1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
创建文件夹(yxb)

将txt从本地弄到hadoop中
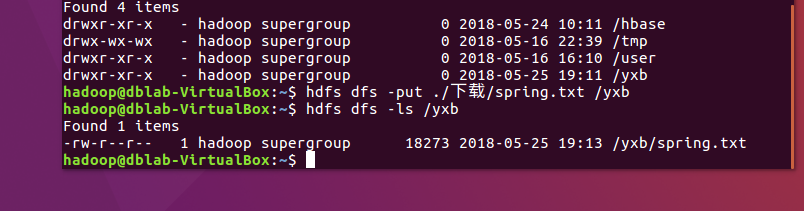
创建一张表(spring)

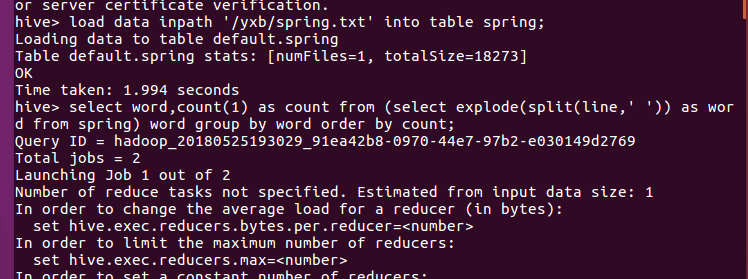
将springtxt里面的数据写入spring表

显示出词频统计

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
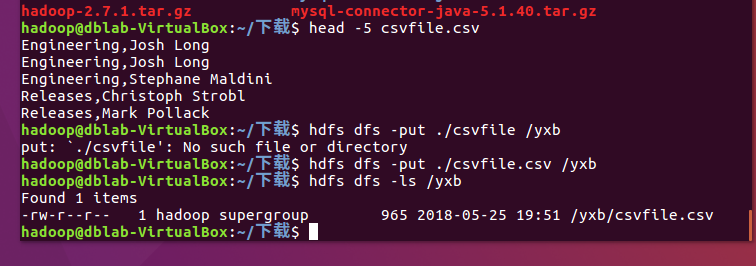
显示前五条数据,将文件复制进hadoop文件夹
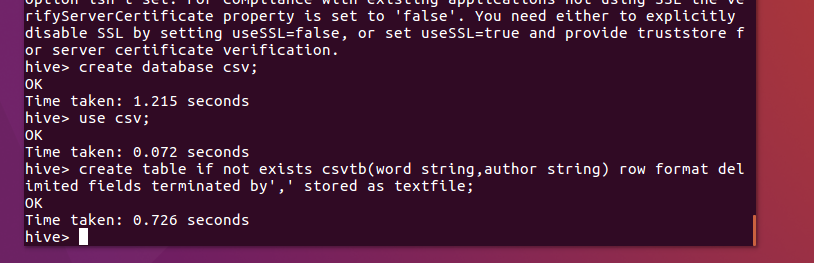
创建一个数据库,创建一个csvtb表
将csv文件的数据写入表格
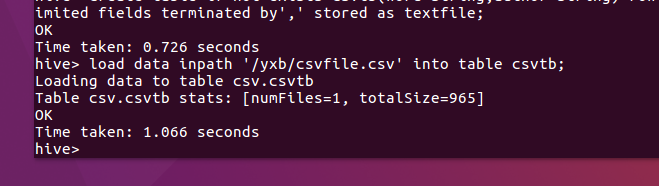
显示出表格中有多少条数据,因为爬取东西的时候,只爬了几页的文档和标题下面的信息(作者,文章种类)所以比较少
