Hierarchical Attention Flow for Multiple-Choice Reading Comprehension
Abstract
在本文中,我们对多选式阅读理解任务进行了研究,该任务要求在给定文章的条件下,在几个选项中选出正确答案来回答问题。我们提出了分层注意流以充分利用候选选项来对段落,问题和候选选项之间的交互进行建模。我们观察到在该任务中,利用选项来强化文章中的证据信息扮演着重要的角色,但是这在先前的工作中被忽略了。此外,我们使用注意力机制显式地对选项相关性进行建模,以获得更好的选项表示,然后将其进一步馈入双线性层以获得每个选项的排名得分。我们提出的这个模型在一个大规模多选式阅读理解数据集的子集RACE-M和RACE-H上超越了两个先前的神经网络模型,并且实现了最先进的结果。
Introduction
在本文中,我们研究了多选式阅读理解任务,该任务中,每个问题都伴随着四个选项并且只有一个选项是正确的。图1中展示了一个样例。与先前阅读理解任务中的问题相比,多选式任务中的问题对在文中提取段落的匹配范围没有限制。相反,这些选项都是由人工生成的,它可能并未出现在原文中。

RACE和MCTest是两个具有代表性的基准数据集,它们都是由人工生成的选择式阅读理解数据集。Yin, Ebert, and Sch¨utze通过注意力机制在不同的分级上使用卷积神经网络建立相应的文本表示。Trischler等人在MRTest数集上通过分层结构在多种角度上构造了匹配表示,并在其提出的模型上应用了一种训练技术以聚合上述表示。Lai等人采用了两个强大的神经网络模型GA Reader和AR Reader作为RACE数据集的基线方法。具体来说,这两个模型仅通过问句来汇集并聚合文章中的证据信息,随后构造证据与选项间的匹配表示。
受Yin, Ebert, and Sch¨utze (2016) and Trischler等人工作的启发,我们提出了一个基于分层注意流的神经网络模型,该模型可充分利用选项信息对文章、问句和选项建模,以得到其词级和句子级交互特征,将其展示于图2中。该注意力流的流程如下所述。我们使用双向循环网络(BiRNN)对文章、问句和答案分别进行编码。然后,通过词级注意力层来建立问句感知的文章句子表示和选项句子表示。随后,我们使用一个BiRNN作为上下文编码器对文章中的多个句子进行建模以捕获其时序特征。再然后,句子级注意力层从带有选项和问句信息的文章表示中提取证据,对选项的相关性进行建模,以获得更好地选项表示。最终,通过一个双线层来计算每个选项的得分并对其进行排序。我们工作的关键贡献包括以下三点。
首先,我们提出使用选项在文章中提取证据。在Lai等人使用的两个基准方法里,只使用了问句去提取证据。而在选择式阅读理解中,文具有时候并不包含信息或包含的信息不足以用于提取证据。尤其是填空式的问题或对主题进行概括的问题,而由这些问题为依据提取出的部分证据可能会误导模型进行错误的预测。然而,选项可以提供额外的信息用以澄清问句的意图。因此在我们的模型中,我们利用问句感知的选项表示来强化证据的提取过程。通过这种方式,该模型利用融入了问句信息的选项信息来提取更有效的证据,从而在众多选项中选出正确的答案。
其次,为了进一步利用选项中的信息,我们利用了选项的相关性作为额外的信息融入到原有的选项表示中去,这在先前的工作中未被重视。现有的模型对于每个选项计算出的得分都是独立的。而我们将每个选项都与其他每个选项进行相关性建模。这种相关性被编码到带有句子级注意力信息的向量表示中去,随后将此向量与原本的选项表示进行联接。因此,我们提出的模型会在考虑其他选项的情况下为每个选项评分。
最后,我们在RACE(RACE-M对应初中题目,RACE-H对应高中题目)上构造了大量的实验。我们提出的模型在评测指标accuracy上优于先前的基准方法1.9%,实现了最优性能。
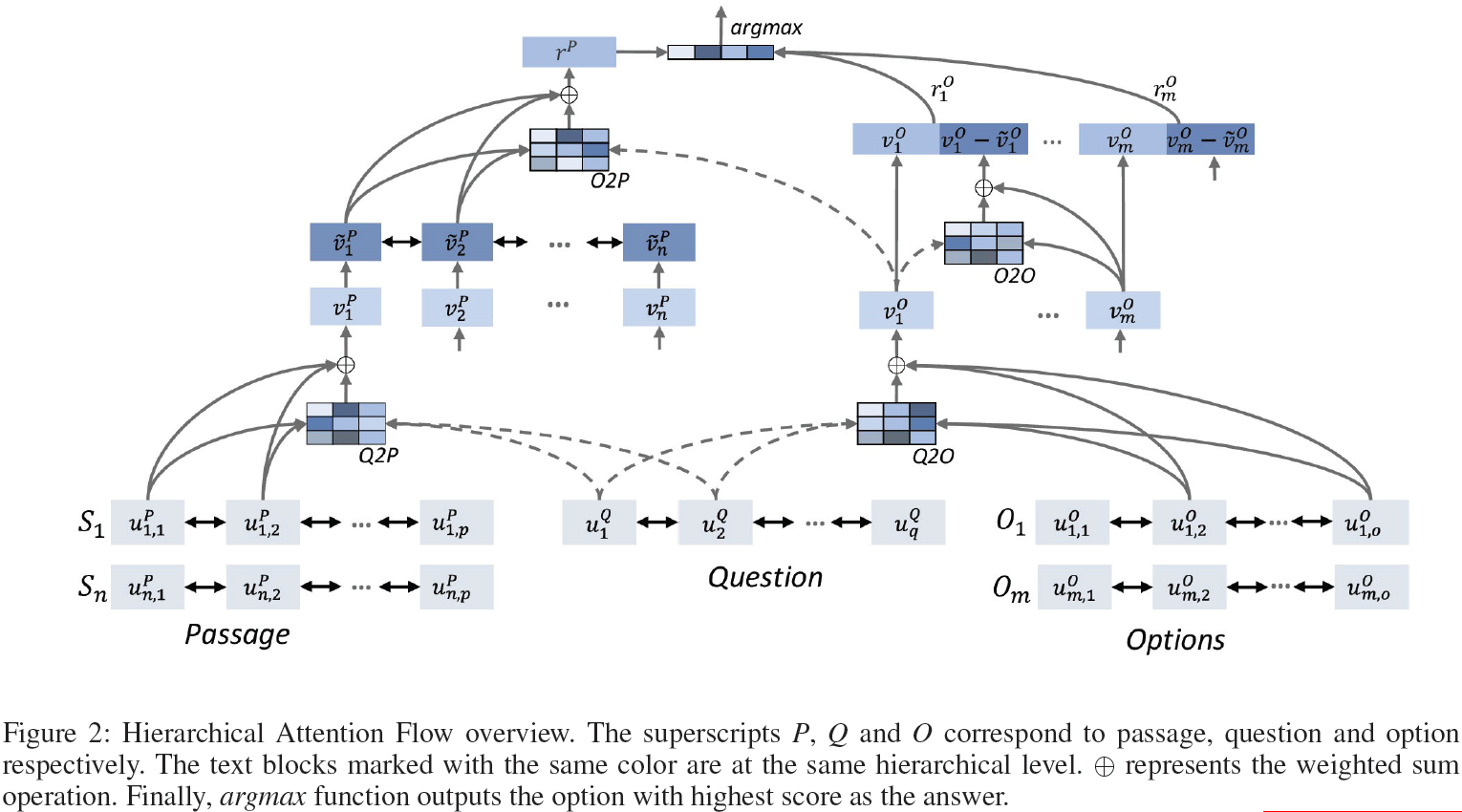
Model
我们在图2中按从下到上从左到右的外观顺序介绍了我们的分层注意流模型。
Word Context Encoder
给定一个包含q个词的问句{wtQ}t=1q,一个包含n个句子的文章{wi,tP}i=1n和办好m个选项的候选答案{wi,tO}i=1m。我们首先通过一个嵌入矩阵E ∈ R|V |×d将每个词w映射为相应的d维向量e,这里的V表示词表大小。然后我们使用BiRNN对词表示进行双向编码。在这里我们选择GRU作为循环网络的基础模块:
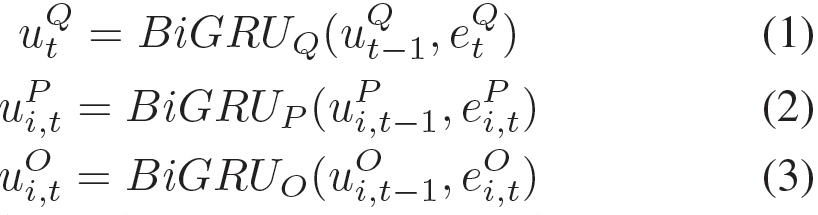
因此,我们获得了语境感知的问题表示uQ,文章中第i个句子的表示uiP和第i个选项的表示uiO。
Attention Flow
在我们的模型中组件之间的交互特征用于强化和组织相应的相关性信息。我们对每个交互过程使用相同的注意力机制。在本节中,我们先介绍了注意力机制的细节,然后介绍了各种交互过程。
Attention Mechanism
我们采用与Cui等人类似的注意力机制,但我们并不使用点乘的方式得到相关性得分,而是使用双线型(bilinear)函数来计算相关性得分。给定两个输入X ∈ Rm×k和Y ∈ Rn×l,通过att(X, Y | Wxy)得出注意力向量a,而aj表示Yj对X的注意力权重。
具体来说,我们首先通过双线型权重矩阵Wxy ∈ Rk×l来计算匹配矩阵A ∈ Rm×n,这里的Ai,j是Xi与Yj的相关性得分。然后我们通过按行softmax函数得到注意力权重矩阵s:
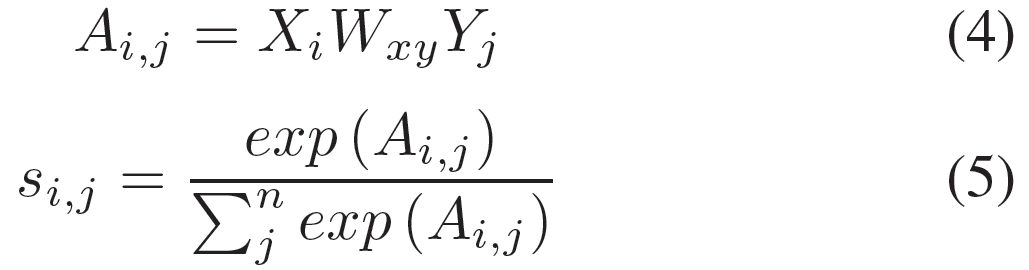
这里的si表示从Xi角度来看,Y上的相关权重。然后我们通过对这个注意力权重矩阵按列计算平均值来组合X的每个向量的视图,以获得最终的注意权重向量a:
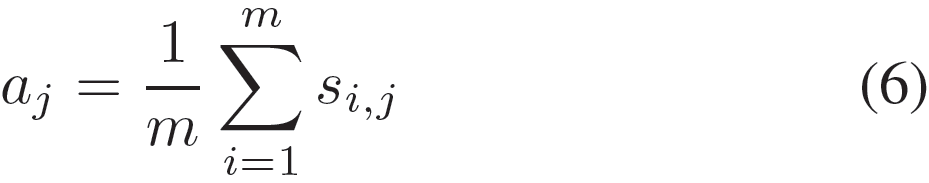
Question-to-Passage (Q2P) Word-level Attention
句子中的每个词并不是同等重要的,这意味着每个词的重要性可能会随着问题的改变而变化。为了得到文章中句子的向量表示,我们用问句中的词表示来衡量文章中第i个句子中每个单词的重要性。我们使用的是问句通过BiGRU编码处理后的所有时间步的结果,而非只取最后一个时间步的结果,这种做法曾用于Lai等人的工作中。然后我们就能得到文章中每个句子的问题感知的句子表示:
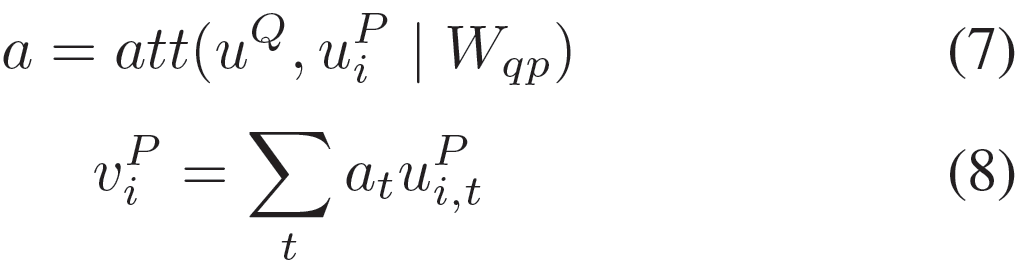
Question-to-Option (Q2O) Word-level Attention
Lai等人用BiGRU最后一个时间步的输出作为选项表示,这是没有问句信息的向量表示。然而,当选项与问句信息结合以后,其意义可能具有更多的可解释性。因此, 我们将问句信息与选项的词表示进行聚合,通过词级注意力机制形成一个固定大小的向量表示。与上文相似,我们可以得到问句感知的选项表示:
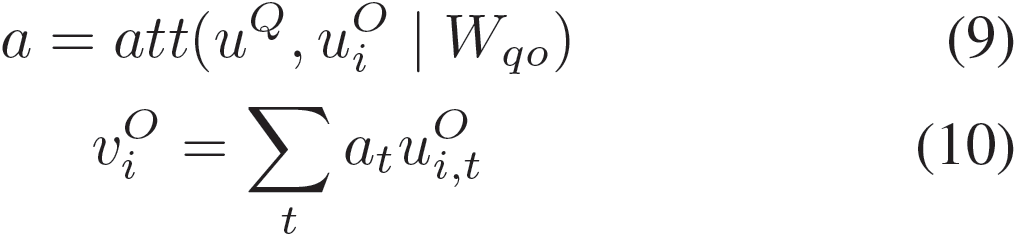
Sentence Context Encoder
一篇文章中的句子之间的顺序信息与一个句子中单词之间的顺序信息一样重要。但是我们前边对文章中句子的处理都是并行的,产生的都是上下文独立的句子表示。为了像对词级上下文信息建模一样对句子上下文信息进行编码,我们应用另一个BiGRU对上文生成的文章句子表示进行编码。随后,句子上下文被编码到一下新的向量中去,如下:
![]()
Option-to-Passage (O2P) Sentence-level Attention
在阅读理解任务中,文章中通常包含与事件、地点等对象相关的丰富信息。而一个问题一般只涉及其中一个方面,此时不相关的部分均可被视为冗余和噪音。为了避免冗余噪音的消极影响,Lai等人将完整的文章信息转化为一个单向量表示,转化方式为计算问句与文章中不同句子的注意力权重。这在填空式阅读理解模型中是一个备受欢迎的方式。在我们的模型中,我们通过句子级注意力机制,利用问句感知的选项表示来强化从文章中提取的证据。在注意力计算过程中,对于该选项相关的文章中的句子分配较高的权重。然后我们对文章中每个句子分配的权重计算平均值以获得最终的注意力权重。与先前的工作不同,我们将问句信息通过Q2O词级注意力显式地融入到选项中去。最后,选项连同问句信息一起,将证据聚合为一个定长向量:
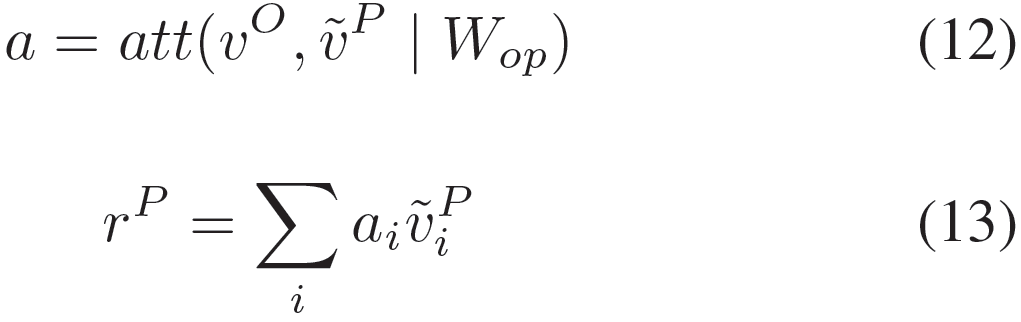
Option Correlations
上文中的选项表示是通过Q2O中的词级注意力生成的,该表示可感知问句信息。但是这样的选项表示与其他几个选项之间是独立的,没有任何的比较信息被编码进去。为了对选项相关性进行建模,我们通过注意力机制对几个选项进行了比较。在某个选项与它自身对比的时候(对角线),我们将其设置为0。Si,j表示第j个选项相对于第i个选项的相关性,与前述更有诚意杨,并不需要合并。受Chen等人工作的启发,我们我们通过差异性来对选项相关性进行建模,随后它与独立的选项表示进行联接,以此作为选项的强化表示:
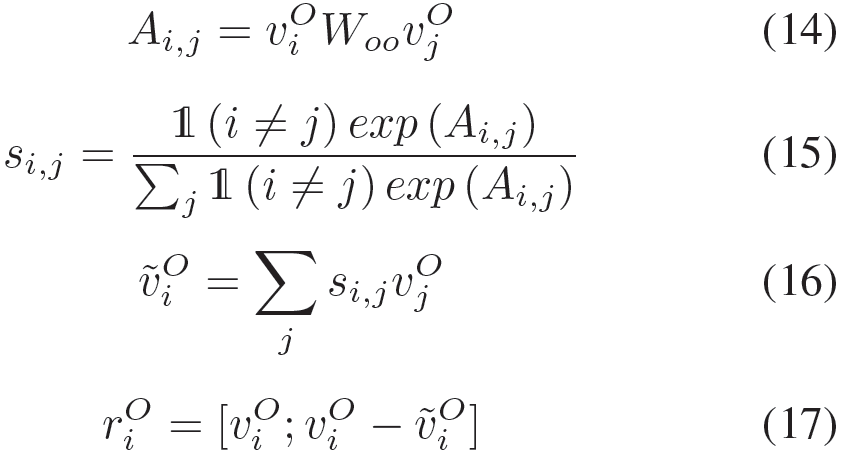
Answer Prediction
我们依据Lai等人的思路,通过双线型函数针对汇总证据计算第i个选项的匹配得分,概率pi表示第i个选项为正确答案的概率:
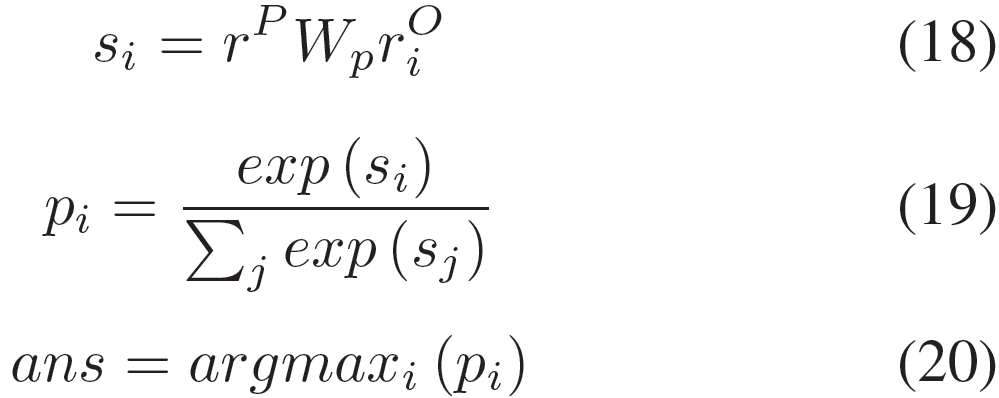
我们通过最小化正确答案的负对数概率来训练网络。
Experiments
Dataset
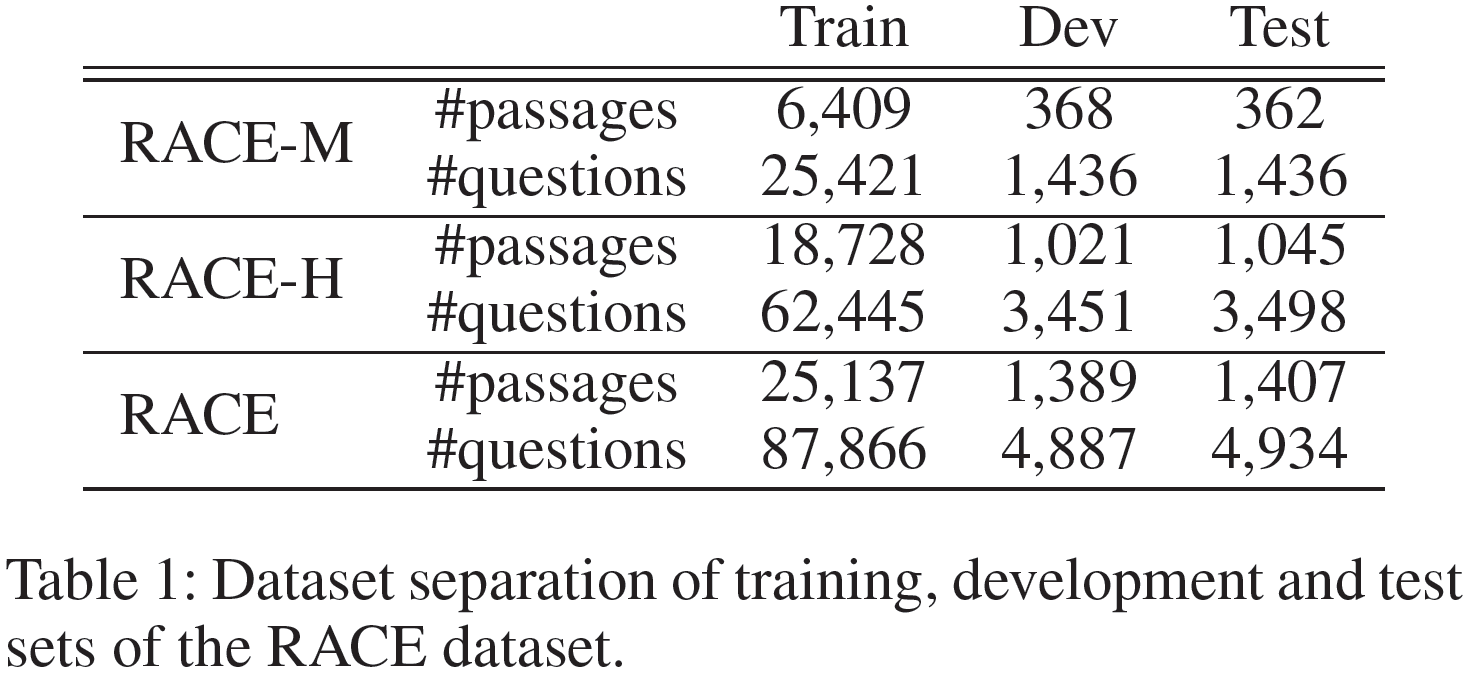
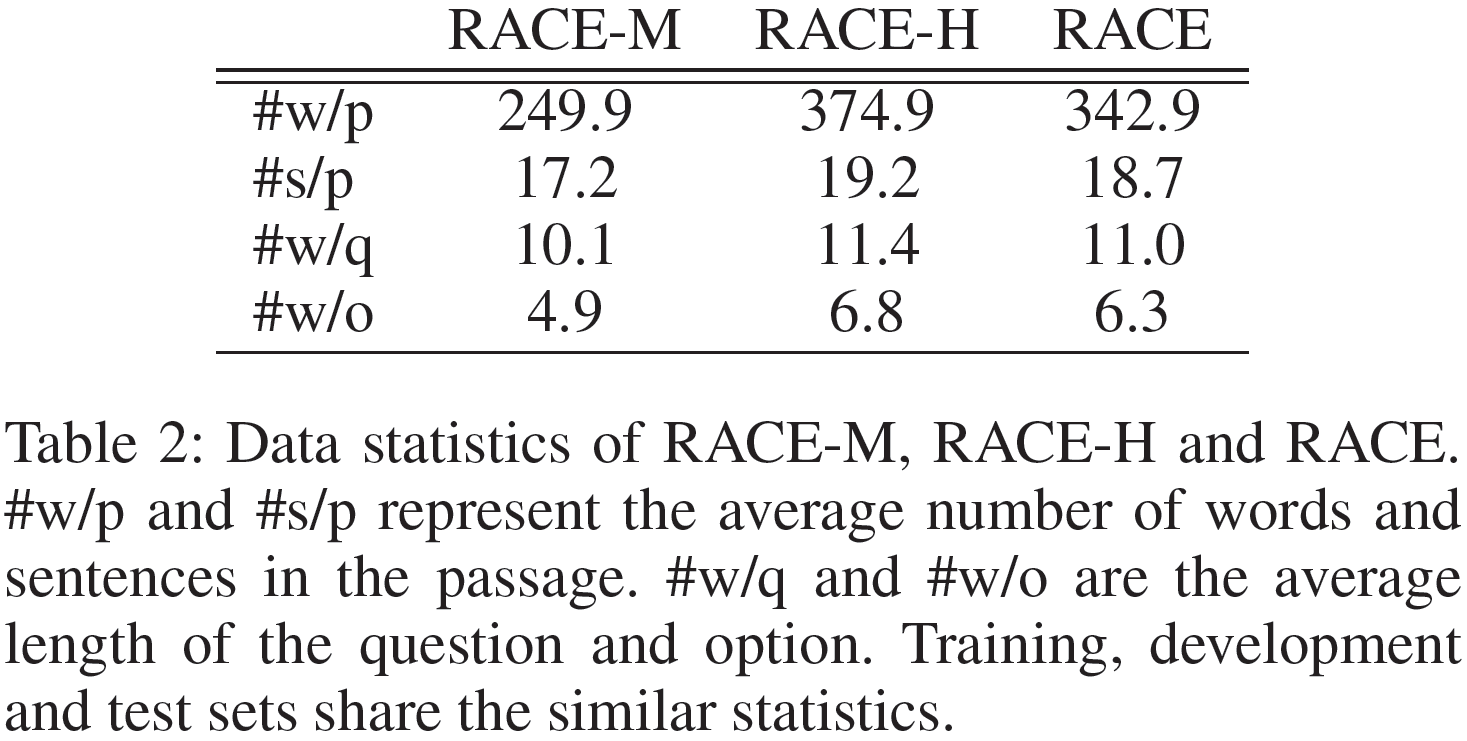
来自考试题目的大规模阅读理解数据集RACE是一个多选式阅读理解数据集。RACE-M和RACE-H分别对应初中级别和高中级别的题目。所有问题都包含四个选项并且只有一个为正确答案。RACE包含了27933篇文章和97687个问题,其中5%为验证集,5%为测试集。表1展示了该数据集的数据划分情况。表2是数据集中的文章、问题和选项里单词的平均数量。
Implementation Details
依照Lai等人的工作,我们将RACE-M和RACE-H一起作为训练集和验证集。我们通过自然语言工具包Toolkit将文章、问题和选项划分为句子和词。我们使用TensorFlow实现了我们的模型。为训练该模型,我们采用ADAM的随机梯度下降优化器,并将学习率初始化为0.001。梯度在L2范数中被裁剪为不大于10。最小batch设置为32。我们保留训练集中的50000个常用词作为词表,并将词表外的词均标记为UNK。我们使用区分大小写的300维预训练嵌入表示Glove来初始化我们的嵌入矩阵,它在训练过程中被进一步更新。所有GRU的隐藏神经元个数均设为128。我们对词嵌入和BiGRU层使用dropout来防止过拟合,并将dropout值设为0.4.
Results
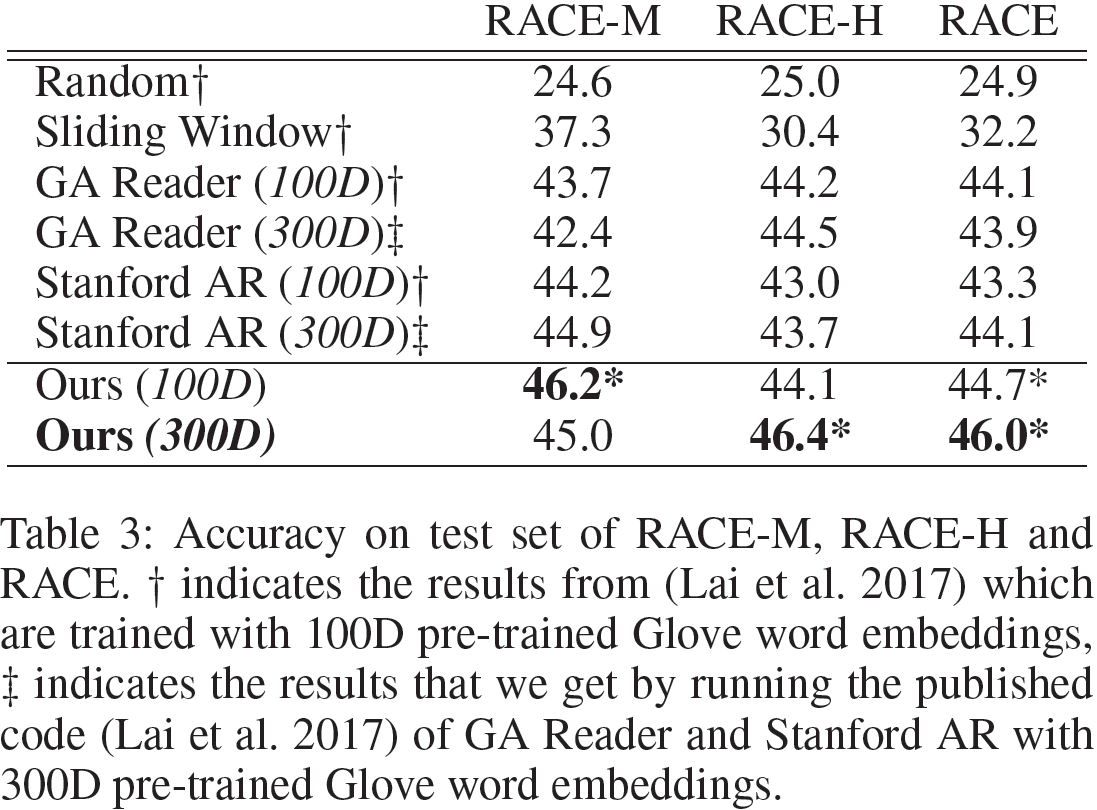
准确率是RACE数据集上衡量模型性能的唯一指标。我们报道了我们模型和一些基准方法在测试集上的准确率。我们的模型在RACE-M和RACE-H数据集上超越了先前最优的神经网络方法GA Reader(100D),实现了最优的性能。
在表3中,GA Reader和Stanford AR在填空式阅读理解中是两个非常强大的神经网络模型,而Lai等人将其作为RACE数据集上的基准方法。为了使得结果更具可比性,我们减小了参数数量的影响,我们训练了两个用300维词嵌入的神经网络基准方法,并以相同的编码方式在100维的词嵌入上训练了该方法。我们也用100为词嵌入训练了我们的模型。结果显示,在相同的词嵌入维度下,我们的方法优于其他的基准方法。此外,我们的模型在使用100维嵌入向量时的效果要优于300维的效果。
Ablation Study
为验证不同组件对模型的性能有多少贡献,我们在验证集上构造了消融实验,其结果展示于表4中。我们先通过删掉句子语义编码层来研究句子时序关系的影响。在RACE-M上的准确率轻微提升了0.2,这是因为对段落句子的证据汇总削弱了句子上下文编码器层的效果,后者对上下文进行汇总和编码。然后我们去掉O2P注意力操作,并用问题替换选项以收集证据,这与Lai等人的操作类似。准确率的大幅下降表明,将选项合并到证据收集中对模型的改进贡献最大。最后,为验证选项相关性的效用,我们通过Q2O词级注意力构造了选项的独立表示。0.7的整体准确率下降表示选项相关性确实强化了选项表示。上述消融实验结果说明了充分利用选项信息对于多选式阅读理解任务的必要性。

Discussion
Evidence Gathering and Option Correlations
为研究选项是如何强化在文章中收集证据的,我们研究了O2P注意力中的权重矩阵。图3中较深的颜色表示较高的权重。该注意力权重矩阵显示了与每个选项相关的证据散落在文章中。合并文章中句子的权重是在尽可能地总结必要的信息。然而,问题可能会错失关键证据尤其是那些并不包含暗示证据的词或短语的问题,就如同图3中的第二个问题。只有结合选项,模型才能捕获相关的证据,强调与“state, money, recycling, landfill, disposal, raw material”相关的句子。

选项相关性对这个例子同样有用。我们以图3中的第一个问题为例。没有选项相关性的模型略微倾向于选择错误答案A,而非C。而通过选项相关性,模型会以相当高的概率(0.987)选择正确答案C。
Top-N Accuracy
为了进一步研究我们模型的整体准确性,我们还在验证集上统计分析了答案的排名得分。由于每个问题仅对应一个正确答案,因此只要答案在前N位,我们就接受该选项正确,并据此计算准确性(acc @ N)。在图4中,acc @ 2和acc @ 3分别达到70.2%和87.2%的总体精度。超出预期的随机猜测从另一个角度说明了我们提出的模型的有效性,并揭示了可以通过重新排序来实现潜在的改进。

Difficulty Gap between RACE-M and RACE-H
RACE-M是从初中考试中收集的,RACE-H对应于高中考试。因此,RACE-M更容易。数据统计还表明,RACE-M中段落,问题和选项的长度较短。并且RACE-M的词汇量小于RACE-H。段落长度的差异主要反映在句子长度上,句子长度通过层次结构缩小到句子数量上的差异。在词汇方面,两个子数据集中的大多数单词都被词汇表覆盖。并且这些影响两个子数据集上的精度,与其先前的困难相一致。
Related Work
Large-scale Datasets
大规模数据集的出现刺激了阅读理解研究的发展。根据答案是否在原文中出现,我们可将现有数据集分为两类。CNN/Daily Mail是自动生成的大规模填空式数据集,这里边的答案通常是文章中的一个词(通常是一个命名实体)。SQuAD中的答案是由人工对连续语句进行标记得到的,这类答案并不是一个词。RACE和MS MARCO是另一个类别中的两个大规模数据集,这类数据集中的答案并未出现在原文中。这更接近以人为本的阅读理解的设置。此外,RACE是选择式阅读理解数据集,它的答案是四个选项中的一个。
Multiple-choice Reading Comprehension
多项选择题在人类的语言考试中很常见。MCTest是一个高质量的多选式阅读理解数据集,它的难度适用于七岁的孩子。它包含500个众包的小故事和2000个问题,每个问题都有四个选项,并且只有一个是正确的。但是该数据集实在太小了,并不足以训练端到端的神经网络。所以先前在MCTest上的工作主要集中在特征工程。这些模型严重依赖于各种自然语言处理工具提取出的词汇、语法和句子特征框架。虽然这些工作对人类有较大的负担,但也在稀疏数据集上实现了不错的效果。Yin, Ebert, and Sch¨utze提出了一个基于分层注意力的卷积网络结构(HABCNN),通过注意力机制映射文章表示,然后确定匹配项或文字含义。该模型优于先前的神经网络方法,但还是远低于特征工程类模型。Trischler等人提出了一个并行分层神经网络,它与HABCNN类似,从词级到多个句子级的角度匹配段落,问题和选项,最终实现了最先进的结果。但是必须使用训练轮对模型进行训练以收敛。
RACE是一个与MCTest形式一样的数据集,但是该数据集的规模更大且难度更高。它来自12岁到18岁的中国学生的英文考试题目,包含28000篇文章和100000个问题。Lai等人通过滑动窗口算法构建了一个基于规则的基准方法,并采用Standford AR和GA Reader作为RACE上更强大的基准方法。这些神经网络方法在对文章建模的时候没有使用分层结构,它们仅通过问题来总结文章中的证据。构建的选项表示和文章与问题是独立的。然后这些模型通过双线性函数构造证据与选项间的匹配表示。用vanilla反向传播训练的神经模型优于滑动窗口基线。
Attention Mechanisms in Reading Comprehension Models
注意力机制在阅读理解任务中十分流行,其主要用于建模交互和预测答案。
Hermann et al. (2015) and Chen, Bolton, and Manning (2016)使用单个问题向量去总结文章。Wang and Jiang (2017),Wang et al. (2017), Cui et al. (2016), Cui et al. (2017), Xiong, Zhong, and Socher (2017) and Seo et al. (2017)利用问句中的每个词与文章进行交互,而不是使用问句的单向量表示。在Wang and Jiang (2017) and Wang et al. (2017)的工作中,问题中的词与文章中的词在RNN编码的每个时间步中被对齐。在Cui et al. (2017) Xiong, Zhong, and Socher (2017)Seo et al. (2017)等人的工作中,问句与文章间的注意力通过双向计算而得到。尽管有问题和段落的注意力,但Wang等人还是提出自匹配注意力以使文章与自身相匹配。Dhingra等人门控注意力去选择文章与单个问题向量的相关部分,该过程通过多跳实现。Sordoni等人计算了文章与问题间的注意力。Shen等人进一步提出通过强化学习动态地确定迭代步骤。
说起答案预测,受Vinyals, Fortunato, and Jaitly (2015), Kadlec et al. (2016)等人在填空式阅读理解中直接使用注意力机制作为预测答案的指针的启发,Dhingra et al. (2017) and Cui et al. (2017)在他们的预测层使用相同的方法。Wang and Jiang (2017) 使用注意力来产生答案跨度的边界。这在SQuAD数据集上是有效且常用的设置。Xiong, Zhong, and Socher (2017) 提出动态指向解码器以迭代地产生答案边界。Lai等人使用双线函数计算RACE中每个选项的匹配得分。
Conclusion and Future Work
在本文中,针对选择是阅读理解任务,我们提出了分层注意流模型。文章、问题和选项在不同层次上分别与其他两项进行交互。为充分利用选项信息,我们汇总选项以强化证据提取,并通过选项间的交互来强化表示,这在先前的工作中没有研究过。最终,我们提出的模型在RACE上实现了最先进的结果,并在RACE-M和RACE-H两个子数据集上实现了优于两个神经网络方法的结果。我们认为语法和话语关系可以引入此结构作为补充信息。在未来的工作中,我们有兴趣通过结合句法信息或话语关系来进一步探讨段落结构,以获得更好地表现。