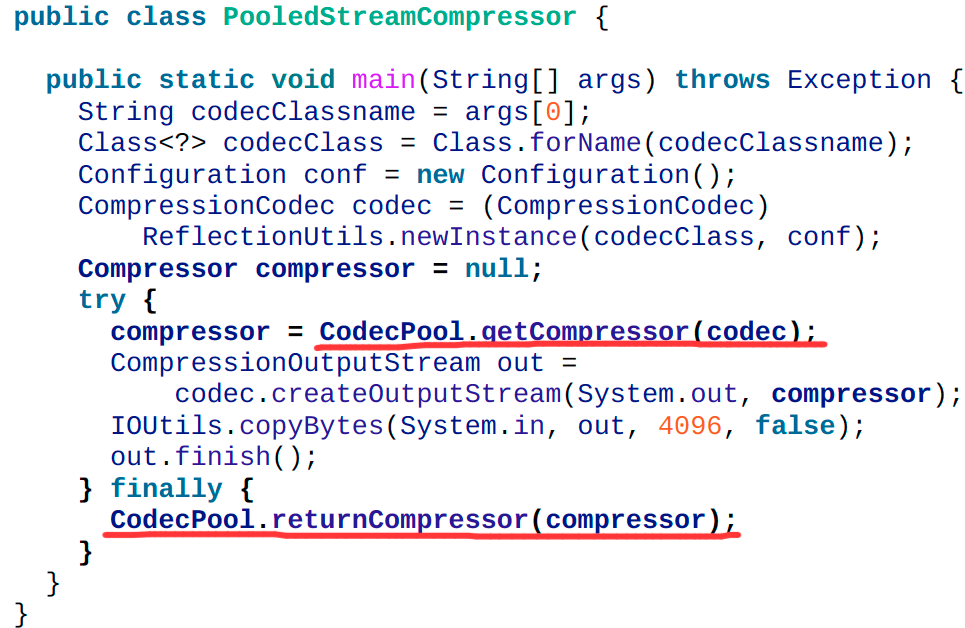
文件压缩主要有两方面的好处:一方面节省文件存储空间;另一方面加速网络数据传输或磁盘读写。当处理大规模的数据时这些效果提升更加明显,因此我们需要仔细斟酌压缩在Hadoop环境下的使用。
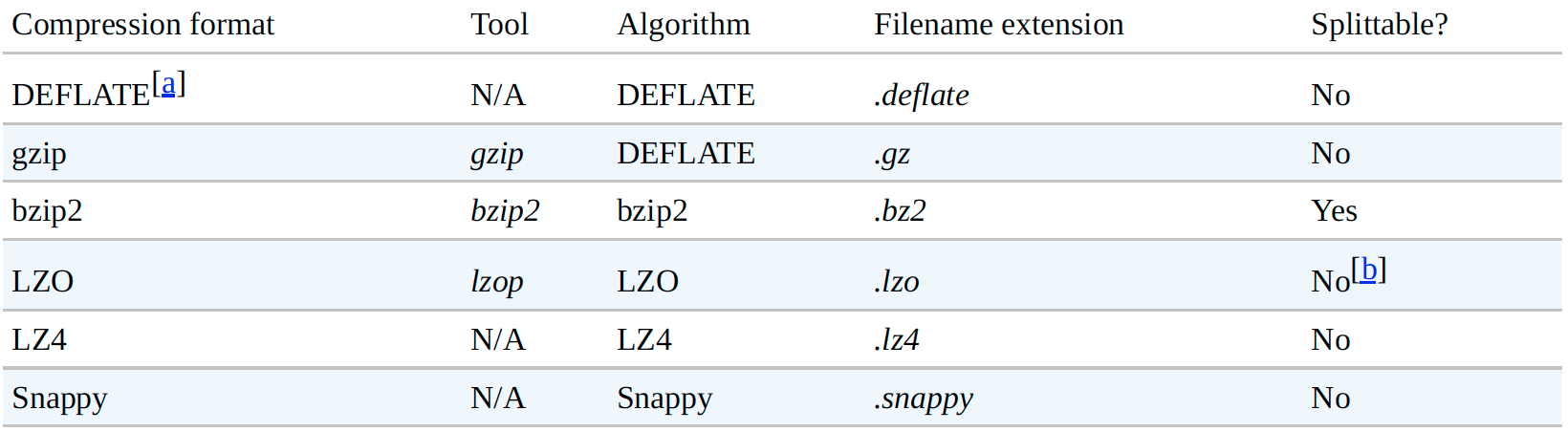
目前已经存在很多压缩格式、工具和算法,各有特点,如下图:
说明:
a. DEFLATE是一种压缩算法,标准实现是zlib,尚没有命令行工具支持。一般情况下使用gzip,相对于DEFLATE而言有额外的头部和尾部。文件扩展名.deflate是一个Hadoop的约定。
b. LZO文件经过预处理被索引之后是可以支持切片的。
所有的压缩算法都存在空间与时间的权衡:更快的压缩速率和解压速率是以牺牲压缩率为代价的。通常的命令行工具会提供九种不同的权衡选项:-1意味着更快的压缩速率;-9意味着更高的压缩率。如:gzip -1 file意味着使用更快的压缩算法创建压缩文件file.gz。
不同的压缩算法拥有不同的压缩特性:
gzip是一种常规的压缩工具,空间与时间得到很好的权衡;
bzip2压缩率高于gzip,但压缩速度较慢;解析速度优于它的压缩速度,但还是较其它压缩算法偏慢;
LZO、LZ4和Snappy相对于gzip而言压缩速度得到很大提升,但没有gzip的压缩率高;而Snappy和LZ4相对于LZO而言在解压速率方面有明显的提升。
“Splittable”指示压缩格式是否支持切片,即是否可以在数据流中随意寻址读取数据,可切片的压缩格式非常适合MapRedcue。
Codecs
Codec是实现特定压缩/解压缩算法的编码解码器。Hadoop Codec必须实现CompressionCodec接口,如下:
public interface CompressionCodec { CompressionOutputStream createOutputStream(OutputStream out) throws IOException; CompressionOutputStream createOutputStream(OutputStream out, Compressor compressor) throws IOException; Class<? extends Compressor> getCompressorType(); Compressor createCompressor(); CompressionInputStream createInputStream(InputStream in) throws IOException; CompressionInputStream createInputStream(InputStream in, Decompressor decompressor) throws IOException; Class<? extends Decompressor> getDecompressorType(); Decompressor createDecompressor(); String getDefaultExtension(); }
可用的Codec如下:

LZO库是基于GPL协议的,没有被包含在Apache的发布版中,需要独立下载。
Compressing and decompressing streams with CompressionCodec
CompressionCodec有两个方法可以帮助我们方便的压缩或解压数据。压缩数据时使用createOutputStream(OutputStream out)获取压缩输出流,我们将未压缩的数据写入该流,它会帮我们压缩数据后写出至底层的数据流out;相反地,解析数据时使用createInputStream(InputStream in)获取解压缩输入流,通过它我们可以从底层的数据流中读取解压后的数据。
CompressionOutputStream、CompressionInputStream与java.util.zip.DeflaterOutputStream、java.util.zip.DeflaterInputStream类似,但是前者支持重置内部的压缩器(Compressor)与解压缩器(Decompressor)状态。如果应用程序需要将数据流中的数据一部分一部分地压缩成“块”的形式,每次压缩完一个“块”之后都需要重置压缩器(Compressor)的状态才可以压缩下一“块”的数据,解压缩时同理。
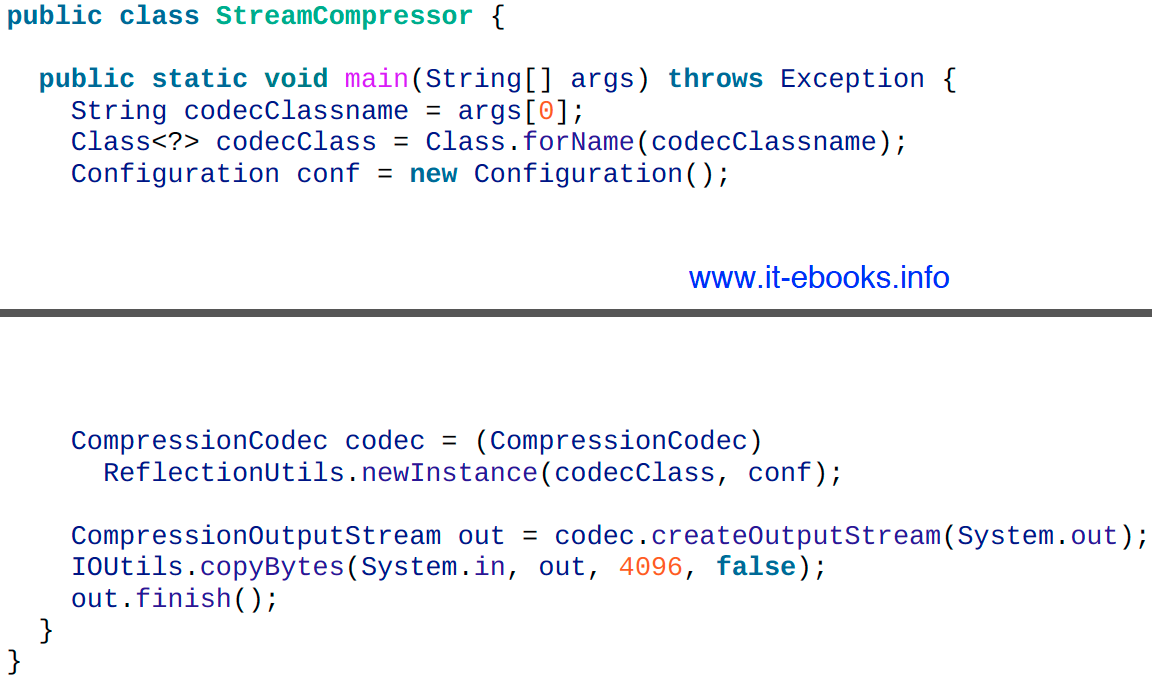
这个应用程序读取标准输入流中的数据,使用指定的压缩算法将数据压缩后写出至标准输出流。程序运行时需要提供一个命令行参数:CompressionCodec全限定类名。可以使用下面的命令进行验证:
echo "Text" | hadoop StreamCompressor org.apache.hadoop.io.compress.GzipCodec | gunzip
Text
Inferring CompressionCodecs using CompressionCodecFactory
当我们仅仅需要处理一种特定格式的压缩文件时,我们可以简单的根据这个压缩文件的后缀名决定使用哪个Codec进行数据读取(上述两张图分别给出文件后缀名与压缩格式的对应关系,以及压缩格式与Codec的对应关系);当我们的应用程序需要兼容多种压缩格式时,就需要有一种机制帮助我们根据压缩文件后缀名透明地帮助我们选取合适的Codec。
CompressionCodecFactory getCodec()方法可以根据我们提供的一个文件路径(文件名称带有后缀)返回匹配CompressionCodec。
CompressionCodecFactory实例初始化时,会在构造方法中维护文件后缀名与CompressionCodec的映射关系,代码如下:
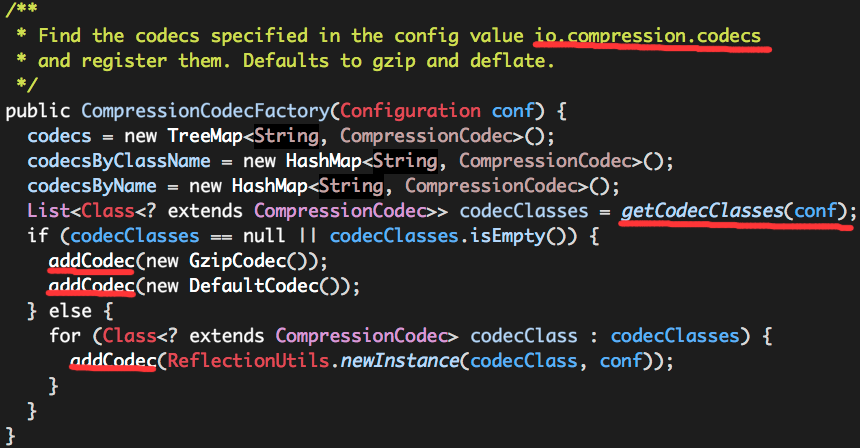
其中,getCodecClasses返回我们配置(io.compression.codecs)的所有CompressionCodec实例,然后通过addCodec()方法维护映射关系。如果我们没有配置任何需要支持的CompressionCodec,则默认添加GzipCodec,DefaultCodec。
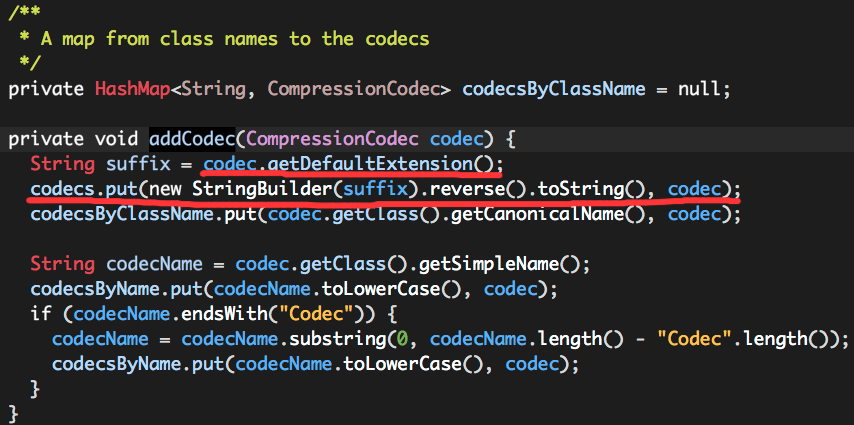
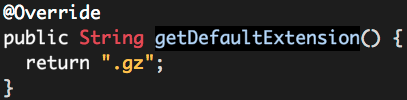
可以看出文件后缀名是通过CompressionCodec getDefaultExtension()方法获取的,而且经过字符串逆转处理,每一个CompressionCodec实例都会有一个getDefaultExtension()方法,返回此CompressionCodec实例对应的文件后缀名,如GzipCodec:
addCodec方法很重要的一部分工作就是维护文件后缀名与CompressionCodec之间的映射关系codecs,

源码注释也强调这里codecs的实现有点“过度”(SortedMap),如果直接使用HashMap表示文件后缀名与CompressionCodec之间的映射关系是不是更简单?
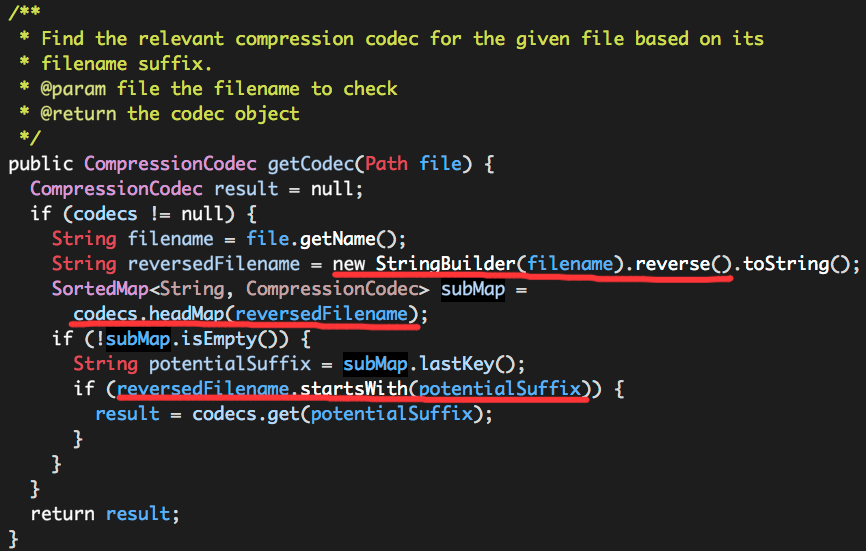
因为“过度”的使用SortedMap,getCodec的实现也略有点复杂,读者可自行理解,核心思想依然是根据传入的文件路径获取文件后缀名,然后在codecs中寻找匹配的CompressionCodec。
CompressionCodecFactory使用示例如下:

可以看出我们并不需要在程序中显示指定使用哪个CompressionCodec,而是由CompressionCodecFactory帮助我们根据文件后缀名自动推断出相应的CompressionCodec,极大地增强应用程序在处理压缩文件时的通用性。
Native libraries
Hadoop的压缩库通常会有两种实现,一种是Java实现,另一种是本地库,就性能而言本地库在压缩和解压方面更具优势。比如gzip,使用本地库相比于Java实现,压缩时间可以提高10%,解压缩时间可以提高50%。

默认情况下,Hadoop会自动在本地库路径(java.library.path)下查询并加载合适的本地库实现,我们可以通过设置属性io.native.lib.available为false禁用本地库,此时内建的Java实现将被使用。
CodecPool
在应用程序中如果需要使用本地库进行大量的压缩、解压工作,可以考虑通过使用CodecPool重用压缩器(Compressor)和解压缩器(Decompressor),从而避免频繁创建这些对象带来的大量开销。