InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。在数据库系统中,由于CPU速度和磁盘速度之前的鸿沟,通常使用缓冲池技术来提高数据库的整体性能。
1. Innodb_buffer_pool
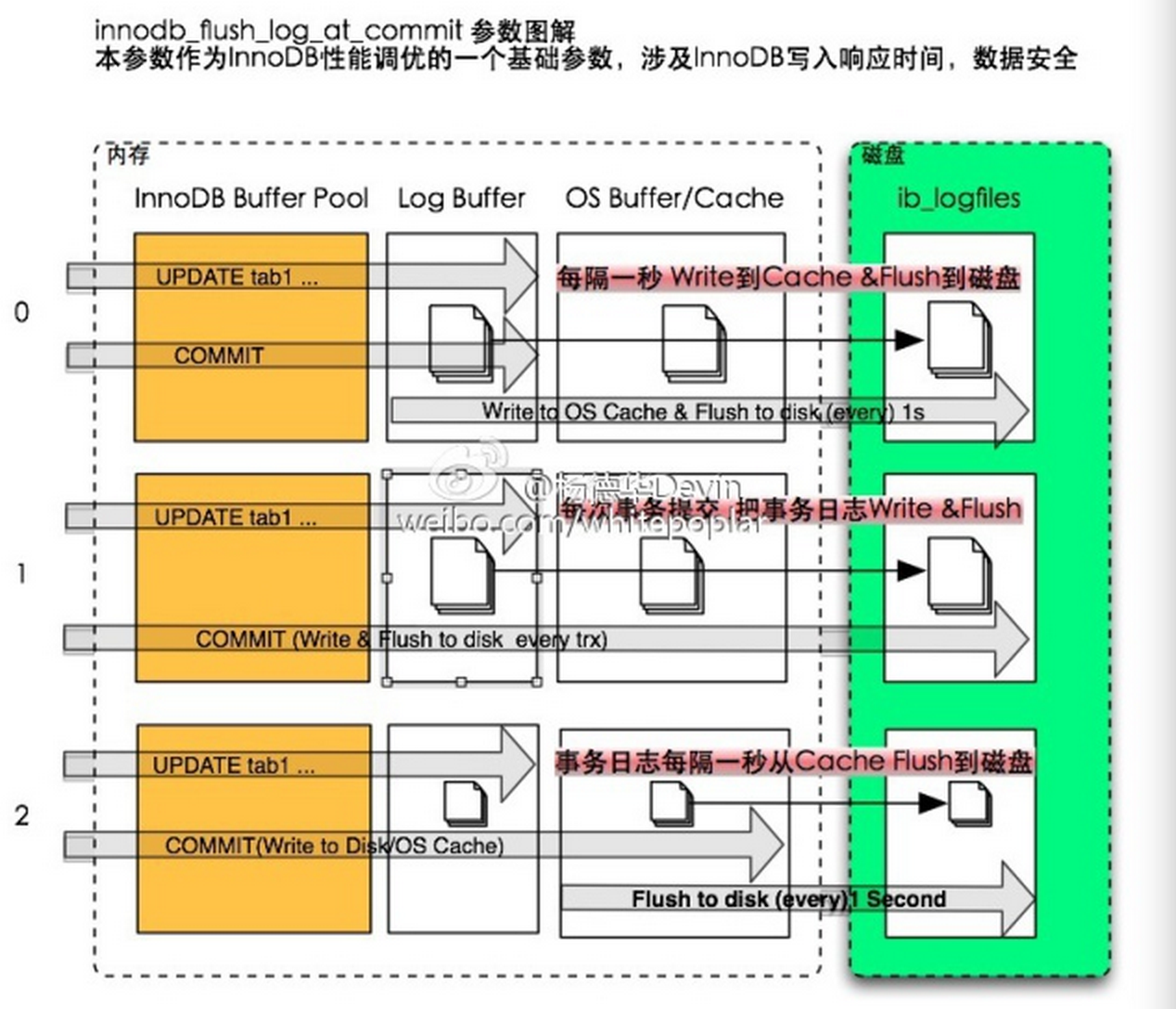
缓冲池(buffer pool)简单来说就是一块内存区域。缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲、自适应哈希索引、InnoDB存储的锁信息、数据字典信息等。不能简单认为,缓冲池只是缓存索引页和数据页,它们只是占缓冲池很大的一部分而已。
在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,下一次再读相同的页时,首先判断该页是否在缓冲池中。若在,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘中的页。
root@rac3 mysql> show global status like 'Innodb_buffer_pool_%'; +---------------------------------------+--------+ | Variable_name | Value | +---------------------------------------+--------+ | Innodb_buffer_pool_pages_data | 1118 | | Innodb_buffer_pool_pages_dirty | 0 | | Innodb_buffer_pool_pages_flushed | 1950 | | Innodb_buffer_pool_pages_free | 129951 | | Innodb_buffer_pool_pages_misc | 3 | | Innodb_buffer_pool_pages_total | 131072 | | Innodb_buffer_pool_read_ahead_rnd | 0 | | Innodb_buffer_pool_read_ahead | 311 | | Innodb_buffer_pool_read_ahead_evicted | 0 | | Innodb_buffer_pool_read_requests | 202858 | | Innodb_buffer_pool_reads | 756 | | Innodb_buffer_pool_wait_free | 0 | | Innodb_buffer_pool_write_requests | 43825 | +---------------------------------------+--------+ 13 rows in set (0.00 sec)
从上面的值我们可以看出总共 131072 pages,还有 129951 是 Free 状态的,仅仅只有 1118 个 page 有数据, read 请求 202858 次,其中有 756 次所请求的数据在 buffer pool 中没有,也就是说有 756 次是通过读取物理磁盘来读取数据的,所以很容易也就得出了 Innodb Buffer Pool 的 Read 命中率大概在为:(202858 - 756)/ 202858 * 100% 。
Innodb 在修改数据的时候同样也只是修改 buffer pool中的数据,并不是在一个事务提交的时候就将buffer pool中被修改的数据同步到磁盘,而是通过另外一种支持事务的数据库系统常用的手段,将修改信息记录到相应的事务日志中。
我们的应用所修改的buffer pool中的数据都很随机,每次所做的修改都是一个或者少数几个数据页,多次修改的数据页也很少会连续。如果我们每次修改之后都将buffer pool的数据同步到磁盘, 那么磁盘就只能一直忙于频繁的随机读写操作。而事务日志在创建之初就是申请的连续的物理空间,而且每次写入都是紧接着之前的日志数据顺序的往后写入,基本上都是一个顺序的写入过程。所以,日志的写入操作远比同步buffer pool中被修改的数据要更快。
2. redo log_buffer
事务日志本身也有 buffer,也就是redo log_buffer,每次事务日志的写入并不是直接写入到文件,也都是暂时先写入到 redo log_buffer中,然后再在一定的事件触发下才会同步到文件。
 事务日志文件的大小与 Innodb 的整体IO性能有非常大的关系。理论上来讲,日志文件越大,则buffer pool所需要做的刷新动作也就越少,性能也越高。但是,我们也不能忽略另外一个事情,那就是当系统Crash之后的恢复。
事务日志文件的大小与 Innodb 的整体IO性能有非常大的关系。理论上来讲,日志文件越大,则buffer pool所需要做的刷新动作也就越少,性能也越高。但是,我们也不能忽略另外一个事情,那就是当系统Crash之后的恢复。
Innodb中记录了每一次对数据库中的数据及索引所做的修改,以及与修改相关的事务信息。同时还记录了系统每次 checkpoint 与 log sequence number(日志序列号)。假设在某一时刻,MySQL Crash了,那么很显然,所有buffer pool中的数据都会丢失,也包括已经修改且没有来得及刷新到数据文件中的数据。难道我们就让这些数据丢失么?当然不会,当MySQL从Crash之后再次启动,Innodb会通过比较事务日志中所记录的checkpoint信息和各个数据文件中的checkpoint信息,找到最后一次checkpoint所对应的log sequence number,然后通过事务日志中所记录的变更记录,将从Crash之前最后一次checkpoint往后的所有变更重新应用一次,同步所有的数据文件到一致状态,这样就找回了因为系统Crash而造成的所有数据丢失。当然,对于log buffer中未来得及同步到日志文件的变更数据就无法再找回了。系统Crash的时间离最后一次checkpoint的时间越长,所需要的恢复时间也就越长。而日志文件越大,Innodb所做的checkpoint频率也越低,自然遇到长时间恢复的可能性也就越大了。
2.1 checkpoint
在InnoDB存储引擎中,可能发生如下几种情况的Fuzzy Checkpoint:
(1)Master Thread Checkpoint
对于Master Thread中发生的checkpoint,差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘。这个过程是异步的,即此时InnoDB存储引擎可以进行其他的操作,用户查询线程不会阻塞。
(2)FLUSH_LRU_LIST Checkpoint
InnoDB存储引擎需要保证LRU列表中需要有差不多100个空闲页可供使用。若没有100个空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除。如果这些页中有脏页,那么需要进行checkpoint。这些页是来自LRU列表的,因此称为FLUSH_LRU_LIST Checkpoint。
(3)Async/Sync Flush Checkpoint
Async/Sync Flush Checkpoint是为了保证redo log的循环使用可用性。
(4)Dirty Page too much Checkpoint
脏页的数量太多,导致InnoDB存储引擎强制进行Checkpoint。可由参数innodb_max_dirty_pages_pct控制。
root@rac3 mysql> show variables like 'innodb_max_dirty_pages_pct'G *************************** 1. row *************************** Variable_name: innodb_max_dirty_pages_pct Value: 85 1 row in set (0.00 sec)
innodb_max_dirty_pages_pct的值为85,表示当缓冲池中脏页的数量占据85%时,强制进行checkpoint,刷新一部分的脏页到磁盘。
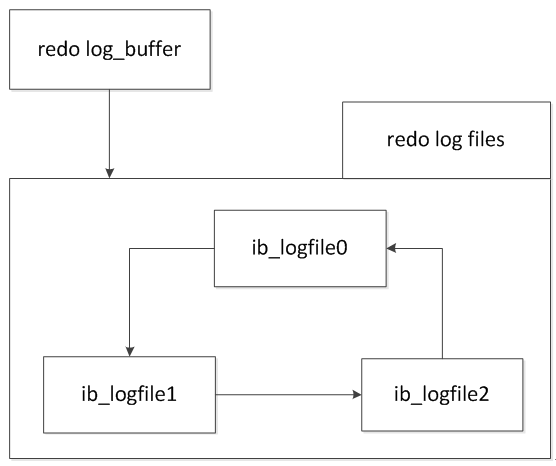
2.2 innodb_flush_log_at_trx_commit
参数innodb_flush_log_at_trx_commit用来控制事务日志刷新到磁盘的策略。
默认innodb_flush_log_at_trx_commit=1,表示在每次事务提交的时候,都把log buffer刷到文件系统中去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。这样的话,数据库对IO的要求就非常高了,如果底层的硬件提供的IOPS比较差,那么MySQL数据库的并发很快就会由于硬件IO的问题而无法提升。为了提高效率,保证并发,牺牲一定的数据一致性。innodb_flush_log_at_trx_commit还可以设置为0和2。
innodb_flush_log_at_trx_commit=0时,提交事务时并不将log buffer写入磁盘,而是等待主线程每秒的刷新。
innodb_flush_log_at_trx_commit=2时,事务提交时将事务日志写入redo log file,但仅写入文件系统的缓存,不进行fsync操作。在这个设置下,当MySQL数据库发生宕机而操作系统不发生宕机,并不会导致事务的丢失。