简介: 压测场景下的 TIME_WAIT 处理

1. 序
某专有云项目具备压测场景,在Windows的压测机上用 LoadRunner 进行业务的压力测试,压测运行一段时间后出现大量端口无法分配的报错。
其实通过问题描述,以及 Windows的报错信息基本确定是压测机的问题。但可能原因较多,一直未能达成一致。所以,趁机分析了客户端的压测机成为压测瓶颈的可能,除了CPU、网络、 I/O 等机器性能参数外,仍需考虑网络协议引入的资源短缺问题。
注:以下内容的目的是理清TCP协议中比较模糊的内容,对协议比较熟悉的可以忽略。
2. TIME_WAIT基础:RFC 793 TCP协议
众所周知, TCP存在三次握手,四次挥手过程。其具体设计的目的,简而言之,是为了在不稳定的物理网络环境中确保可靠的数据传输;因此,TCP在具体实现中加入了很多异常状况的处理,整体协议就变得比较复杂。
要理解TCP协议,推荐阅读 RFC 793,可参考文后链接了解详情[1]。同时,也要理解“TCP state transition”状态机,如下图所示,可参考文后资料了解详情[2]。
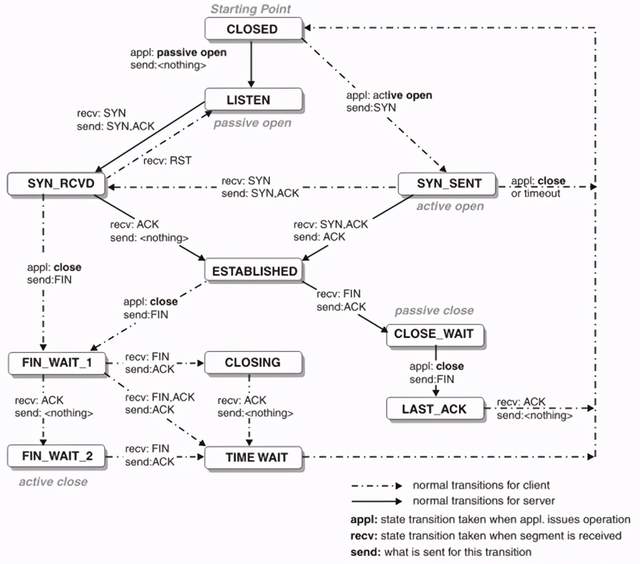
图1. TCP状态转换图
本文仅针对 TW 在TCP协议中的作用进行讨论,不涉及整体协议的分析。四次挥手后的TIME_WAIT 状态,后续将以TW缩写替代。
2.1 TW 作用
首先,主要作用是保证TCP连接关闭的可靠性。
考虑下在四次挥手过程中,如果主动关闭方发送的LAST_ACK丢失,那么被动关闭方会重传FIN。此时,如果主动关闭方对应的TCP Endpoint没有进入TW状态而是直接在内核中清理了,根据协议,主动关闭方会认为自己没有打开过这个端口,而以RST响应被动关闭方重传的FIN。最终该行为导致被动关闭方认为连接异常关闭,在业务上可能会收到异常报错等情况。
其次,TW状态同时也能避免相同的TCP端口收到在网络上前一个连接的重复数据包。
理论上,数据包在网络上过期时间对应即MSL(Maximal Segment Lifetime),随着操作系统的不断发展,也有例外情况,这部分搜索PAWS应该可以看到不少类似的文章说明。
再次,端口进入 TW 状态 同时也避免了被操作系统快速重复使用的可能。
2.2 TW形成的原因
当一台主机操作系统主动关闭TCP Endpoint(socket)时,该TCP Endpoint进入TW状态。以Windows为例,Windows内核会对 TCP Endpoint 数据结构进行相应清理,然后放入额外的 TW queue 中,设置2MSL 的定时器,等待定时器超时后调用对应的释放代码。Linux上的实现也是类似。
目前较多的说法是"TCP连接"进入TW ,但我们可能需要理解 "连接" 其实是抽象的概念。实际上"连接"在逻辑上存在,因为客户端和服务器端以及中间可能涉及的4层设备同时为一次传输创建了关联的TCP资源(Endpoint,或者 Session)。准确理解TW状态,即TCP EndpointTW进入TW状态。
2.3 小结
TW 是为了保证 TCP 连接正常终止(避免端口被快速复用),也是为了保证网络中迷失的数据包正常过期(防止前一个连接的数据包被错误的接收)。
TW暗杀术,可参考文后资料了解详情[3]。
3. 概念澄清
欢迎讨论
几个可能比较模糊的地方,明确如下:
- 作为连接双方,客户端和服务器端的TCP Endpoint都可能进入 TW 状态(极端情况下,可能双方同时进入 TW 状态)。
该情况在逻辑上是成立的,可参考文后资料了解详情[4]。
- TW 是标准的一部分,不代表TCP端口或者连接状态异常。(这个概念很重要,避免陷入某些不必要的陷阱。)
- CLOSE_WAIT 尽管也是标准的一部分,但它的出现预示着本端的 TCP Endpoint 处于半关闭状态,原因常常是应用程序没有调用 socket 相关的 close 或者 shutdown。可能的原因是应用程序仍有未发送完成的数据,该情况下CLOSE_WAIT 最终还是会消失的。 具体描述这部分,长期有 CLOSE_WAIT 状态的端口缓慢累积,这种情况是需要引起注意的,累积到一定程度,端口资源就不够了。
针对前面的 TCP Endpoint 这个词语,可能很多人不太了解,这边也简单说明下:
在Windows 2008 R2之前,socket是用户态(user mode) 的概念,大多数Windows socket应用程序基本都基于Winsock开发,由中间层AFD.sys 驱动翻译成内核 tcpip.sys 协议栈驱动 所能接受的TCP Endpoint数据结构。在2008 R2之后,微软为了方便内核的网络编程,在Windows Kernel中提供WSK,即Winsock在内核的实现。文中提到的TCP Endpoint是在Windows内核中由TCPIP.sys驱动文件实现的TCP数据结构,也对应Linux上的socket。该文简单以 Endpoint 代指内核的"socket"。
4. TW 优化手段
对于Linux,优化手段已经进行了很多讨论了,以Centos为例,
- 在timestamps启用的情况下,配置 tcp_tw_reuse 和tcp_tw_recycle。
针对客户端,连接请求发起方。
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
针对服务器端,连接请求接收方
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_recycle = 1
注:tcp_tw_recycle的启用会带来一些 side effect,具体在NAT地址转换场景下,容易发生连接异常问题。
可参考文后资料了解详情[4]。
- 配置 max_tw_buckets,连接请求发起方接收方通用,但需要注意这个选项本身有违 TW 设计的初衷。
net.ipv4.tcp_max_tw_buckets = 5000
- 配置 ip_local_port_range,连接请求发起方。
net.ipv4.ip_local_port_range = 5000 65535
针对Windows ,资料较少,这边借之前的工作经验,总结如下:
- Windows Vista / Windows Server 2008 之前的操作系统,注册表
端口范围:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
MaxUserPort = 0n65534
TW 超时时间:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
TcpTimedWaitDelay = 0n30
- Windows 7 / Windows Server 2008 R2 及其之后的版本
端口范围:
netsh int ipv4 set dynamicport tcp start=1025 num=64511
TW 超时时间:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
TcpTimedWaitDelay = 0n30
Windows Server 2012 and earlier: 30-300 (decimal)
Windows 8 and earlier: 30-300 (decimal)
Windows Server 2012 R2 and later: 2-300 (decimal)
Windows 8.1 and later: 2-300 (decimal)
注:
- 任何涉及注册表的修改,只有重启机器才会生效。
- 与 Linux不同,Windows 没有快速回收机制,不存在快速回收 TW 的可能,只能等待2MSL过期(即TcpTimedWaitDelay)。
- Windows唯一能快速回收TW状态的Endpoint 的情况:
新连接请求的SEQ序列号>TW状态的Endpoint记录的SEQ序列号。
此时,内核会认为该 SYN 请求合法。 这里,这个TW 状态的 TCP Endpoint 一定是在服务端(通过socket accept 打开的 服务端口)。(为了这个能力,Windows 的 RFC 1323 选项必须打开,内容可以自行搜索。)
5. 压测客户端无法分配端口的原因分析
端口无法分配有两种可能:
- 完全随机的动态端口请求,报错端口分配异常,基本是操作系统没有可用端口。
- 指定端口的绑定申请报错端口分配异常,可能存在端口使用冲突问题。
针对第一种情况,首先需要通过 netstat -ano 进行快速检查,分析是否存在端口占满的情况,以及占满端口的TCP Endpoint状态。针对不同的状态,考虑不同的方案。
比如,极端情况下,没有任何异常的服务器上,端口分配失败问题,可参考文后资料了解详情[5]。
以Windows操作系统TW状态Endpoint占满可用端口场景为例(在Linux上发生的可能性较低),分析问题前需要大概了解 Windows 上端口分配原理。
- Windows和Linux在动态分配端口的机制上有很大的不同。
- Linux以粗浅的理解应该是针对五元组的分配,即可能存在相同的动态端口访问不同服务器的服务端口。
- Windows的动态端口分配实现基于Bitmap查找,无论访问哪里,动态端口的池子最大为 1025 – 65536,即64511个。
- 考虑到最短30秒的 TW 超时时间,如果按照 64511/29 = 2225 ports/s 的速度去创建端口,那么很可能在30秒后持续发生端口无法分配的问题。
- 这还是在连接处理比较快速的情况下,如果连接建立后不关闭,或者关闭时间比较久,创建端口的速度仍需持续下降来规避端口问题。
理解了 TW 的形成原因,相应的解决方案也就比较清楚了。
- 降低应用程序创建端口的速度。考虑连接持续时间和TW超时时间,计算相对合理的连接建立速度。不过,物理机操作系统、CPU/内存、网络IO等均可能影响连接状态,精确计算很难;同时,就应用程序而言,降低端口创建速度需要额外的逻辑,可能性不大。
- 在这个压测场景下,通过增加机器的方式来变相减少端口的需求。压测一般考虑某个固定阈值下整体系统的响应情况。在压力固定的情况下,可以通过分散压力的方式来减少端口资源的占用。
- 改变连接的行为,使用持久连接(注:非HTTP的长连接),例如针对500个并发,仅建立 500 个连接。好处显而易见,但坏处也很明显,持久连接不大符合用户真实行为,压测结果可能失真。同时,该方法需要应用程序上的支持。
- 不让机器的TCP Endpoint进入TW状态,可参考以下2种方案。
a) 不让该机器主动关闭连接,而让对方主动关闭。这样,该主机进入被动关闭进程,在应用关闭TCP Endpoint之后,可直接释放端口资源。一些协议本身就有控制是否保持连接或者请求对方关闭连接的行为或者参数,在考虑这类问题的时候,可以适当进行利用。比如 HTTP 的长短连接,可参考文后资料了解详情[4]。b) 通过TCP Reset强制释放端口。TCP Reset可以由任何一方发出,无论是发送方还是接收方,在看到TCP Reset之后会立刻将对应TCP Endpoint拆除。
这里,可设置 socket 的 SO_LINGER选项,比如配置Nginx,可参考文后官方文档了解详情[6]。
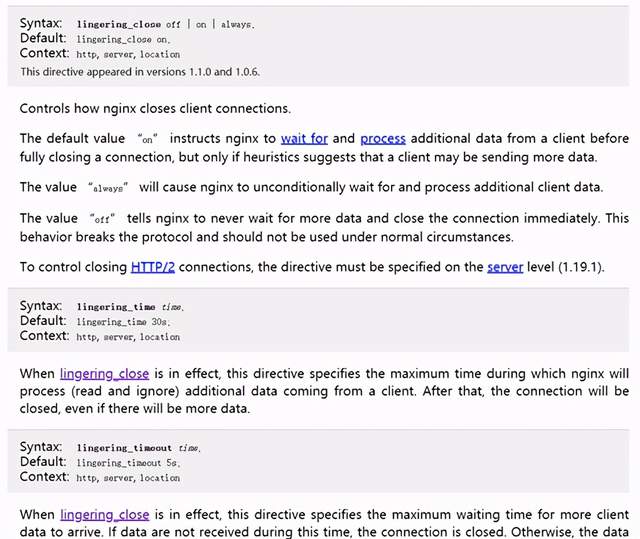
图2:Nginx Lingering配置参考说明
针对压测工具本身,官方网站上也有类似 ABRUPT 选项,可参考文后官方文档了解详情[7]。

图3:LoadRunner ABRUPT配置选项说明
作者:陈鸽
本文为阿里云原创内容,未经允许不得转载