# 第十三章 迭代器、生成器,认识模块和包
## 一、推导表达式
推导式又称为解析式,是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列的结构体,能较大幅度精简语句,但是也较容易发生错误。所以要了解它的结构逻辑,一共有三种推导:
- 列表推导式
- 字典推导式
- 集合推导式
### 1、列表推导式
引入一个问题,如何得到一个元素为0到9的列表?
按照之前学过的Python基础知识,可以这样完成:

那现在,我们可以通过列表推导式更简练语句实现这个功能:

相比之下,第一种使用循环迭代的形式使用了三行代码,而第二种使用列表推导式就用了一行代码搞定。
如果在列表循环基础再添加条件判断,又可以如何写列表推导式呢?题目是一个元素为0到9的列表,找出是偶数的元素有哪些?

此处if主要起条件判断作用,只有满足if条件的才会被留下,最后统一生成为一个数据列表。代码执行打印结果为:[0, 2, 4, 6, 8]。
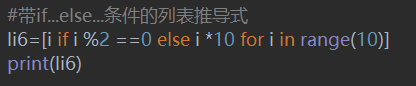
此处if...else主要起赋值作用,当满足if条件时将处理i代码,否则处理i*10代码,最后统一生成为一个数据列表。
### 2、字典推导式
字典推导和列表推导的使用方法是类似的,只是中括号该改成大括号:

另外,再举例列表转换为字典并获取键值对的方法:

### 3、集合推导式
集合推导和列表推导的使用方法也是类似的, 唯一的区别在于它使用大括号{}:

执行该代码结果为:{1,4}。
总结:推导表达式相对于for循环来处理数据,更加方便代码简练,但是目前还是使用for循环会比较好,等代码熟练程度高的时候,掌握好Python基础语法,对代码更加得心应手再广泛利用推导式。
## 二、迭代器
迭代器指的是迭代取值的工具,迭代是指一个重复的过程,每一次重复都是基于上一次结果而来,是Python最强大的功能之一,是访问集合元素的一种方式。并且迭代提供了一种通用的不依赖索引的迭代取值方式。
### 1、为什么使用迭代器
使用for循环可以遍历序列对象(str、list,tuple),序列对象都有索引,通过索引可以访问序列对象的成员。在用for循环遍历序列对象时,即可以使用序列对象的索引来遍历,也可以使用序列项来遍历,for循环使用序列项遍历对象时,就用到了迭代器。另外,Python也有不是序列对象的数据,例如集合、字典、文件等,如何遍历这些数据类型的成员呢,这也需要用到迭代器。
### 2、可迭代对象
但凡内置有__iter__方法的对象,都称为可迭代对象,可迭代的对象:序列对象包括列表、元组和字符串,非序列对象包括字典、集合和文件,实现了__iter__和__next__方法的自定义对象也属于可迭代对象。
### 3、迭代器对象
- 既内置又__next__方法的对象,执行该方法可以不依赖索引取值
- 又内置有__iter__方法的对象,执行迭代器的__iter__方法得到的依然是迭代器本身
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器有两个基本的方法:iter() 和 next()。
迭代器一定是可迭代对象,可迭代对象不一定是迭代器对象,文件对象本身就是一个迭代器对象。下面举例子时可以深入体会这个结论。
### 4、生成迭代器并取值
字符串,列表或元组对象都可用于创建迭代器:
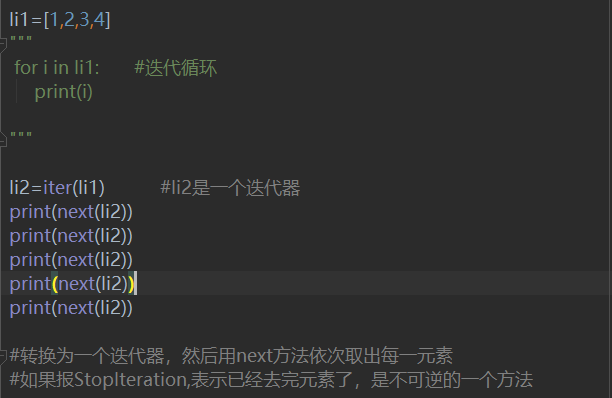
执行该代码,结果为:

总结以上有关迭代器和next()的用法:
从可迭代对象生成一个迭代器:迭代器=iter(可迭代对象),下个值=next(迭代器)。

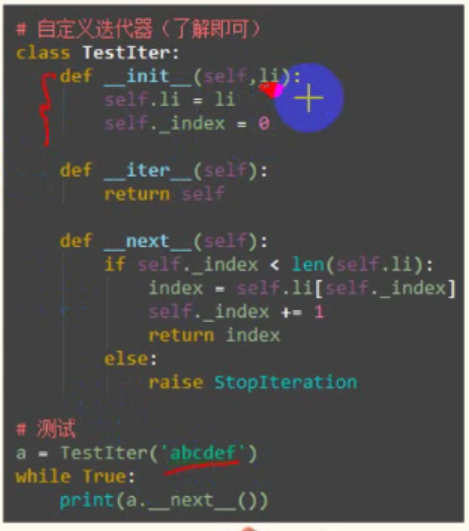
### 5、手写迭代器(了解即可)
可迭代对象和迭代器可以自定义吗?有没有一种简单的方法来自定义呢?
- 1、在类中添加了__iter__方法即取得迭代器。
- 2、在通过__next__方法指出所有的数据。
## 三、生成器
### 1、为什么用生成器?
在Python中,一边循环一边计算的机制,称为生成器。我们知道可以用列表储存数据,可是当我们的数据特别大的时候,建立一个列表的储存数据就会很占内存的。这时生成器就派上用场了。它可以说是一个不怎么占计算机资源的一种方法。简单一句话:我又想要得到庞大的数据,又想让它占用空间少,那就用生成器!
### 2、创建生成器
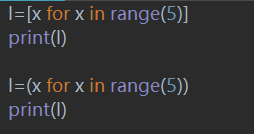
- 把一个列表生成式的[]改成(),就创建了一个生成器。
- 一个函数中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。调用函数就是创建了一个生成器(generator)对象。

### 3、生成器原理
生成器(generator)能够迭代的关键是它有一个next()方法,工作原理就是通过重复调用next()方法,直到捕获一个异常。取生成器里面一个值时,基本上不会用next()来获取下一个返回值,而是直接使用for循环来迭代)。
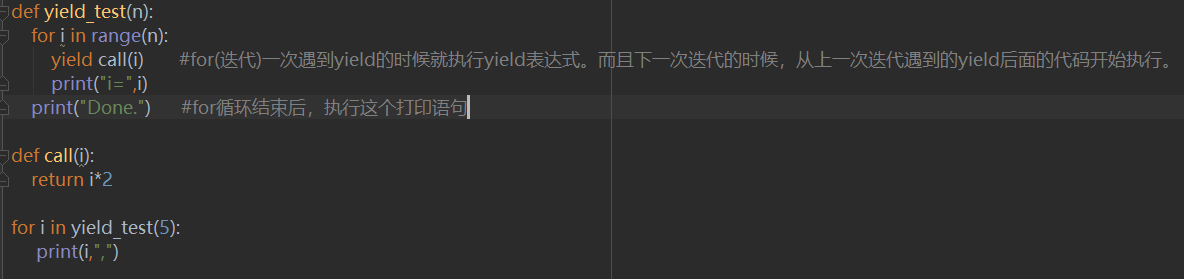
下面,我们来看一下简单的案例:

执行该代码,结果为:
任何一个带有yield语句的函数都是生成器,当你直接调用这个函数时,内部的代码是不会被执行的,只有调用yield里面的next函数才会去执行代码,for循环也就是会自动去调用这个next函数来输出值。可以理解为一个函数被yield中断了,下载再次调用时继续从上一次中断的位置继续执行代码并返回值。
#### 1)、yield关键字作用
- 保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起;
- 将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用;
- 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数);
- 迭代一次遇到yield的时候就返回yield后面或者右面的值。而且下一次迭代的时候,从上一次迭代遇到的yield后面的代码开始执行。
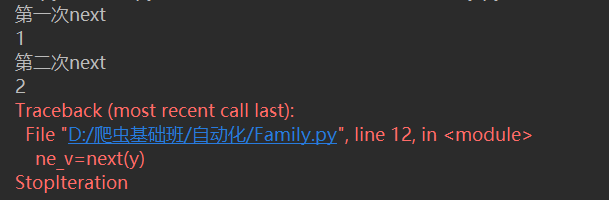
下面,学习一个更深入的案例:
执行该代码,结果为:
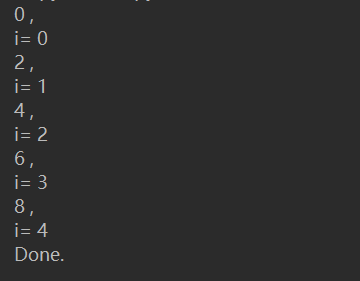
理解的关键在于:下次迭代时,代码从yield的下一条语句开始执行。
#### 2)、send()方法
我们除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。
send()和next()的区别就在于send可传递参数给yield表达式,这时候传递的参数就会作为yield表达式的值,而yield的参数是返回给调用者的值,也就是说send可以强行修改上一个yield表达式值。
通过一个简单的例子来理解send()方法:
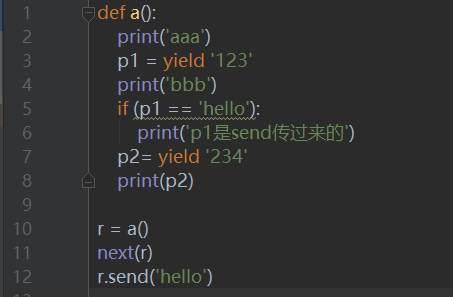
执行该代码,结果为:
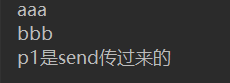
说一下执行的顺序,首先a()是个生成器;第一次执行要么next(r)要么r.send(None),不能使用r.send('xxxxx');这会报错的。第一次执行时next(r)时,首先打印出aaa,
然后遇到yield即跳出,然后执行r.send('hello')时,p1则被赋值为hello了,然后继续接着上次运行,下一步打印出bbb,然后打印出'p1是send传过来的',当再次遇到第二个yield时跳出,所以结果只打印了三行,后面的p2没有执行。
## 四、模块
### 1、模块定义
在前面的几个章节中我们脚本上是用 python 解释器来编程,如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
对于项目来说,程序文件不会出现在一个文件里面,所以需要将很多功能相似的函数进行分组,分别放到不同的文件中,而且对于每一个文件的大致功能使用文件名称来进行区别。为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
### 2、模块优点
- 模块用于提高代码的可维护性
- 可以提高代码的可复用度
- 以引用其他的模块,包括内置模块[Python提供的]以及第三方模块以及自定义模块
- 可以避免函数名和变量名的冲突
### 3、导入模块方式
- import
import后面可以是一个模块,也可以是多个模块,如import os,time,sys,re 等等,每个模块之间用逗号隔开;导入模块其实就是在执行py文件;开辟一块新内容,将内容加载到内存中。
- from...import
我们在使用一个模块时可能只想使用其中的某些功能,比如只想使用sys模块中的modules时,那么import就不好用了,这时我们可以使用from.....import这样的格式来进行模块的某个功能的导入。如:
import sys.module:这个是错误的导入模块示范;
from sys import modules:这才是正确的导入形式。
from.....import 也支持as模式,如:
from sys import modules as md:表示将modules这一模块简写为md。
- from...import *
星号表示导入模块中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
规范建议:模块应该一个一个的导入,先后顺序为:内置模块---->扩展(第三方)模块------>自定义模块;
顺序说明:我们知道导入模块其实就是在执行这个模块,我们不确定扩展模块或自定义模块里有没有某个功能调用了内置模块,所以,我们在导入模块时,应先导入解释器内置的模块,然后在导入扩展模块,最后导入自定义模块。
下面是一个使用 python 标准库中模块的例子。

查看导入模块的源代码,可以使用快捷键:Ctrl+鼠标划在这个模块上。python标准库有很多,可以课外查资料了解。自定义模块的导入案例在下一小节《包和包管理》详细讲说。
## 五、包和包管理
### 1、包定义
为了更好地管理多个模块源文件,Python 提供了包的概念。那么问题来了,什么是包呢?
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块源文件;从逻辑上看,包的本质依然是模块。因此导入包和导入模块的语法完全相同
### 2、包的创建步骤:
- 1、建立一个名为包名字的文件夹
- 2、在该文件夹下创建一个__init__.py文件
- 3、根据需要在该文件夹下存放脚本文件、已编译扩展及子包。
- 4、import pack.m1
例如:先创建一个pack的文件夹,里面创建m1.py,text.py,__init__.py,含有__init__.py的文件夹就被称作为包。那么,如果text.py需要调用pack的m1的内容,text.py中应该写:
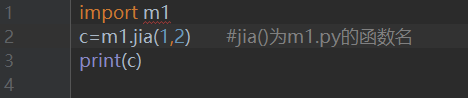
### 3、同目录下模块间调用示例
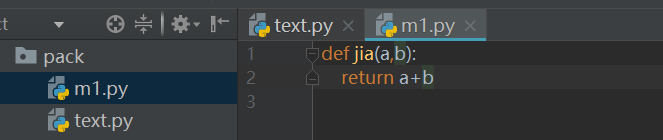
建立一个目录pack,在目录下放置两个模块:m1.py用来放置自定义函数,text.py用于调用m1.py模块中的函数并输出测试结果。注意本次并未在pack目录下放置__init__.py文件。
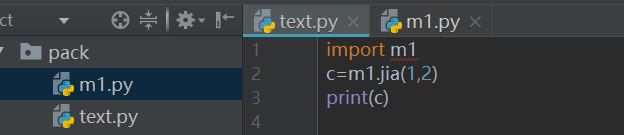
执行text.py,打印结果为:3。
除了直接导入整个模块,还可以选择性的导入:from m1 import jia,这个导入模式也是可以的。
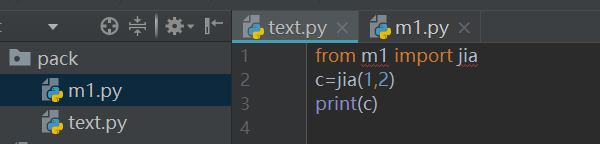
注意一下这两种方式的区别:直接导入整个模块后,Python是将模块名作为导入模块的指针(PS:可以认为模块名变量保存了导入模块加载到内存后的地址),所以每次调用都需要前缀模块名。而导入模块部分部分内容的方式是将导入模块的具体内容的名(比如函数名、变量名)作为导入部分内容的指针,所以可以直接使用函数名、变量名。总结起来就是,import了谁,谁就被本模块认识了。
### 4、跨目录模块间调用示例
在pack下建立新目录pack1,将text.py文件放于根目录下,将m1.py和__init__.py放于pack1下。
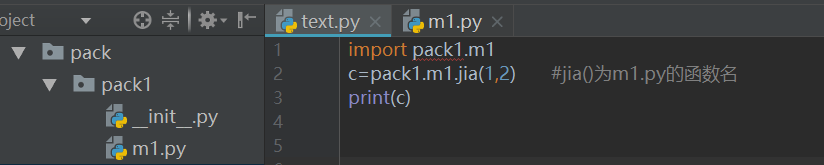
执行该代码,结果为:3。
当然在windows下包和模块的管理远非这么简单,暂时我们知道如何调用自定义的包和模块即可。
## 六、课堂练习
#### 1、在一个模块中定义一个生成器,这个生成器可以生成斐波拉契数列,在另一个模块中使用这个生成器,得到斐波拉契数列。斐波拉契数列:数列中每一个数的值都等于前两个数相加的值。[1,1,2,3,5,8,13,21,34,55,....]
## 七、上一节课堂练习答案
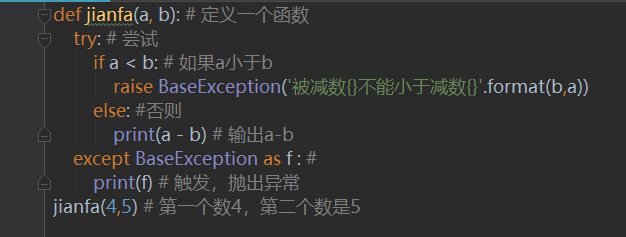
#### 1、编写一个计算减法的方法,当第一个数小于第二个数时,抛出“被减数不能小于减数"的异常
#### 2、定义一个函数func(filename) filename:文件的路径。函数功能:打开文件,并且返回文件内容,最后关闭,用异常来处理可能发生的错误。

如果文件a.txt存在,则返回a.txt文件的全部内容;如果文件a.txt不存在,则报错:[Errno 2] No such file or directory: 'a.txt'
