字段设计
A.选择优化的数据类型
1.数据类型的选择原则:
- 更小的通常更好
- 简单就好
- 尽量避免NULL
2.应该尽量只在对小数进行精确计算时才使用DECIMAL,使用int类型通过程序控制单位效果更好
3.使用VARCHAR合适的情况:字符串列的最大长度比平均长度大很多;列的更新很少,所以碎片不是问题;使用了像UTF-8这样复杂的字符集,每个字符都使用不同的字节数进行存储
4.CHAR适合存储很短的字符串,或者所有值都接近同一个长度;不容易产生碎片,在存储空间上更有效率
5.通常应该尽量使用TIMESTAMP,它比DATETIME空间效率更高
B.MySQL schema设计中的陷阱
1.不好的设计:
- 太多的列
- 太多的关联
- 全能的枚举
- 变相的枚举
- 非此发明(Not Invent Here)的NULL
C.范式和反范式
1.范式的优点:
- 范式化的更新操作通常比反范式化要快
- 当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修改更少的数据
- 范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快
- 很少有多余的数据意味着检索列表数据时更少需要DISTINCT或者GROUP BY语句
2.范式化设计的缺点是通常需要关联
3.反范式的优点:避免关联,避免了随机I/O,能使用更有效的索引策略
D.缓存表和汇总表
1.有时提升性能最好的方法是同一张表中保存衍生的冗余数据,有时也需要创建一张完全独立的汇总表或缓存表
2.物化视图,MySQL并不原生支持,Flexviews
3.如果应用在表中保存计数器,则在更新计数器时可能踫到并发问题,创建一张独立的表存储计数器,可以帮助避免缓存失效
- 解决独立表并发问题可以建多行,根据id随机更新,然后统计时sum()
- 按天或小时可以单独建行,旧时间可定时任务合并到统一的一行
E.加快ALTER TABLE操作的速度
1.两种方式:
- 一是在一台不提供服务的机器上执行ALTER TABLE操作,然后和提供服务的主库进行切换
- 二是通过“影子拷贝”,创建一张新表,然后通过重命名和删表操作交换两张表及里面的数据
2.快速创建MyISAM索引,先禁用索引,导入数据,然后重新启用索引
存储引擎的选择
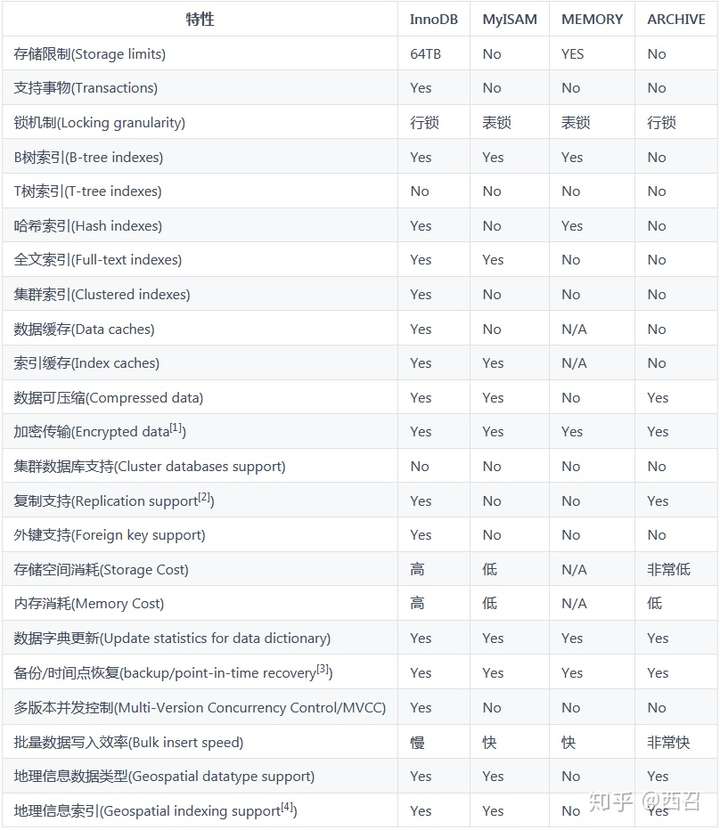
- Myisam
MyISAM表是独立于操作系统的,这说明可以轻松地将其从Windows服务器移植到Linux服务器。
每当我们建立一个MyISAM引擎的表时,就会在本地磁盘上建立三个文件,文件名就是表名。
例如,我建立了一个MyISAM引擎的tb_Demo表,那么就会生成以下三个文件:
tb_demo.frm,存储表定义。
tb_demo.MYD,存储数据。
tb_demo.MYI,存储索引。
MyISAM表无法处理事务,这就意味着有事务处理需求的表,不能使用MyISAM存储引擎。MyISAM存储引擎特别适合在以下几种情况下使用:
-
选择密集型的表。 MyISAM存储引擎在筛选大量数据时非常迅速,这是它最突出的优点。
-
插入密集型的表。 MyISAM的并发插入特性允许同时选择和插入数据。
由此看来,MyISAM存储引擎很适合管理服务器日志数据。
- InnoDB
InnoDB是一个健壮的事务型存储引擎,这种存储引擎已经被很多互联网公司使用,为用户操作非常大的数据存储提供了一个强大的解决方案。
InnoDB还引入了行级锁定和外键约束,在以下场合下,使用InnoDB是最理想的选择:
更新密集的表。 InnoDB存储引擎特别适合处理多重并发的更新请求。
事务。 InnoDB存储引擎是支持事务的标准MySQL存储引擎。
自动灾难恢复。 与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
外键约束。 MySQL支持外键的存储引擎只有InnoDB。
支持自动增加列AUTO_INCREMENT属性。
从5.7开始innodb存储引擎成为默认的存储引擎。
一般来说,如果需要事务支持,并且有较高的并发读取频率,InnoDB是不错的选择。