报错如下:
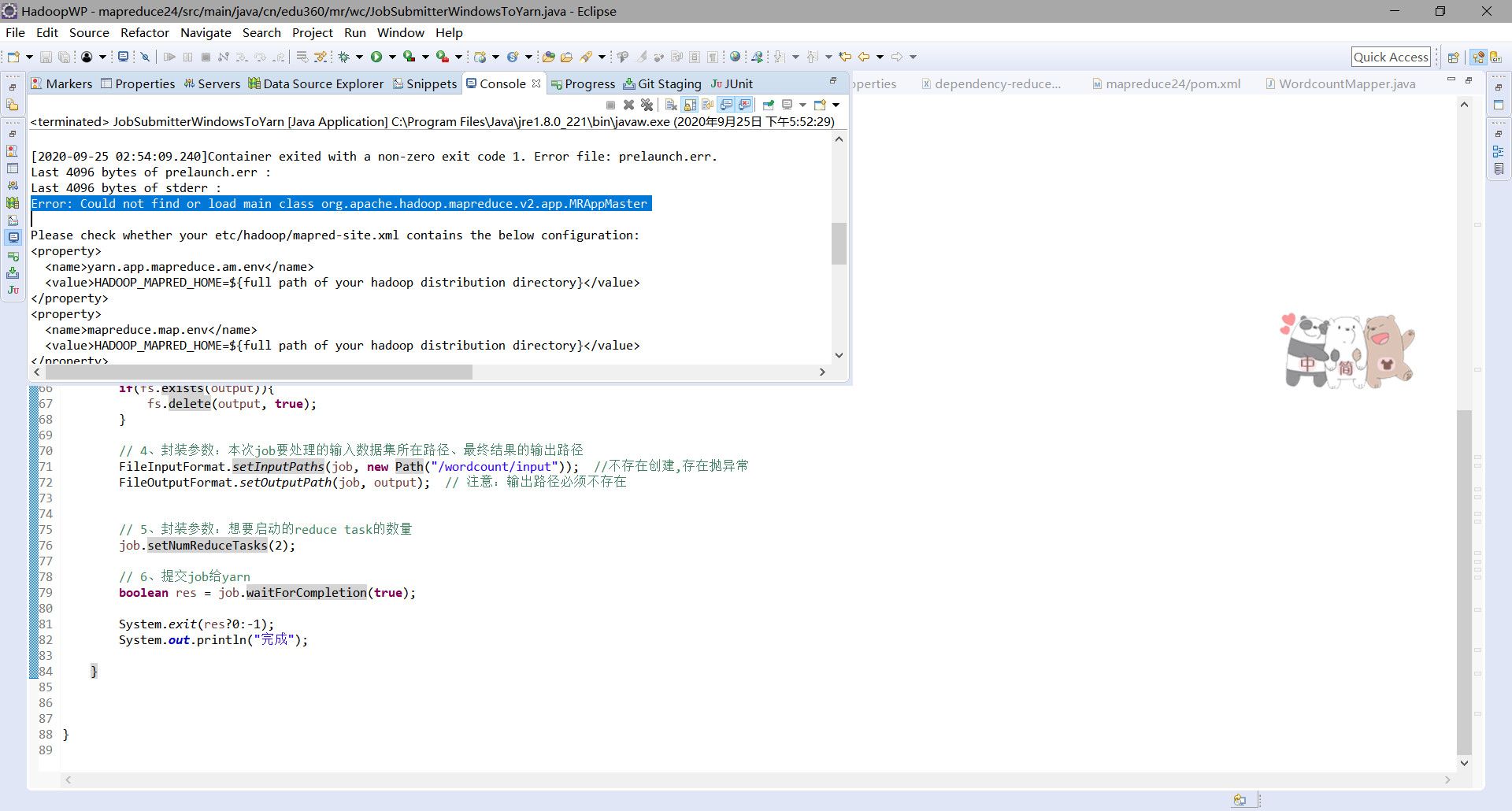
但是经过排查发现报错文件中存在错误中指明的参数,多次尝试依旧报相同的错误,最终将这些配置在代码中进行配置,成功运行
package cn.edu360.mr.wc;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 用于提交mapreduce job的客户端程序
* 功能:
* 1、封装本次job运行时所需要的必要参数
* 2、跟yarn进行交互,将mapreduce程序成功的启动、运行
* @author ThinkPad
*
*/
public class JobSubmitterWindowsToYarn {
public static void main(String[] args) throws Exception {
// 在代码中设置JVM系统参数,用于给job对象来获取访问HDFS的用户身份
//解决权限问题
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
// 1、设置job运行时要访问的默认文件系统
conf.set("fs.defaultFS", "hdfs://hdp-01:9000");
// 2、设置job提交到哪去运行
conf.set("mapreduce.framework.name", "yarn"); //交给yarn运行
conf.set("yarn.resourcemanager.hostname", "hdp-01"); //位置
// 3、如果要从windows系统上运行这个job提交客户端程序,则需要加这个跨平台提交的参数
conf.set("mapreduce.app-submission.cross-platform","true");
conf.set("yarn.app.mapreduce.am.env","HADOOP_MAPRED_HOME=/root/apps/hadoop-3.1.3");
conf.set("mapreduce.map.env","HADOOP_MAPRED_HOME=/root/apps/hadoop-3.1.3");
conf.set("mapreduce.reduce.env","HADOOP_MAPRED_HOME=/root/apps/hadoop-3.1.3");
Job job = Job.getInstance(conf);//客户端用来封装参数
// 1、封装参数:jar包所在的位置
job.setJar("F:\wcc.jar");
//通过类找jar
//job.setJarByClass(JobSubmitterWindowsToYarn.class);
// 2、封装参数: 本次job所要调用的Mapper实现类、Reducer实现类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 3、封装参数:本次job的Mapper实现类、Reducer实现类产生的结果数据的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//可能重新生成输出目录
Path output = new Path("/wordcount/output");
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"),conf,"root");
if(fs.exists(output)){
fs.delete(output, true);
}
// 4、封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); //不存在创建,存在抛异常
FileOutputFormat.setOutputPath(job, output); // 注意:输出路径必须不存在
// 5、封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(2);
// 6、提交job给yarn
boolean res = job.waitForCompletion(true);
System.exit(res?0:-1);
System.out.println("完成");
}
}
