Siamese系列的核心
将整张图片和目标框 用相同的网络进行提取特征,然后再将目标框的特征作为卷积核和整个图片求卷积。
最后生成的是一层的Feature Map,将置信度最高的地方这个区域看作是目标。
如果有5个人,并不是将上述执行5次
整张图片执行一次,5个目标框分别执行一次,5个目标框的特征图作为卷积和整张图的卷积进行卷积操作,
生成5层的feature map。
为什么成Siamese系列为短时跟踪呢?
由上述解释可以看出来Siamese是可以做多目标跟踪的,所以不能以单目标多目标来区分
由于Siamese提取特征单调,许多先验知识没有考虑到,对Re-ID也没有考虑,所以只能用于短时跟踪。
Siamese-FC
整体框架
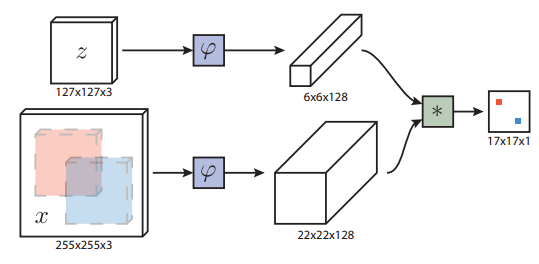
目标z执行φ 卷积操作,得到6*6*128的特征图φ(z)
图片x执行相同的Φ卷积操作,得到22*22*128的特征图φ(x)
然后执行g(φ(x),φ(z)) (这里可以是欧式距离,但是一般这里都是卷积操作,卷积核是φ(z))得到一个置信度图
损失函数的一些细节
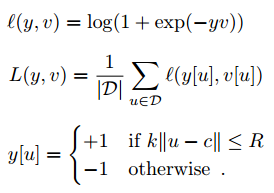
l:一个点的损失
y:真实的label,{-1, 1}
v:最后的置信度图中一个点
D:最后特征图上所有的点
R:表示,只要在正确的一个半径内,都算预测正确
最后17*17的置信度图中置信度最高的一点,映射到x的一个区域,这个区域就是跟踪的目标
Siamese RPN
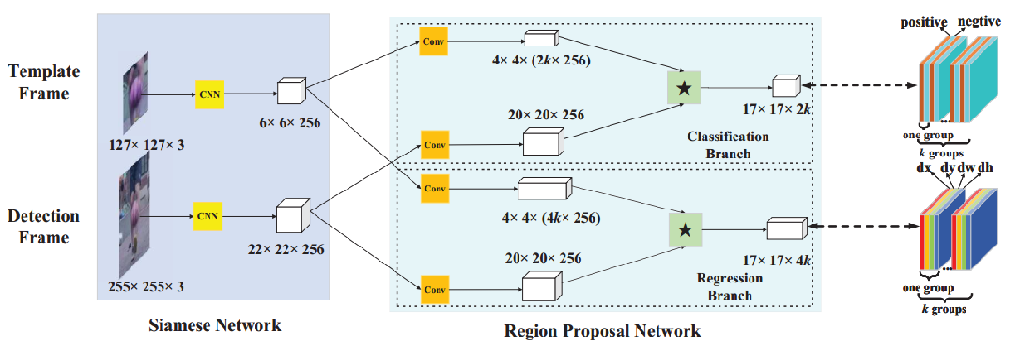
对于tracking task 相邻两帧之间的差别不是很大,因此,我们的anchor数目比较少。
而detection task (也就是faster RCNN任务中)差别很大,所以anchor数目比较多》
tracking as one-shot detection
对于detection任务中,所有的类别都是提前设置好的,或者说已知的,
每个类别的样本虽然可能不平衡,但是数量肯定不少,因此网络可以在训练的时候多次的学习
但是对于跟踪任务,我们跟踪的目标可能在我们训练集里面没有见过,
网络只有在我们画框的时候才第一次见到,
因此这里提到了one-shot(可以搜一下one-shot learning)
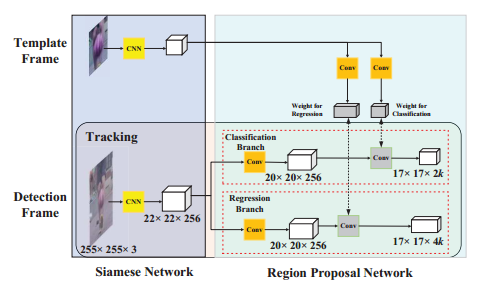

如何加速的
template分支只有在第一帧的时候才进行计算,将计算结果进行保留
视频每次都是对第一帧中的目标框的跟踪,
这样加速了计算。
假如一个视频总共1000帧,template分支只计算1次,detection分支计算1000次
候选区选择策略
忽略离中心很远的bbox
我们只在中心的g*g区域内产生g*g*k个anchor;
而不是 整个m*n的特征图上产生m*n*k个anchor
使用cosine window 并且使用尺寸改变的惩罚来对候选框的score进行修改
DaSiamRPN
研究背景
问题一:之前的只能区分没有语义的背景,带有语义的背景是个干扰项,具体看fig1
采用一个有效的数据增强方法
问题二:在跟踪中相似物体的干扰
设计了DaSiamRPN这个网络,
问题二:(对没有看错,这两个都是在下面一起讲的)之前大多数的tracker不能更新model,尽管他们模型固定可以加快速度。
问题三:最近的Siamese 使用的是local search 策略,这样不能处理目标重叠和目标走出视野的问题,也就不能长时跟踪了
提出了一个简单有效的 local -to -global search region strategy
问题一
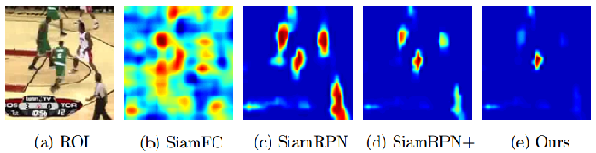
描述
FC:即便是区别很大的背景,也有很高的得分;
RPN:所有的人,只要是人。都有很高的得分;
RPN+:所有绿衣服的人,只要是外表很相似的,都有很高的得分
Da:只有目标才有很高的得分
造成的原因分析
FC:特征提取网络来自 ImageNet中的预训练模型,这个模型是没有进行语义区分的
RPN:训练数据来自相同视频中不同的帧,对于每一个搜索区域来讲,没有语义的区域占了大多数,(半个人等等情况吧)
我们只是使用了第一帧的目标框,但是第一帧的背景区域这个信息我们没有利用起来
解决方法
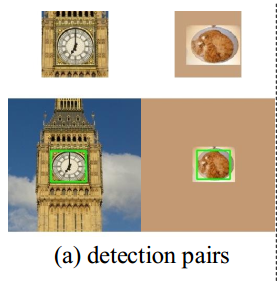



a):是我们图片和检测框
b):同一类的negative pirs
c):不是同一类得到negative pairs
上面扩展的都是和背景相似的颜色
这样做就相当于有了实例区分的能力
并且发现用motion blur能更好,所以用了这个动作模糊数据增强
问题二
产生原因
目标框和general 的representation 领域不能对齐
解决方法
提出了distractor-aware 模型,将general representation 转换到了video 领域

P:表示前k个相似的区域,作为候选区域
di:表示大于某个阈值的区域,
整体含义:从前k个得分最高的区域进行挑选,并且考虑了有一定迷惑性的区域。
效果如下



问题三:
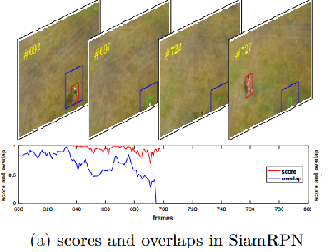


问题描述
目标out of view 置信度还是那么高,这样明显是不正确的。表明,SiamFC/RPN,都是跟踪一个目标中心度最高的物体
解决方法
目标从视野中消失后,将搜索区域增大。这个trick是挺简单的
SiamRPN++
研究背景
发现之前的Siam系列不能使用resnet这些深层的网络,只能使用类似AlexNet的网络
为什么呢?因为目标追踪需要保持空间不变性,只有zero padding的AlexNet满足
创新点
一:证明深层的网络破坏了 translation的不变性,因此精度在降低
二:提出了一个有效的sampling 策略,打破了translation 不变性的限制,从而可以使用深层网络
三:layer wise 特征提取
四:depth-wise 特征提取
创新点一
Siamese一个简单公式
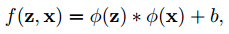
他需要满足的条件
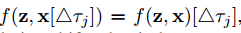
x整张图平移后求相似性,和求完相似性然后平移

这个算是卷积的对称性吧
因为FC是在求置信度,所以需要对称性,但是SiamRPN是在求回归,因此就不满足相似性
这个怎么做呢?
他是引入了depth wise conv,这样既减少了计算量,也不满足了对称性
为什么不满足呢?
search 对 targe的每个channel进行卷积,和 target 对search的每个通道进行卷积结果是不一样的。所以就不满足对称性了
理论和实验证明,深度的网络不满足
创新点二
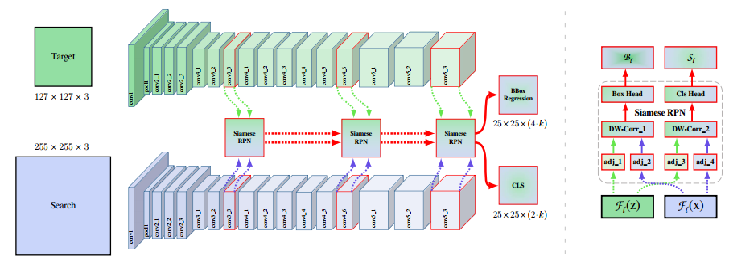
1、4th stage 和5th stage 步长为1,总体的缩小8倍
2、每个stage结束添加一个1*1的卷积,将通道降低为256
3、中心搜索区域设置为7*7,降低计算量
4、Resnet的学习率是RPN的十分之一
5、SiamFC中正样本的位置始终在图片的中央,这样做网络会记住这个位置就在中央。应该将正样本均匀分布在中心点附近
具体做法
训练的时候search region会移动,以前是以目标为中心crop 255的图片,现在是以目标周围的某个点为中心,让目标不再是search region的中心。这个只和训练有关,测试还是以上一帧目标位置为中心
创新三:
layer wise:stage3,stage4,stage5的分辨率一样。将多个RPN进行相加
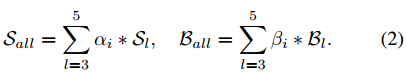
创新四:deepwise 就是mobilenet中的deepwise
SiamMask
这个只是多了一个mask分支,