消息队列介绍、RabbitMQ、Redis
一、什么是消息队列
这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下消息队列的基本思路。
还记得原来写过Queue的文章,不管是线程queue还是进程queue他都是一种消息队列。他都是基于生产者消费者模型来处理消息。
Python中的进程queue,是用于父进程与子进程,或者同属于一个父进程下的多个子进程之间进行信息交互。注意这种queue只能在同一个python程序下才能用,如果两个python程序,或者Python和别的什么程序,他是不能共用的。
那么问题来了,那怎么办那??我就是要用我的QQ程序来调用我的Word文档,怎么办??
这时候跨程序的消息队列工具就出现了,现在主流的有:RabbitQM,ZeroMQ(saltstack就是用的他),Kafka,Redis的消息队列等等
具体什么原理呢?
我想要用QQ调用word,QQ先链接消息队列(broker),把调用word的消息发给broker,如果word和QQ在一个频道,好像是我在微博关注了你,你一发消息,我这里就能收到你的信息了。word一看QQ要启动我,好啊,那来啊,互相伤害啊,然后就启动了。
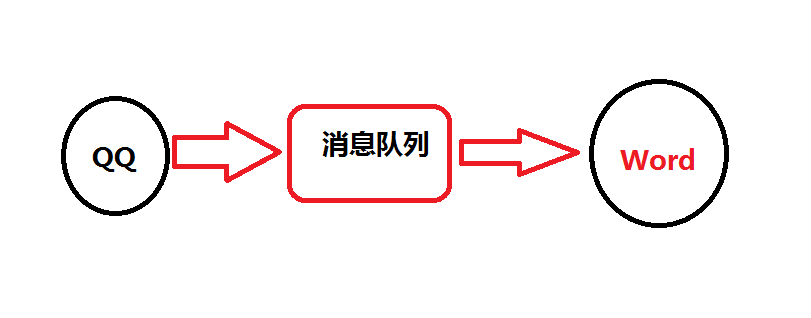
有的大神就说了,感觉好麻烦,还得经过一个中间商,我直接QQ给word发socket请求不行吗,多直接啊~~我微微一笑,从原理上确实是可以,可是实际操作却太难了,消息队列有完善、专业的消息处理机制,可以同时处理大量应用发来的海量消息,并且几乎没有丢消息的可能,而且,关键一点,用着很方便,不用管人家怎么处理你的消息,丢给他就好啦。
二、RabbitMQ介绍与简单应用
1、安装
RabbitMQ是用erlang语言开发的,所以先装语言环境
erlang安装好后,就装RabbitMQ,上官网下rpm,源码,或者yum装都行。
对了,Python开发环境需要pika模块支持
pip install pika or easy_install pika or 源码 https://pypi.python.org/pypi/pika
2、RabbitMQ基本架构及原理
下面为RabbitMQ的基本使用原理的架构图:

这个系统架构图版权属于sunjun041640。
RabbitMQ Server: 也叫broker server,它不是运送食物的卡车,而是一种传输服务。原话是RabbitMQisn’t a food truck, it’s a delivery service. 他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的guard,就可以彻底保证系统的一致性了。
Client A & B: 也叫Producer,数据的发送方。createmessages and publish (send) them to a broker server (RabbitMQ).一个Message有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。
Client 1,2,3:也叫Consumer,数据的接收方。Consumersattach to a broker server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是当然了如果Producer发送的payload包含了Producer的信息就另当别论了。
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
Exchanges are where producers publish their messages.
Queuesare where the messages end up and are received by consumers
Bindings are how the messages get routed from the exchange to particular queues.
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道)。
Connection: 就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
Channels: 虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。有实验表明,1s的数据可以Publish10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
3、基本原理搞清了,下面来个简单的RabbitMQ的使用栗子:
一对一的发送与接收
发送端:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
#声明queue
channel.queue_declare(queue='hello')
# RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
接收端:
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
#You may ask why we declare the queue again ‒ we have already declared it in our previous code.
# We could avoid that if we were sure that the queue already exists. For example if send.py program
#was run before. But we're not yet sure which program to run first. In such cases it's a good
# practice to repeat declaring the queue in both programs.
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
一个生产者,多个消费者,实现消息轮询分发:
生产者:
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
# 声明queue
channel.queue_declare(queue='task_queue')
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
import sys
message = ' '.join(sys.argv[1:]) or "Hello World! %s" % time.time()
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent %r" % message)
connection.close()
消费者:
#_*_coding:utf-8_*_
import pika, time
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(20)
print(" [x] Done")
print("method.delivery_tag",method.delivery_tag)
ch.basic_ack(delivery_tag=method.delivery_tag) #告诉发送端我已经处理完了
channel.basic_consume(callback, #回调函数
queue='task_queue',
no_ack=True
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
当有多个消费者消费时,如果其中一个在处理消息时挂啦,那么消息会不会丢失呢?
我们可以看到在消费者代码有一个参数,no_ack=true,他的作用是如果为true,不管消费者有没有处理消息,都不给生产者反馈,这样的话,如果真的出现消费者异常挂掉了,那么正在处理的消息就真的丢了。如果no_ack=false,消费者在处理完消息后会给生产者反馈,我处理完了,这时生产者才把消息删掉,如果生产者发现消费者没正常反馈信息,就会把这条消息发给别的消费者,保证消息不丢失。
4、消息持久化
上面说的是客户端挂了,服务端还能保存消息不丢失,那服务端挂了咋弄,答案是如果服务端不进行数据持久化,服务挂了连channel都不会给你留的。。。。。
我们在声明队列时需要加句话:
channel.queue_declare(queue='hello', durable=True)
声明队列持久化。服务端和客户端都要写。
写了这句就行了么??不行,这只是把咱们的队列持久化了,队列里的消息依然会丢,然并卵啊。。。
所以要想不丢数据,还得再加代码:
我们需要在生产者这一段加入下面的代码,主要是那个properties
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
我们看到delivery_mode这个参数,delivery_mode=2就是消息持久化的作用。
5、消息的公平分发
当消费者的处理性能有差异时,可能会出现性能好的机器处理消息速度比接受速度还快,性能不好的机器由于处理的慢会出现消息堵塞,最后就是好机器闲着,一般机器忙不过来的情况,造成资源浪费。这里RabbitMQ会提供一个实现消息公平分发的机制,使机器有多大能力收多少消息。
这个机制的配置就是perfetch=1
channel.basic_qos(prefetch_count=1)
带消息持久化+公平分发的完整示例
生产者
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
消费者
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(10)
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
上面栗子用sleep模拟处理时间,我们可以多起几个不同sleep的消费者,观察他们接受消息的规律,我们就会发现,处理的快的消费者接受的消息多,慢的就少。
6、PublishSubscribe(消息发布订阅)
如果我们不想一对一的发送消息,而是想让所有channel都收到,就可以用所谓的广播来进行消息发布。这时我们就用到了exchange
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
headers: 通过headers 来决定把消息发给哪些queue
消息publisher
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
消息subscriber
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
7、有选择的接收消息(exchange type=direct)
可以指定某些更细致的过滤规则来进行指定channel发送
publisher
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
subscriber
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]
" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
8、更细致的消息过滤(exchange type=topic)
可以动态过滤,如图

可以进行范围过滤,而不是写死的过滤条件
publisher
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
subscriber
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...
" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
9、Remote procedure call (RPC)
RabbitMQ的RPC模式,可以实现发布者发布消息给消费者后,还能接收消费者处理消息后的结果,也就是两端既是生产者又是消费者。
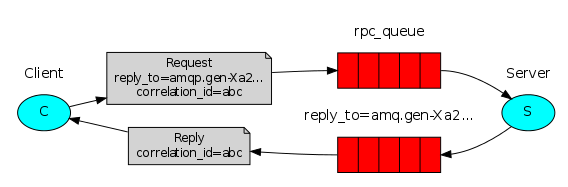
RPC server
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id =
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
RPC client
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response,
no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
三、redis的介绍与应用
1、缓存数据库介绍
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
键值(Key-Value)存储数据库
NoSQL数据库的四大分类表格分析
2、redis介绍
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
-
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
-
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。 -
操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
-
MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
3、Redis API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
连接方式
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis
r = redis.Redis(host='127.0.0.1', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
3、操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储。

set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改 参数: ex,过期时间(秒) px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,岗前set操作才执行setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)setex(name, value, time)
# 设置值 # 参数: # time,过期时间(数字秒 或 timedelta对象)psetex(name, time_ms, value)
# 设置值 # 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象)mset(*args, **kwargs)
批量设置值 如: mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'})get(name)
获取值mget(keys, *args)
批量获取 如: mget('ylr', 'wupeiqi') 或 r.mget(['ylr', 'wupeiqi'])getset(name, value)
设置新值并获取原来的值getrange(key, start, end)
# 获取子序列(根据字节获取,非字符) # 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节) # 如: "武藤兰" ,0-3表示 "武"setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) # 参数: # offset,字符串的索引,字节(一个汉字三个字节) # value,要设置的值setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作 # 参数: # name,redis的name # offset,位的索引(将值变换成二进制后再进行索引) # value,值只能是 1 或 0 # 注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo" # 扩展,转换二进制表示: # source = "苍老师" source = "foo" for i in source: num = ord(i) print bin(num).replace('b','') 特别的,如果source是汉字 "苍老师"怎么办? 答:对于utf-8,每一个汉字占 3 个字节,那么 "苍老师" 则有 9个字节 对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制 11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000 -------------------------- -------------------------- -------------------------- 苍 老 师*用途举例,用最省空间的方式,存储在线用户数及分别是哪些用户在线
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数 # 参数: # key,Redis的name # start,位起始位置 # end,位结束位置bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值 # 参数: # operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或) # dest, 新的Redis的name # *keys,要查找的Redis的name # 如: bitop("AND", 'new_name', 'n1', 'n2', 'n3') # 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(必须是整数) # 注:同incrbyincrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(浮点型)decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数: # name,Redis的name # amount,自减数(整数)append(key, value)
# 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串
Hash操作,redis中Hash在内存中的存储格式如下图:

hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value # 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})hget(name,key)
# 在name对应的hash中获取根据key获取valuehmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数: # name,reids对应的name # keys,要获取key集合,如:['k1', 'k2', 'k3'] # *args,要获取的key,如:k1,k2,k3 # 如: # r.mget('xx', ['k1', 'k2']) # 或 # print r.hmget('xx', 'k1', 'k2')hgetall(name)
获取name对应hash的所有键值hlen(name)
# 获取name对应的hash中键值对的个数hkeys(name)
# 获取name对应的hash中所有的key的值hvals(name)
# 获取name对应的hash中所有的value的值hexists(name, key)
# 检查name对应的hash是否存在当前传入的keyhdel(name,*keys)
# 将name对应的hash中指定key的键值对删除hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数)hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amounthscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter('xx'): # print item
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
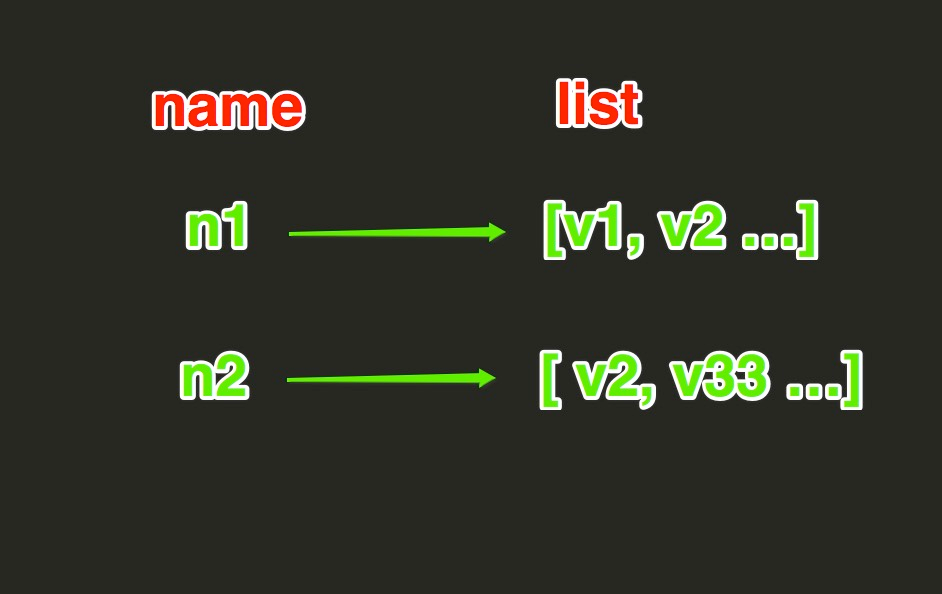
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如: # r.lpush('oo', 11,22,33) # 保存顺序为: 33,22,11 # 扩展: # rpush(name, values) 表示从右向左操作lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多: # rpushx(name, value) 表示从右向左操作llen(name)
# name对应的list元素的个数linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数: # name,redis的name # index,list的索引位置 # value,要设置的值r.lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多: # rpop(name) 表示从右向左操作lindex(name, index)
# 在name对应的列表中根据索引获取列表元素lrange(name, start, end)
# 在name对应的列表分片获取数据 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 # 参数: # src,要取数据的列表的name # dst,要添加数据的列表的nameblpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素 # 参数: # keys,redis的name的集合 # timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 # 更多: # r.brpop(keys, timeout),从右向左获取数据brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧 # 参数: # src,取出并要移除元素的列表对应的name # dst,要插入元素的列表对应的name # timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要: # 1、获取name对应的所有列表 # 2、循环列表 # 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name): """ 自定义redis列表增量迭代 :param name: redis中的name,即:迭代name对应的列表 :return: yield 返回 列表元素 """ list_count = r.llen(name) for index in xrange(list_count): yield r.lindex(name, index) # 使用 for item in list_iter('pp'): print itemSet操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素scard(name)
获取name对应的集合中元素个数sdiff(keys, *args)
# 在第一个name对应的集合中且不在其他name对应的集合的元素集合sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中sinter(keys, *args)
# 获取多个name对应集合的并集sinterstore(dest, keys, *args)
# 获取多个name对应集合的并集,再讲其加入到dest对应的集合中sismember(name, value)
# 检查value是否是name对应的集合的成员smembers(name)
# 获取name对应的集合的所有成员smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素srem(name, values)
# 在name对应的集合中删除某些值sunion(keys, *args)
# 获取多个name对应的集合的并集sunionstore(dest,keys, *args)
# 获取多个name对应的集合的并集,并将结果保存到dest对应的集合中sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素 # 如: # zadd('zz', 'n1', 1, 'n2', 2) # 或 # zadd('zz', n1=11, n2=22)zcard(name)
# 获取name对应的有序集合元素的数量zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 # 参数: # name,redis的name # start,有序集合索引起始位置(非分数) # end,有序集合索引结束位置(非分数) # desc,排序规则,默认按照分数从小到大排序 # withscores,是否获取元素的分数,默认只获取元素的值 # score_cast_func,对分数进行数据转换的函数 # 更多: # 从大到小排序 # zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素 # zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) # 从大到小排序 # zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始) # 更多: # zrevrank(name, value),从大到小排序zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员 # 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大 # 参数: # name,redis的name # min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间 # min,右区间(值) # start,对结果进行分片处理,索引位置 # num,对结果进行分片处理,索引后面的num个元素 # 如: # ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga # r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca'] # 更多: # 从大到小排序 # zrevrangebylex(name, max, min, start=None, num=None)zrem(name, values)
# 删除name对应的有序集合中值是values的成员 # 如:zrem('zz', ['s1', 's2'])zremrangebyrank(name, min, max)
# 根据排行范围删除zremrangebyscore(name, min, max)
# 根据分数范围删除zremrangebylex(name, min, max)
# 根据值返回删除zscore(name, value)
# 获取name对应有序集合中 value 对应的分数zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAXzunionstore(dest, keys, aggregate=None)
获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAXzscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型exists(name)
# 检测redis的name是否存在keys(pattern='*')
# 根据模型获取redis的name # 更多: # KEYS * 匹配数据库中所有 key 。 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hilloexpire(name ,time)
# 为某个redis的某个name设置超时时间rename(src, dst)
# 对redis的name重命名为move(name, db))
# 将redis的某个值移动到指定的db下randomkey()
# 随机获取一个redis的name(不删除)type(name)
# 获取name对应值的类型scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)# 同字符串操作,用于增量迭代获取key
4、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.set('name', 'chengyiqiang')
pipe.set('role', 'coder')
pipe.execute()
5、发布订阅
redis能通过频道进行简单的发布订阅功能
demo如下:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import redis 5 6 7 class RedisHelper: 8 9 def __init__(self): 10 self.__conn = redis.Redis(host='10.211.55.4') 11 self.chan_sub = 'fm104.5' 12 self.chan_pub = 'fm104.5' 13 14 def public(self, msg): 15 self.__conn.publish(self.chan_pub, msg) 16 return True 17 18 def subscribe(self): 19 pub = self.__conn.pubsub() 20 pub.subscribe(self.chan_sub) 21 pub.parse_response() 22 return pub
订阅者:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()
print msg
发布者:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
obj.public('hello')