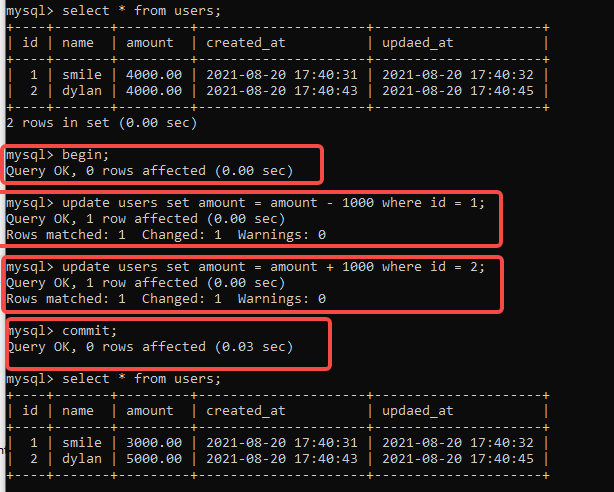
Mysql 事务说明
Mysql 事务主要用于处理:操作量大,复杂度高的数据。是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行;事务是一组不可再分割的操作集合(工作逻辑单元)
- 事务支持是在引擎层实现
- Mysql 只有使用了Innodb 数据引擎的数据,才支持事务
- 事务处理可以用来维护数据库的完整性,保存成批的SQL语句要么全部支持,要么全部不执行
- 事务用来管理(insert update delete) 语句
一般来说,事务是必须满足4个条件(ACID)
-
A (Atomicity) 原子性
一个事务要被完全的无二义性的做完或撤消。在任何操作出现一个错误的情况下,构成事务的所有操作的效果必须被撤消,数据应被回滚到以前的状态。
-
C (Consistency) 一致性
一个事务应该保护所有定义在数据上的不变的属性(例如完整性约束)。在完成了一个成功的事务时,数据应处于一致的状态。换句话说,一个事务应该把系统从一个一致状态转换到另一个一致状态。举个例子,在关系数据库的情况下, 一个一致的事务将保护定义在数据上的所有完整性约束。
-
I(Isolation) 隔离性
在同一个环境中可能有多个事务并发执行,而每个事务都应表现为独立执行。串行的执行一系列事务的效果应该同于并发的执行它们。
这要求两件事:
-
在一个事务执行过程中,数据的中间的(可能不一致)状态不应该被暴露给所有的其他事务。
-
两个并发的事务应该不能操作同一项数据。数据库管理系统通常使用锁来实现这个特征。
-
-
D (Durability) 持久性
一个被完成的事务的效果应该是持久的。
Mysql事务执行
-
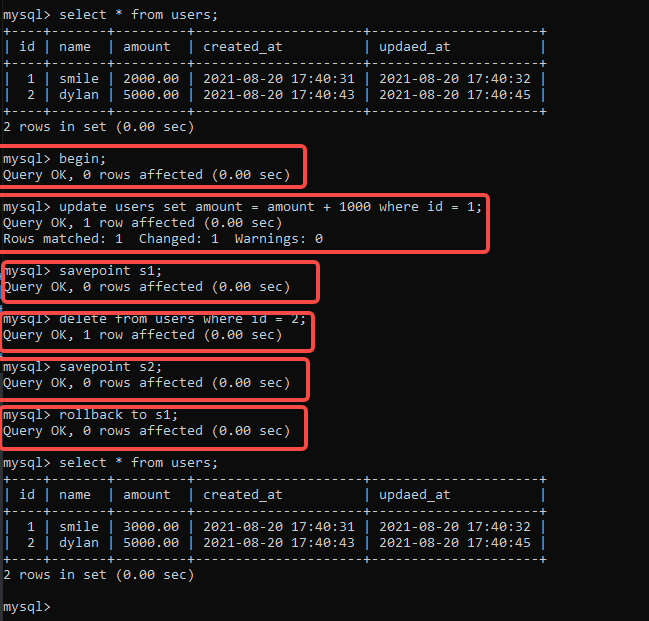
开启事务( 显示的开启一个事务)
BEGIN ; START TRANSACTION; -
提交事务( 提交事务,并使已对数据库进行的修改成永久性的)
COMMIT; COMMIT WORK: -
回滚事务(回滚并且结束事务,撤销正在进行的所有未提交的修改)
ROLLBACK; ROllback WORK -
创建一个保存点
SAVEPOINT identifier; -
删除事务保存点
RELEASE SAVEPOINT identifie; -
回滚指定大标记点
ROLLBACK TO identifier;
Mysql 事务的基本使用
显式事务:数据提交
SET AUTOCOMMIT = 0 # 设置自动提交
[START TRANSACTION] # 开启事务
[DELETE | UPDATE | INSERT | SELECT ] # DML、DQL操作
[COMMIT | ROLLBACK]; #提交或者回滚
显式事务:回滚点使用
SET AUTOCOMMIT=0; # 设置自动提交
START TRANSACTION; # 开启事务
[DELETE | UPDATE | INSERT | SELECT]; #回滚时要执行提交的部分
SAVEPOINT a; # 设置回滚点,且变量名为a
[DELETE | UPDATE | INSERT | SELECT]; #回滚时不执行提交的部分
ROLLBACK TO a; # 回滚时与ROLLBACK TO搭配使用
注意:在事务中使用truncate时,就算rollback也会清空整张表
查看隔离级别
- READ UNCOMMITTED (读未提交)
- READ COMMITTED (读已提交)
- REPEATABLE READ (可重复读)默认
- SERIALIZABLE (串行)
设置隔离级别,此语句为当前会话或下一个事务全局设置事务隔离级别:使用 GLOBAL 关键字,该语句为所有后续会话全局设置默认事务级别。现有会话不受影响。使用 SESSION 关键字,该语句为当前会话中执行的所有后续事务设置默认事务级别。没有任何 SESSION 或 GLOBAL 关键字,该语句为当前会话中执行的下一个(未启动)事务设置隔离级别。
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL
{
READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SERIALIZABLE
}
查看隔离级别
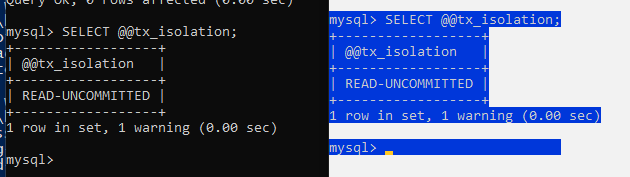
SHOW variables LIKE "tx_isolation";
SELECT @@tx_isolation;
设置MYSQL的自动提交模式
SET AUTOCOMMIT = 0; #禁止自动提交
SET AUTOCOMMIT = 1; #开启自动提交
事务的隔离级别
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
事务不同隔离级别,出现的异常
创建2个mysql客户端,并创建一张测试表 users,其中黑色表示T1事务,蓝色表示T2事务
- 脏读(Dirty Read)
对于两个事务T1与T2,T1读取了已经被T2更新但是还没有提交的字段之后,若此时T2回滚,T1读取的内容就是临时并且无效的
更改默认的隔离级别REPEATABLE READ 为 READ UNCOMMITTED
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; #更改隔离级别
SELECT @@tx_isolation; #查询隔离级别
两个客服端同时开启事务,T1 事务UPDATE T2事务 SELECT
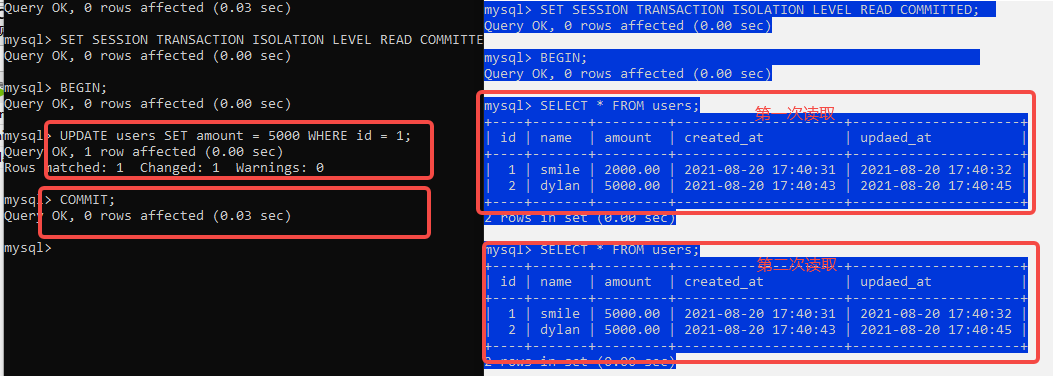
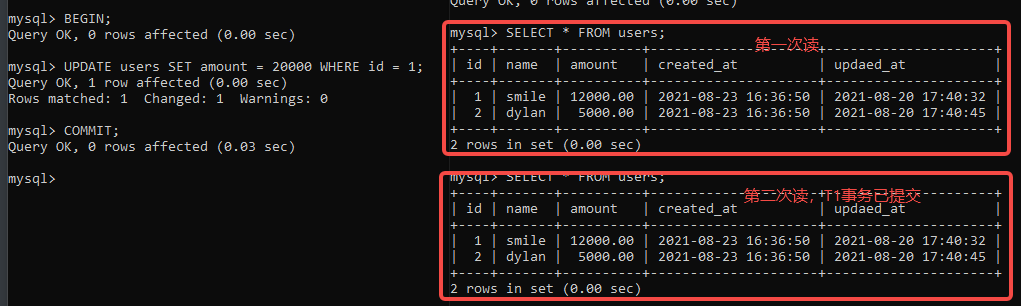
假如此时,T1 事务进行ROLLBACK,那么T2 事务读取的数据是临时,且无效的
解决方案
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; #更改隔离级别为READ COMMITTED
T1 事务更改数据后,但是未提交,T2 不读取未提交的更改
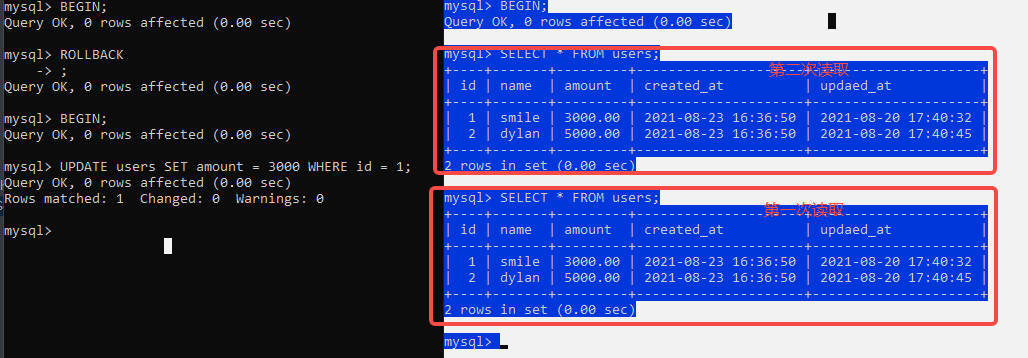
- 不可重复读(NonRepeatable Read),可以解决脏读。
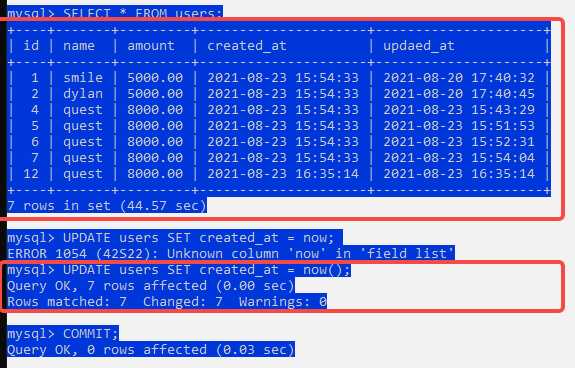
对于两个事务T1和T2,T1读取了一个字段,然后T2更新了该字段并提交之后,T1再次提取同一个字段,值便不相等了
更改默认的隔离级别REPEATABLE READ 为 READ UNCOMMITTED
SELECT @@tx_isolation; #查询隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; #更改隔离级别
T2 事务 两次读取数据不一致。
解决方案
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; #更改隔离级别为REPEATABLE READ
-
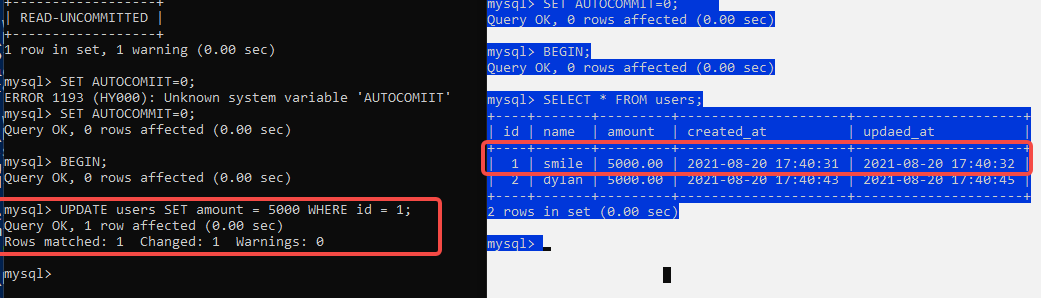
幻读
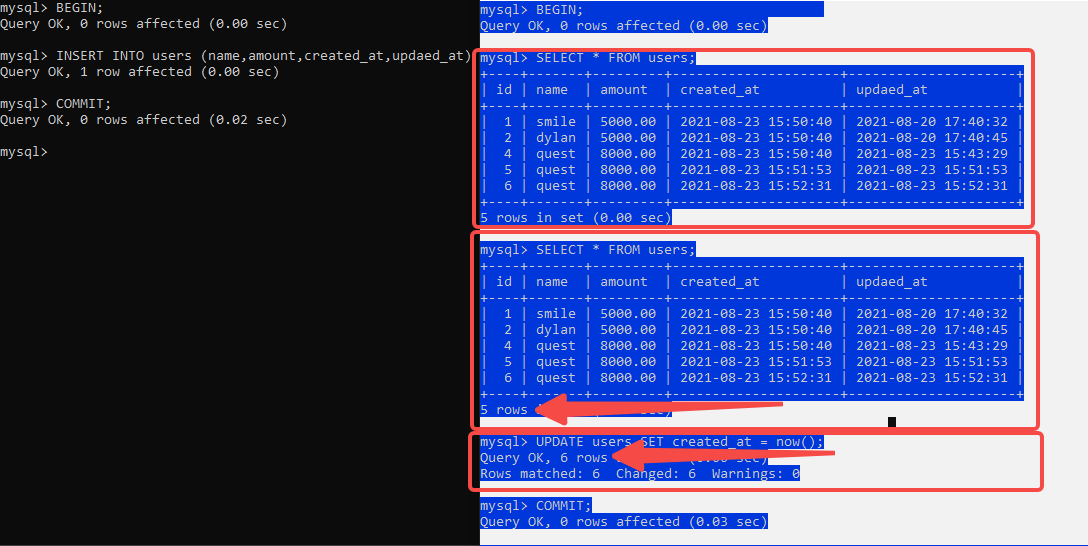
对于两个事务T1、T2,T1从表中读取数据,然后T2进行了INSERT操作并提交,当T1'再次读取的时候,结果不一致的情况发生。
更改默认的隔离级别REPEATABLE READ 为 REPEATABLE READ
SELECT @@tx_isolation; #查询隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; #更改隔离级别
T2 事务 查询和更新的条数不一致
解决方案
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; #更改隔离级别为SERIALIZABLE
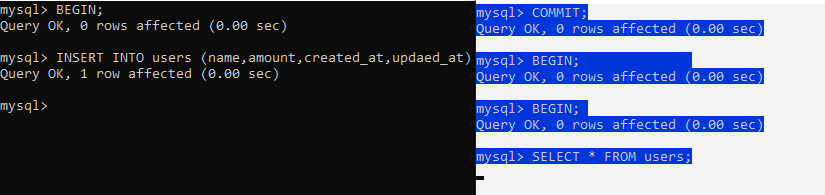
当T1事务执行INSERT 操作的时,T2事务的查询等待。直到T1事务完成,T2事务再查询数据
serializable 会完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止。是完整的隔离级别,会锁定对应的数据表格,因而会有效率的问题。