | |
| 再次读余额为1000元 | |
| 发现不对,回滚转出的1000元 | |
| 再次读余额为2000元,很纳闷 |
Read committed 是一个很受欢迎的隔离级别. 像Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL等都是默认此隔离级别的。
2.1 它保证了下面两种情况:
1. When reading from the database, you will only see data that has been committed (no dirty reads).

如上图所示,User1只会读取到User2已经提交了的数据。
for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value.
(当每个对象在写的时候,数据库会记住已经被提交的旧值和当前事务持有写锁设置的新值。当一个事务还在进行中,那么其他事务读取到的就是旧值。只有当新值被提交的时候才会被其他事务读取到。)
2. When writing to the database, you will only overwrite data that has been committed (no dirty writes).
Most commonly, databases prevent dirty writes by using row-level locks: when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object.
It must then hold that lock until the transaction is com‐ mitted or aborted. Only one transaction can hold the lock for any given object; if another transaction wants to write to the same object,
it must wait until the first transaction is committed or aborted before it can acquire the lock and continue. This locking is done automatically by databases in read committed mode (or stronger iso‐ lation levels).
(通常数据库避免脏写是使用了行级锁,当一个事务想要去修改数据时,它会首先得到这个数据对象的锁,直到事务提交或者回滚。而且只有一个事务能够持有这个锁;
如果其他事务想要去写相同的数据对象,它必须等到上一个事务提交或者回滚然后去得到这把锁。这种锁机制是数据库在read committed或者更高的隔离级别下自动做到的。)
2.2 虽然RC隔离级别下能够防止脏读和脏写,但是会出现不可重复读或者读倾斜(nonrepeatable read or read skew ),如下图情况
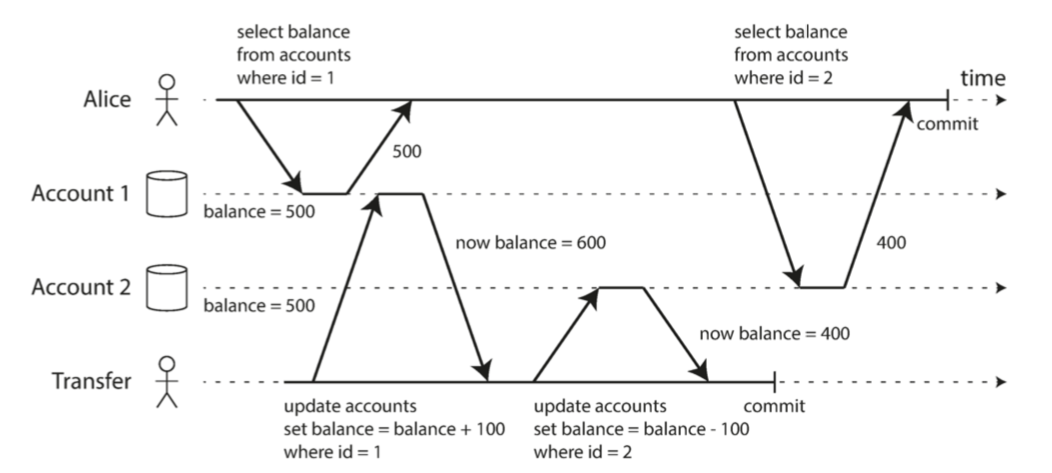
正是因为事务可以读取到另一个事务已经提交的数据,所以Alice读取到的数据在有Transfer和没有Transfer两种情况下,会不一样。
为了解决这种问题,数据库提供了snapshot isolation (快照隔离),也就是multi-version concurrency control (MVCC) 。
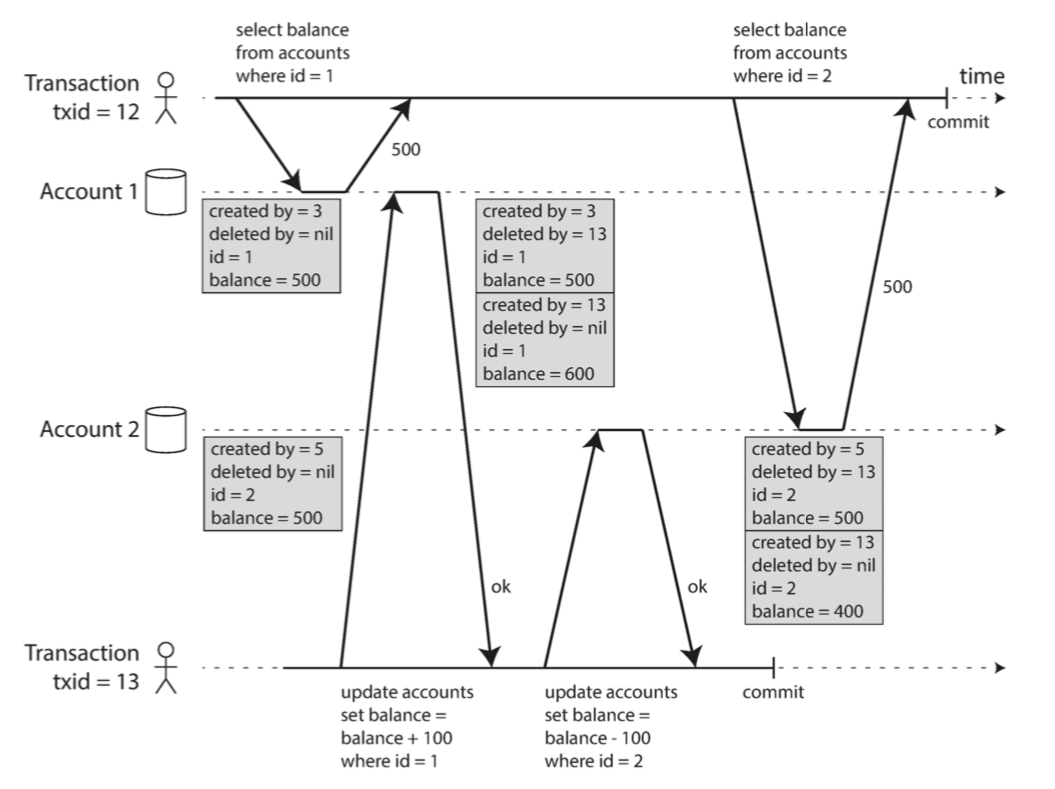
笼统点说,就是事务12的所有快照读只会读取created by版本号小于等于自己的快照数据。
这儿有一篇形象点的关于MVCC的文章:https://blog.csdn.net/whoamiyang/article/details/51901888
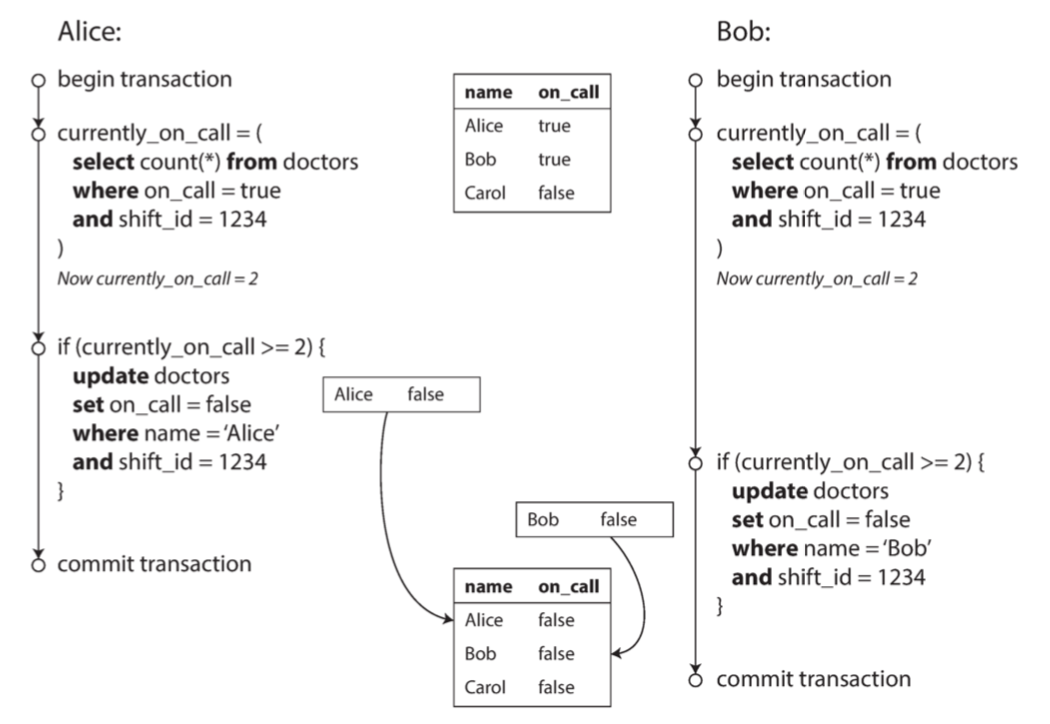
Alice和Bob都是基于快照读去做自己的逻辑操作,这就导致写倾斜(write skew )。
其实在RR隔离级别下,Lost updates、Write skew、Phantom reads都是有可能发生的,
在禁用innodb_locks_unsafe_for_binlog(5.6版本已弃用)的情况下,在搜索和扫描index的时候使用的next-keylocks可以避免幻读。
我的理解是,在一个事务开启但没有结束之前,SELECT FOR UPDATE(当前读) 会给查询到的数据行加上next-key locks,对于同一张表而言,事务之间就是串行化的了。
具体的加锁细节还需要区分查询条件,以及索引的设置等,关于mysql数据库事务锁分析的:http://hedengcheng.com/?p=771,https://my.oschina.net/u/3159571/blog/3060513/print。
对于SELECT FOR UPDATE(当前读)如果没有查询到数据,那么不同事务间的SELECT操作将不会阻塞,因为gap锁和gap锁是允许共存的,只是gap锁会阻塞DML语句的执行。
| A事务 | B事务 |
| 代码A1 | |
| 代码A2 | |
| 代码B1 | |
| 代码B2 |
-
-
If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue.(This ensures that B can’t change the object unexpectedly behind A’s back.)
-
If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue.
-
两阶段加锁,写操作不仅会阻塞其他的写操作也会阻塞读操作,快照隔离(MVCC)读不会阻塞写操作,写操作也不会阻塞读操作,这也是两者关键的不同点。
在mysql中两阶段加锁就用来实现串行化隔离级别。
两阶段分别是事务执行时期的加锁阶段和事务提交或者回滚的解锁阶段。
Dirty reads
One client reads another client’s writes before they have been committed. The read committed isolation level and stronger levels prevent dirty reads.
(事务1读取到另一个事务还没有提交的写操作数据,RC及其以上隔离级别能避免脏读)
Dirty writes
One client overwrites data that another client has written, but not yet committed. Almost all transaction implementations prevent dirty writes.
(事务1覆盖写了其他事务还没有提交的写操作,通常所有的事务实现都能避免脏写)
Read skew (nonrepeatable reads)
A client sees different parts of the database at different points in time. This issue is most commonly prevented with snapshot isolation,
which allows a transaction to read from a consistent snapshot at one point in time. It is usually implemented with multi-version concurrency control (MVCC).
(事务在不同时间点看到不同的数据。通常是用快照隔离去避免它,快照隔离允许一个事务读取某个时间点的快照版本。它通常由MVCC实现。)
Lost updates
Two clients concurrently perform a read-modify-write cycle. One overwrites the other’s write without incorporating its changes, so data is lost.
Some implementations of snapshot isolation prevent this anomaly automatically, while others require a manual lock (SELECT FOR UPDATE).
(两个事务同时的循环去读取-修改-写。其中一个覆盖写了其他事务没有合并的修改,所有导致数据丢失。有些实现基于快照读可以自动避免修改丢失,然而有些就需要人为的加锁(SELECT FOR UPDATE))
Write skew
A transaction reads something, makes a decision based on the value it saw, and writes the decision to the database.
However, by the time the write is made, the premise of the decision is no longer true. Only serializable isolation prevents this anomaly.
(一个事务根据当前读取到的数据做了一些决策,然后把这些决策写入数据库。然而到写的时候,这个决策的前提不再正确了。仅仅只有serializable才能避免这种情况)
Phantom reads
A transaction reads objects that match some search condition. Another client makes a write that affects the results of that search.
Snapshot isolation prevents straightforward phantom reads, but phantoms in the context of write skew require special treatment, such as index-range locks.
(一个事务读取到匹配某些搜索条件的对象。其他事务写操作影响了这个搜索条件的结果。快照隔离能避免简单的幻读,但是在写倾斜的上下文中幻读需要特殊处理,比如index-range locks。)
注:文章中部分结论及图片引自《Designing.Data-Intensive.Applications》。