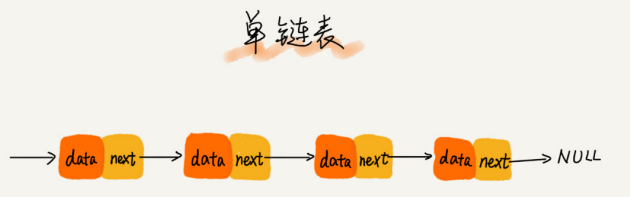
链表
链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示,我们把这个记录下个结点地址的指针叫作后继指针 next。
链表分类

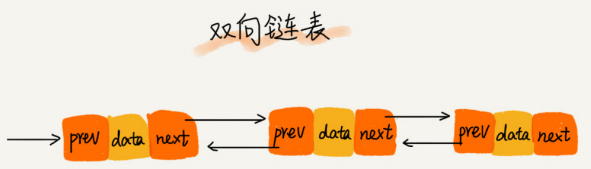
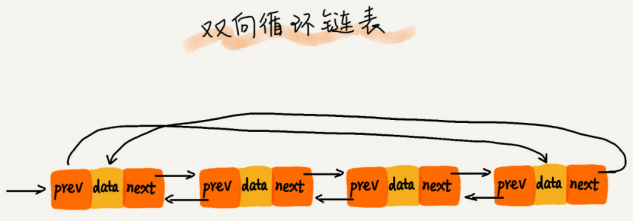
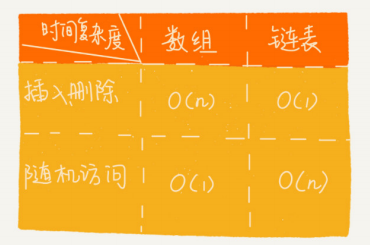
链表和数组对比
1:存储空间
数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。
而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,根本不会有问题。
2:CPU缓存
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。
而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读
3:扩容
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。
链表本身没有大小的限制,天然地支持动态扩容,这也是它与数组最大的区别。
4:操作性能
链表使用
1、理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
在编写链表代码的时候,我们经常会有这样的代码:p->next=q。这行代码是说,p 结点中的next 指针存储了 q 结点的内存地址。
2、警惕指针丢失和内存泄漏
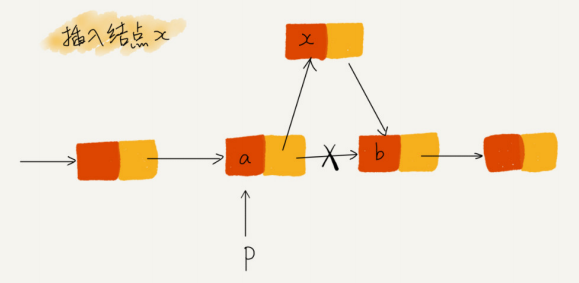
我们希望在结点 a 和相邻的结点 b 之间插入结点 x,假设当前指针 p 指向结点 a。如果我们将代码实现变成下面这个样子,就会发生指针丢失和内存泄露。

此时,p->next 指针在完成第一步操作之后,已经不再指向结点 b 了,而是指向结点 x。第 2 行代码相当于将 x 赋值给 x->next,自己指向自己。因此,整个链表也就断成了两半,从结点 b 往后的所有结点都无法访问到了。
所以,我们插入结点时,一定要注意操作的顺序,要先将结点 x的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏。所以,对于刚刚的插入代码,我们只需要把第 1 行和第 2 行代码的顺序颠倒一下就可以了。
3、利用哨兵简化实现难度
如果我们在结点 p 后面插入一个新的结点,只需要下面两行代码就可以搞定。

如果要删除结点 p 的后继结点,我们只需要一行代码就可以搞定。

但是,当我们要向一个空链表中插入第一个结点,或者要删除链表中的最后一个结点,前面的删除代码就不 work 了,需要进行下面的特殊处理:


针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。这样代码实现起来就会很繁琐,不简洁,而且也容易因为考虑不全而出错。这个时候就需要借助哨兵来简化操作。
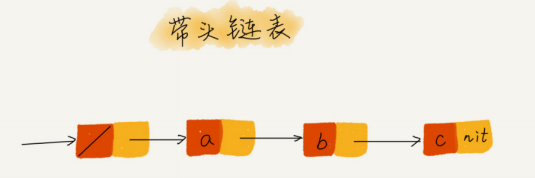
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。
4、重点留意边界条件处理
经常用来检查链表代码是否正确的边界条件有这样几个:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?