Week1
引言
-
什么是scaling up ,什么是Scaling out?
scaling up又称为纵向扩展,是扩大机器的容量,scaling out又称为水平扩展,是把数据存储到多个节点 -
hdfs中的节点都有什么角色?
- NameNode
- DataNode -
hdfs上的数据存放是怎么存的?
同一机器上的数据,距离为0
同一机架上的数据,距离为2
同一机房的其他机架数据,距离为4
其他机房,距离为6 -
chunk/block size是什么?
-
hdfs的客户端是怎么读写数据的?
客户端先访问namenode,获取数据存在哪个datanode上,再从datanode读写 -
GFS文件系统的三大主要内容
- components failures are a norm (→ replication)
- even space utilisation
- write-once-read-many
Block,Replica State,Recovery Process
- 什么是Replica
Replica是DataNode中存储数据的单位,在DataNode上有很多Replica
-Replica的常见状态
- Finalized ,处于finalized状态的replica已经完成了其所有字节的写,replica的内容和长度都已固定,除非此replica响应append事件来reopen继续追加写,否则此replica不会被写入新的字节。并且,这种类型的replica其真实的replica data和meta data是相匹配的。此replica的存储在其余DN的备份也有着相同的block id和字节。但是有一点需要注意,这种replica的时间戳GS(generation stamp)不是一成不变的,当进行错误块恢复的时候,有可能会发生变化(变为块恢复时的时间)。
- RBW ,RWB是Replica Being Written to的缩写,一旦一个replica被创建或者之前的replica被追加数据,那么此replica就会变为RWB状态,这意味着这个replica正在被写入数据(是现在进行时哦,亲!)。这个块通常是一个正在被操作的文件(文件流未被关闭)的最后一个块。正因为处在“被写入数据”的状态,所以此replica的长度还未 确定,并且存储在磁盘上的此块的replica data和meta data也不一定是匹配的。此块的存储在其余DN上的replica可能有着不同的字节内容和长度。但是,此块的数据还是能够被reader看到的(读到的不一定是所有的数据)。为了防止意外,处于RWB状态的replica也要尽可能的持久化。
- RWR是Replica Waiting to be Recovered的缩写,当DN死掉或者重启的时候,所有上述属于RBW状态的replica都会变成RWR状态。RWR状态的replica不会出现在传输数据的pipeline(通道,读和写等操作中,用此来进行传输block)中,因此也不会接收任何新的字节写入。这些状态的replica最终要么变为过期的数据,要么当客户端挂掉的时候参与到租约恢复中去
- 当一个租约(客户端向NN申请的对一个文件的控制)过期并且发起包括此replica的块恢复机制之后,这个replica就会变为RUR状态,RUR就是Replica Under Recovery的缩写。
- 顾名思义,这个Temporary的replica就是处于under construction的块,它是当块复制或者集群做均衡操作时创建的临时块。这种状态的块和RBW状态的块有很多类似的地方,但是有一点显著的不同,就是其数据是不能被reader看到的。当块创建失败或者DN重启的时候,此状态的replica都会被删除掉。
-在DN端的硬盘存储的层次上,有三个子目录:current、tmp、rbw。current用来存储处于finalized状态的replica,tmp用来存储temporary状态的replica,rbw用来存储rbw、rur、rwr状态的replica。并且:
(1)当块被客户端请求首次创建的时候,会被放入rbw目录下;
(2)当块是因为复制或者均衡操作被创建的时候,会被放入tmp目录;
(3)一旦一个块被finalized,就被移动到current目录;
(4)当数据节点重启时,tmp目录下的replica就被清空,rbw目录下的replica就转变为rwr状态,current目录下的replica变为finalized状态;
(5)当DN升级的时候,current和rbw目录下的块都会被保存在快照中。
!()[https://images0.cnblogs.com/blog/392365/201305/30200928-0ede4fa514444ef6bcfd5ff4e4870cdb.jpg]
-
什么是Block
Block是NameNode中的单位,存储着管理DataNode的信息(位置,状态等) -
Block的状态保存在内存中
-
UnderConstruction状态
一旦一个块被创建或者被追加数据,就会处于underConstruction状态,此时,数据库正在被写入新的数据。这样的块是当前正处于被写状态的文件的的最后一个块。它的块长度和GS都还没有最终确定,同DN端的rwb状态一样,此数据块对reader来说是可见的。并且,此类型的块还会保持对写入其本身的数据通道和对应的RWR状态的replica的追踪,以防Client挂掉。 -
UnderRecovery状态
当一个文件的租约过期时,如果此文件的最后一个block处于underConstruction状态,此块就会当块恢复开始的时候变为underRecovery状态。 -
Committed状态
一个处于committed状态的block,其内容和时间戳GS都已经确定,但是在DN中还没有一个replica和此committed的block有着相同的字节和GS。除非进行append追加操作,否则此committed状态的block的字节和GS都不会再发生变化。为了响应reader的请求,committed状态的block仍然会持有rbw状态的replica的地址和追踪已经变为finalized状态的replica的长度和GS。当客户端调用NN的close file或add new block时,操作流未关闭的文件的处于underConstruction状态的replica会被转变为committed状态。如果最后一个block处于committed状态,那么此block对应的文件是无法被关闭的,客户端必须要重试。AddBlock和close将会扩展到包含最后一个block的GS和长度。 -
Complete状态
一个处于complete状态的block,其长度和GS都是确定的,并且NN能够找到DN端GS和长度都对应的处于finalized状态的replica。Complete状态的block值会保持finalized状态的replica的地址。只有当所有的块都变为complete状态了,对应的文件才能被关闭。
和DN端的replica的状态不同,NN端的block的状态不会被持久化到磁盘上,当NN重启的时候,未关闭的文件的最后一个block会变为underConstruction状态,其余的块都变为complete状态。
!()[https://images0.cnblogs.com/blog/392365/201305/30200957-c1463d3c038746df8e3eb860389e05db.jpg]
- 恢复过程
- 租约恢复,客户端向hdfs写入时,hdfs维护一个租约,本质上是一把写锁,只允许一个客户端写入。并且会不时的确认租约的存活,客户端是否挂掉。写入完成后才释放锁,别的客户端才可以继续写。这意味着同一时间只有一个客户端可以写数据
- Block恢复,Block恢复只会发生在租约恢复的期间。在pipeline把数据写入不同的DataNode时,最后一个正在被写入的Repilca的数据并不一定一致,为了保证一致性,如果此时文件的写操作被租约关闭以外的操作关闭,就需要进行Block恢复。
- pipeline恢复,在pipeline之间的数据进行写操作时,可能出现错误,此时需要对pipline进行恢复
小结:
-
画出replica和block的状态图
-
解释write pipeline的各个阶段(请结合recovery process)
-
recovery process都有哪些?它们的目的分别是什么?
-
HDFS 客户端
hdfs dfs -ls -R -h path/to/target# 同ls命令,此处列出的大小是单个replica的,并没有翻倍
hdfs dfs du -h path /to/target# 列出总大小,算上了重复的replica
·hdfs dfs df -h ` # 查看系统储存空间使用情况
hdfs dfs mkdir -p dir/to/make
hdfs dfs rm -r
hdfs dfs touchz
hdfs dfs get/put/getmerge/copy
hdfs dfs setrep #设置replica factor
hdfs fsck /path/to/target -files -blocks locations #(file system check)
hdfs fsck -blockid xxx
hffs dfs find
WEBUI和RESTAPI
- NameNode50070端口
- 在WEBUI上可以看到
- 权限
- blockID
- gsstamp
- bloopoolID #其实就是启动了联邦模式的多名称空间的id - 联邦模式
1、由于单组Namenode在大规模集群中存在较大的局限性,Hadoop开源社区提供了Federation的方案,由多组Namenode在一个集群中共同提供服务,每个Namenode拥有一部分Namespace,工作互相独立,互不影响。
2、在Federation中,Datanode被用作通用的数据块存储设备,每个DataNode要向集群中所有的Namenode注册,且周期性的向所有Namenode发送心跳和块报告,并执行来自所有Namenode的命令。
NameNode的结构
- 假设有10PB的数据要存
- 每个硬盘是2T,每天有15个硬盘会挂掉
- namenode储存的对象需要150B,并且储存在内存中
- 那么需要的硬盘是 : 10PB/2TB *3
- 需要的内存: 10PB/128MB *150b ≈ 3.9GB - NamdeNode使用WAL(write ahead log)机制保障namenode的数据不丢失
- edit log 被复制到不同的硬盘上,保障metainfo不丢失
- fsimage保存内存状态的快照
- 这个机制恢复namenode需要太多的时间,于是发明了Secondary NameNode,sencondary namenode会从namenode获取fsimage和editlog
小结:
-总结并解释NameNode的结构(editlog和fsimage;RAM)
- 估计hdfs集群需要多少资源
- 小文件问题是什么,它的瓶颈是什么?
HDFS的文件存储
不同格式的存储在以下方面有差异:
- 空间效率 space efficiency
- 编码解码速度 encoding & decoding speed
- 支持的数据类型 supported data types
› splittable/monolithic structure - 扩展性 extensibility # 有的格式不支持加列
文本类型
- 常见,人可读,易于生成,易于解析
- 占据的存储空间大
- CSV, TSV, JSON, XML 都是常见的文本类型
- 扩展性不好
文本
二进制文件
SequenceFile
行存格式
- HDFS上的第一个二进制格式
- 储存着key-value的序列
- Java实现的序列化反序列化
- 包含header,metadata,等
- 有3种格式
- 经过block压缩的格式有两种:经过record压缩和未经过record压缩
- 未经过block压缩 - 特点
- 空间效率适中
- 速度快
- 数据类型:Java编程中的数据类型
- 能否拆分:可以
- 扩展性:不可扩展
Avro
-
是格式,也是库
-
用定义好的schema储存对象
- 制定field name,types,alias
- 制定序列化/反序列化的代码
- 可以更新schema -
支持多语言
-
组成:包含header,bloak等,区别的SequenceFile的点在于它的schema是通过schema定义的,而SeqenceFile是用户代码
-
特性:
- 空间效率适中到好
- 速度快
- 数据类型:类json
- 能否拆分:可以
- 扩展性:可扩展
列存格式
-
RCfile
- HDFS的第一个列存格式
- 水平/垂直分区
- 把row分成row group
- 三部分组成:16 Byte Sync,meatadata,column data- 空间效率高 - 速度中等到快,有更少的IO - 数据类型:byteString,与Hive结合使用,Hive进行序列化反序列化,所以格式本身不序列化 - 能否拆分:可以 - 扩展性:不可扩展 -
Parquet
- 存在很有列优化
小结:
- SequenceFile适用于Java开发
- Avro可以在很多场合适用
- Rcfiles/ORC/Parquet适用于宽表,数据仓库
Compression
- block级别的压缩
- Rcfile,parquet,Sequencefile - 文件级别的压缩
- 能在文件内导航
各种类型的文件压缩的数据:
-
Gzip
- compression speed ~16-90 MiB/s
- decompression speed ~250- 320 MiB/s
- ratio ~2.77 .. 3.43 -
Bzip2
- compression speed ~12-14MB/s
- decompression speed ~38-42MiB/s
- ratio ~4.02 .. 4.80 -
LZO
- compression speed ~77-150 MiB/s
- decompression speed ~290-314 MiB/s
- ratio ~2.10 .. 2.48 -
Snappy
- compression speed ~200 MiB/s
- decompression speed ~475 MiB/s
- ratio ~2.05 -
Bzip2最慢,也最省空间;Snappy最快,不省空间
什么时候使用压缩?
- 压缩是需要CPU进行计算的,如果HDFS能处理100MB/s,CPU只能处理100MB/s,说明瓶颈在CPU;如果CPU能处理1000MB/s,那么瓶颈就在IO;此时选择压缩率为5的话,100MB/s * 5 = 500MB/s也未能完全利用CPU的计算能力
小结
- 文件格式有哪些
- 各有什么优缺点
- 什么时候使用压缩?
Leslie Lamport 分布式系统图灵奖获得者
时钟同步:
绝对同步
相对同步
同步系统/异步系统
两类:
fail stop perfect link synchronous
fail recovery fair loss link asynchronous
大数据系统属于第二类
MapReduce
Map:
对每一个元素执行相同操作
Reduce
对所有元素依次执行操作
Shuffle
例子:
分布式的linux命令:
grep:map使用grep,没有reduce
head:都没有
wc:map使用wc,reduce使用sum
容错机制
- Mapper和Reducer挂了会发生什么?
Master会自动把任务分配到好的节点去。 - Hadoop v1和Tracker和Tracer是什么?Yarn中的ResourceManager和NodeManager呢?
- 首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
- TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
- TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上.
NodeManager管理资源,包括磁盘,CPU等,提供容器
ResourceManger申请资源
MapReduce和分布式Shell
Leslie Lamport 分布式系统图灵奖获得者
MapReduce
Map:
对每一个元素执行相同操作
Reduce
对所有元素依次执行操作
Shuffle
例子:
分布式的linux命令:
grep:map使用grep,没有reduce
head:都没有
wc:map使用wc,reduce使用sum
Streaming
HDFS支持自定义steaming的函数,例子:

Combiner:在map阶段提前进行一次聚合,减少IO
Patitioner:
决定哪些数据被分到哪些reducer,默认是hash,可以继承petitioner自己实现
Comparator:
自定义比较的函数
优化MR任务:speculative execution/back up tasks
通过compression优化
Hive
- Apache HTTP 服务器的日志都有哪些字段?
127.0.0.1 - - [01/Aug/1995:00:00:01 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1839
一个详细一些的字段说明如下:
127.0.0.1
第一项 ,发起请求的客户端IP地址。
第二项 ,空白,用占位符“-”替代,表示所请求的信息(来自远程机器的用户身份),不可用。
第三项,空白,表示所请求的信息(来自本地登录的用户身份),不可用。
[01/Aug/1995:00:00:01 -0400]
第四项,服务器端处理完请求的时间,具体细节如下:
[day/month/year:hour:minute:second timezone]
day = 2 digits
month = 3 letters
year = 4 digits
hour = 2 digits
minute = 2 digits
second = 2 digits
zone = (+ | -) 4 digits
"GET /images/launch-logo.gif HTTP/1.0"
第五项,客户端请求字符串的第一行,包含3个部分。1)请求方式 (e.g., GET, POST,HEAD 等.), 2)资源,3)客户端协议版本,通常是HTTP,后面再加上版本号
200
第六项,服务器发回给客户端的状态码,这个信息非常有用,它告诉我们这个请求成功得到response(以2开头的状态码),重定向(以3开头的状态码),客户端引起的错误(以4开头的状态码),服务器引起的错误(以5开头的状态码)。更多的信息可以查看([RFC 2616]).
1839
第七项,这个数据表明了服务器返回的数据大小(不包括response headers),当然,如果没有返回任何内容,这个值会是”-” (也有时候会是0).
- 使用HiveQL解决业务问题
DDL和DML
DDL和大多数数据库相同,不同之处在于:
1.外部表和内部表
内部表和外部表的区别:
1)概念本质上
内部表数据自己的管理的在进行表删除时数据和元数据一并删除。
外部表只是对HDFS的一个目录的数据进行关联,外部表在进行删除时只删除元数据, 原始数据是不会被删除的。
2)应用场景上
外部表一般用于存储原始数据、公共数据,内部表一般用于存储某一个模块的中间结果数据。
3)存储目录上
外部表:一般在进行建表时候需要手动指定表的数据目录为共享资源目录,用lication关键字指定。
内部表:无严格的要求,一般使用的默认目录。
2.数据类型
Hive可以保存复合类型的数据,包括Array,Map,Structure等复合类型:
CREATE EXTERNAL TABLE tab_dataset (
first_column STRING,
second_column STRING,
value INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '�01'
COLLECTION ITEMS TERMINATED BY '�02'
MAP KEYS TERMINATED BY '�03'
LINES TERMINATED BY '
'
STORED AS file_format
LOCATION '/user/adral/course2/week1/tab_dataset/';
// file_format 的类型 见本文

- 如何配置Hive的元数据?
• - Hive Service的APi有哪些?
(来自文档)- API categories
- Operation based APIs
- Query based APIs - Available APIs
- HCatClient (Java)
- HCatalog Storage Handlers (Java)
- HCatalog CLI (Command Line)
- Metastore (Java)
- WebHCat (REST)
- Streaming Data Ingest (Java)
- Streaming Mutation (Java)
- hive-jdbc (JDBC)-
-使用"explain"获取Hive表相关的信息
- API categories
- Hive是如何序列化反序列化的?
序列化是对象转换为字节序列的过程。 反序列化是字节序列恢复为对象的过程。 对象的序列化主要有两种用途:对象的持久化,即把对象转换成字节序列后保存到文件中;对象数据的网络传送。 除了上面两点, hive的序列化的作用还包括:Hive的反序列化是对key/value反序列化成hive table的每个列的值。Hive可以方便的将数据加载到表中而不需要对数据进行转换,这样在处理海量数据时可以节省大量的时间。
Spark
RDD
- Resilient — able to withstand failures
- Distributed — spanning across multiple machines
- Formally, a read-only, partitioned collection of records
To adhere to RDD interface, a dataset must implement:
- partitions() Array[Partition] # 一般hdfs的一个block就刚好对应一个partition
- iterator(p: Partition, parents: Array[Iterator]) Iterator
- dependencies() Array[Dependency]
transaction是lazy的,直到数据被请求才会实际进行处理
常用的transformation:
groupByKey
reduceByKey
cogroup
join
leftOuterJoin
rightOuterJoin
fullOuterJoin
宽依赖
窄依赖
术语
Actions->Jobs-> stages-> tasks
Spark执行的SparkContext管理着actions jobs stages tasks关系
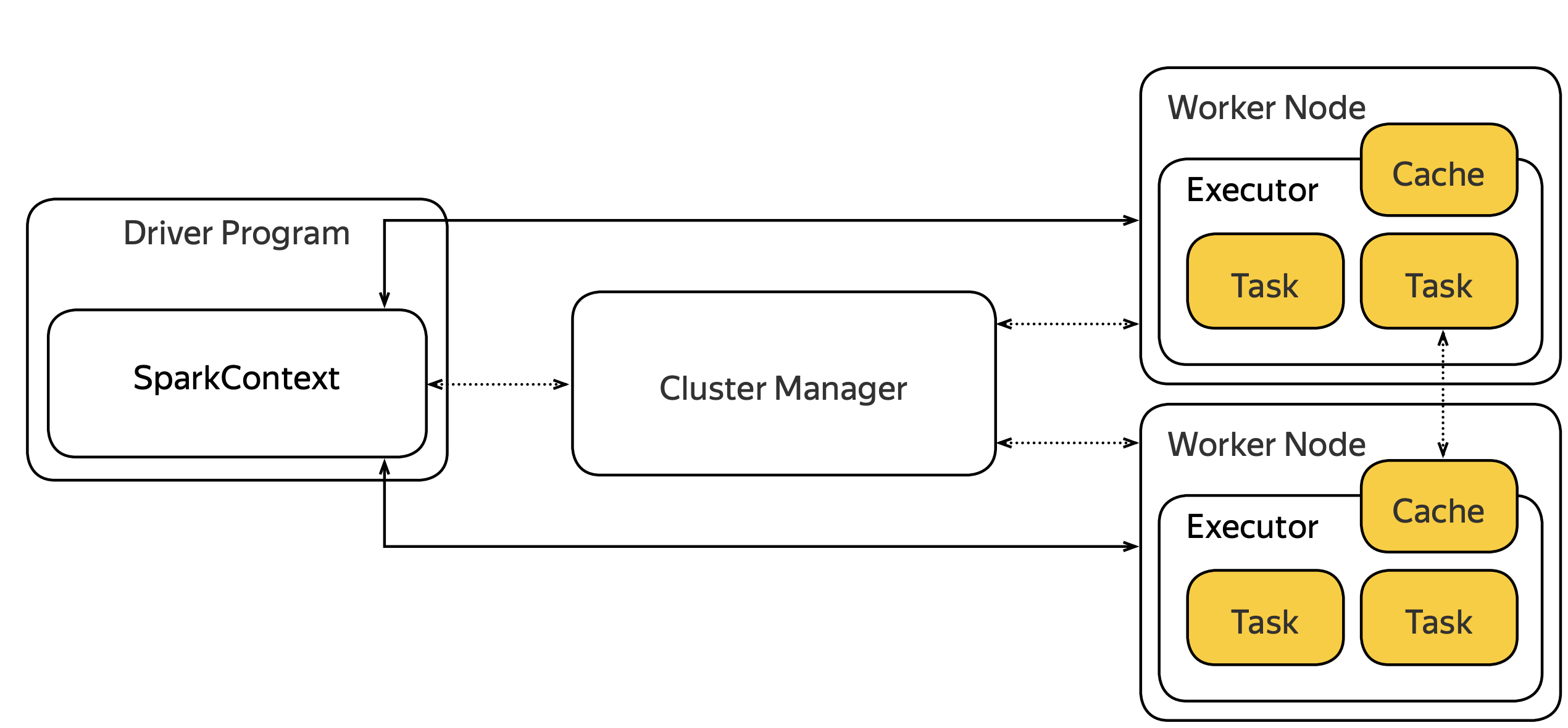
- Job stage is a pipelined computation spanning between materialization
- boundaries
- Task is a job stage bound to particular partitions
- Materialization happens when reading, shuffling or passing data to an action
- narrow dependencies allow pipelining
- wide dependencies forbid it
SparkContext的其他作用
- Tracks liveness of the executors
- required to provide fault-tolerance - Schedules multiple concurrent jobs to control the resource allocation within the application
- Performs dynamic resource allocation to control the resource allocation between different applications
持久化的最佳实践
- For interactive sessions
- cache preprocessed data - For batch computations
- cache dictionaries
- cache other datasets that are accessed multiple times - For iterative computations
- cache static data - And do benchmarks!