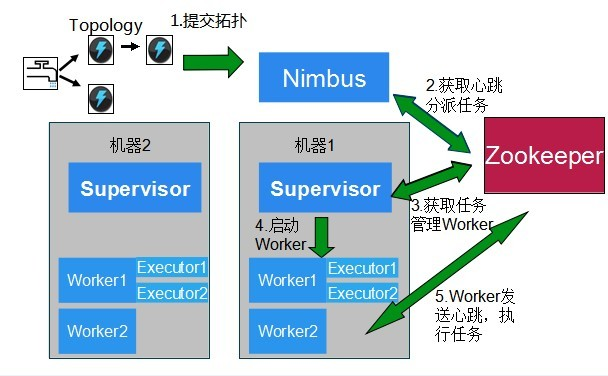
刚接触Strom,记录下执行过程
1、pom.xml


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.toda.demo</groupId> <artifactId>demo</artifactId> <version>1.0-SNAPSHOT</version> <name>demo</name> <!-- FIXME change it to the project's website --> <url>http://www.example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.9.6</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.thrift</groupId> <artifactId>libthrift</artifactId> <version>0.9.3</version> </dependency> </dependencies> <build> <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --> <plugins> <!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle --> <plugin> <artifactId>maven-clean-plugin</artifactId> <version>3.1.0</version> </plugin> <!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging --> <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.0</version> </plugin> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>2.22.1</version> </plugin> <plugin> <artifactId>maven-jar-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-install-plugin</artifactId> <version>2.5.2</version> </plugin> <plugin> <artifactId>maven-deploy-plugin</artifactId> <version>2.8.2</version> </plugin> <!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle --> <plugin> <artifactId>maven-site-plugin</artifactId> <version>3.7.1</version> </plugin> <plugin> <artifactId>maven-project-info-reports-plugin</artifactId> <version>3.0.0</version> </plugin> </plugins> </pluginManagement> </build> </project>
2、WordCountSpout.java文件
package org.toda.demo.wordcout; import java.util.Map; import java.util.Random; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.utils.Utils; //执行顺序:open() --> nextTuple() -->declareOutputFields() public class WordCountSpout extends BaseRichSpout { private Map map; private TopologyContext context; private SpoutOutputCollector collector; String text[]={ "你好 谢谢 再见", "哈哈 再见 吃饭", "再见 你好 睡觉", "上班 谢谢 辛苦", "开心" }; Random random=new Random(); @Override public void nextTuple() { Values line = new Values(text[random.nextInt(text.length)]); //发送tuple消息,并返回起发送任务的task的序列号集合 collector.emit(line); Utils.sleep(1000); System.err.println("splot----- emit------- "+line); } @Override public void open(Map map, TopologyContext context, SpoutOutputCollector collector) { //数据初始化 this.map=map; this.context=context; this.collector=collector; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { //定义元组中变量结构的名字 declarer.declare(new Fields("newFields")); } }
3WordCountBolt.java文件
package org.toda.demo.wordcout; import java.util.List; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; //执行顺序: prepare() --> execute() --> declareOutputFields() public class WordCountBolt extends BaseRichBolt { private OutputCollector collector; @Override public void execute(Tuple input) { //随机获取单行数据, //String line = input.getString(0); //也可以用下面的代码通过field获取,这里0是返回这个String的0号位置 String line=input.getStringByField("newFields"); //切分字符串单词 String[] words = line.split(" "); //向后发送tuple for(String word : words){ List w=new Values(word); collector.emit(w); } } @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { //数据初始化 this.collector=collector; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
4WordFinalBolt.java文件
package org.toda.demo.wordcout; import java.util.HashMap; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; public class WordFinalBolt extends BaseRichBolt { private OutputCollector collector; Map<String, Integer> map=new HashMap<String,Integer>(); @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector){ this.collector=collector; } @Override public void execute(Tuple input) { int count =1; //获取切分后的每一个单词 String word = input.getStringByField("word"); if(map.containsKey(word)) { count=(int) map.get(word)+1; } map.put(word, count); //输出 System.err.println(word+"============="+count); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
5、Test.java文件(main函数)
package org.toda.demo.wordcout; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; public class Test { public static void main(String[] args) { //创建一个拓扑 TopologyBuilder tb=new TopologyBuilder(); //拓扑设置 喷嘴以及个数 tb.setSpout("ws", new WordCountSpout()); //拓扑设置 Bolt以及个数,shuffleGrouping表示随机分组 tb.setBolt("wordcountbolt", new WordCountBolt(),3).shuffleGrouping("ws"); //fieldsGrouping表示按照字段分组,即是同一个单词只能发送给一个Bolt tb.setBolt("wc", new WordFinalBolt(),3).fieldsGrouping("wordcountbolt",new Fields("word") ); //本地模式,测试 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("wordconut",new Config(), tb.createTopology()); } }
总结:
从代码可看出,Spout是将数据源封装成Tuple,而Bolt主要是对Tuple进行逻辑处理,可以有多个Bolt执行,最后一个Bolt是最后所需数据。
执行过程: