1.安装
pip install openpyxl
2.模块openpyxl的基本使用
import openpyxl import datetime # 实例化对象excel对象 excel_obj = openpyxl.Workbook() # excel 内当前活跃的sheet工作表 excel_obj_sheet = excel_obj.active # 给单元格赋值 excel_obj_sheet['A1'] = 4 excel_obj_sheet.append([1, 2, 3]) excel_obj_sheet['A3'] = datetime.datetime.now() # 文件保存 excel_obj.save('sample.xlsx')
运行后,文件内容:

3.模块openpyxl详细
3.1创建工作簿
不需要提前在文件系统上创建文件,直接就可以使用 openpyxl 开始创建表格。先导入 Workbook 类,再使用 Workbook.active 方法获取一个工作表:
from openpyxl import Workbook wb = Workbook() ws = wb.active
默认情况下 Workbook.active(value) 方法中的 value 为 0,即使用此方法获得第一个工作表,我们可以修改此值。也可以使用 Workbook.create_sheet() 方法创建新的工作表:
# 在末尾插入(默认) ws1 = wb.create_sheet("Mysheet") # 插入第一个位置 ws2 = wb.create_sheet("Mysheet", 0) # 倒数第二个位置插入 ws3 = wb.create_sheet("Mysheet", -1)
我们可以随时通过 Worksheet.title 属性更改工作表名称:
ws.title = "New Title"
默认情况下,工作表选项卡的背景颜色为白色,我们可以通过 Worksheet.sheet_properties.tabColor 属性修改颜色:
ws.sheet_properties.tabColor = "1072BA"

给工作表命名后,就可以将其作为工作簿的键值,以指向对应的工作表,并可以使用 Workbook.sheetname 属性查看工作簿中所有工作表的名称,亦可以遍历工作表:
ws3 = wb["New Title"] print(wb.sheetnames) # ['Sheet2', 'New Title', 'Sheet1'] for sheet in wb: print(sheet.title)
我们可以复制某个工作簿,创建一个副本。该行为仅复制单元格(值、样式、超链接、注释)和某些工作表属性(尺寸、格式、属性),如果工作簿以 read-only 或 write-only 只读模式打开,则不能复制工作表:
source = wb.active
target = wb.copy_worksheet(source)
3.2操作数据
单元格可以直接作为工作表中的键值进行访问,例如返回 A4 处的单元格,如果不存在则创建一个单元格,可以直接分配值:
c = ws['A4'] ws['A4'] = 4
一个单元格
通过 Worksheet.cell() 方法可以使用 行 和 列 定位要访问的单元格:
d = ws.cell(row=4, column=2, value=10)
多个单元格
我们可以通过切片访问单元格范围,行或列的范围可以用类似方法获得:
cell_range = ws['A1':'C2'] colC = ws['C'] col_range = ws['C:D'] row10 = ws[10] row_range = ws[5:10]
也可以使用 Worksheet.iter_rows() 或 Worksheet.iter_cols() 方法获取行、列,但是由于性能原因,这两个方法在 只读 模式下不可用:
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2): for cell in row: print(cell) # <Cell Sheet1.A1> # <Cell Sheet1.B1> # <Cell Sheet1.C1> # <Cell Sheet1.A2> # <Cell Sheet1.B2> # <Cell Sheet1.C2> for col in ws.iter_cols(min_row=1, max_col=3, max_row=2): for cell in col: print(cell) # <Cell Sheet1.A1> # <Cell Sheet1.A2> # <Cell Sheet1.B1> # <Cell Sheet1.B2> # <Cell Sheet1.C1> # <Cell Sheet1.C2>
如果需要遍历所有行或列,则可以使用 Worksheet.rows 或 Worksheet.columns 属性,但是同样在 只读 模式下不可用:
ws = wb.active ws['C9'] = 'hello world' tuple(ws.rows) # ((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>), # (<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>), # (<Cell Sheet.A3>, <Cell Sheet.B3>, <Cell Sheet.C3>), # (<Cell Sheet.A4>, <Cell Sheet.B4>, <Cell Sheet.C4>), # (<Cell Sheet.A5>, <Cell Sheet.B5>, <Cell Sheet.C5>), # (<Cell Sheet.A6>, <Cell Sheet.B6>, <Cell Sheet.C6>), # (<Cell Sheet.A7>, <Cell Sheet.B7>, <Cell Sheet.C7>), # (<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>), # (<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>)) tuple(ws.columns) # ((<Cell Sheet.A1>, # <Cell Sheet.A2>, # <Cell Sheet.A3>, # <Cell Sheet.A4>, # <Cell Sheet.A5>, # <Cell Sheet.A6>, # ... # <Cell Sheet.C9>))
仅值
如果只需要工作表中的值,则可以使用 Worksheet.columns 属性,这会遍历工作表中的所有行,但仅返回单元格的值:
for row in ws.values: for value in row: print(value)
通过 Worksheet.iter_rows() 并 Worksheet.iter_cols() 可以获取 values_only 参数,只返回单元格的值:
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2, values_only=True): print(row) # (None, None, None) # (None, None, None)
如果我们只需要工作表的 最大行数 和 最大列数,可以使用 max_row 和 max_column 属性获取,例如一个4行15列的工作表:
print(ws.max_row) # 4 print(ws.max_column) # 15
3.3数据存储
有了 Cell 就可以为其分配一个值:
c.value = 'hello, world' print(c.value) # 'hello, world' d.value = 3.14 print(d.value) # 3.14
保存到文件
保存工作簿的最简单、安全的方法是使用对象的 Workbook.save() 方法:
wb = Workbook() wb.save('balances.xlsx')
如果文件已经存在,此操作将覆盖现有文件,不会抛出异常或警告。
另存为流
如果要将文件保存到流中,例如在使用Web应用程序(Pyramid、Flask、Django)时,只需使用 NamedTemporaryFile() 方法即可:
from tempfile import NamedTemporaryFile from openpyxl import Workbook wb = Workbook() with NamedTemporaryFile() as tmp: wb.save(tmp.name) tmp.seek(0) stream = tmp.read()
我们也可以指定属性 template=True,将工作簿另存为模板:
wb = load_workbook('document.xlsx') wb.template = True wb.save('document_template.xltx')
或将 template 属性设置为 False(默认),以另存为文档:
wb = load_workbook('document_template.xltx') wb.template = False wb.save('document.xlsx', as_template=False)
3.4从文件加载
可以通过 openpyxl.load_workbook() 打开现有的工作簿:
from openpyxl import load_workbook wb2 = load_workbook('test.xlsx') print(wb2.sheetnames) # ['Sheet2', 'New Title', 'Sheet1']
3.5实例
写工作簿
from openpyxl import Workbook from openpyxl.utils import get_column_letter wb = Workbook() dest_filename = 'empty_book.xlsx' ws1 = wb.active ws1.title = "range names" for row in range(1, 40): ws1.append(range(600)) ws2 = wb.create_sheet(title="Pi") ws2['F5'] = 3.14 ws3 = wb.create_sheet(title="Data") for row in range(10, 20): for col in range(27, 54): _ = ws3.cell(column=col, row=row, value="{0}".format(get_column_letter(col))) print(ws3['AA10'].value) # AA wb.save(filename = dest_filename)
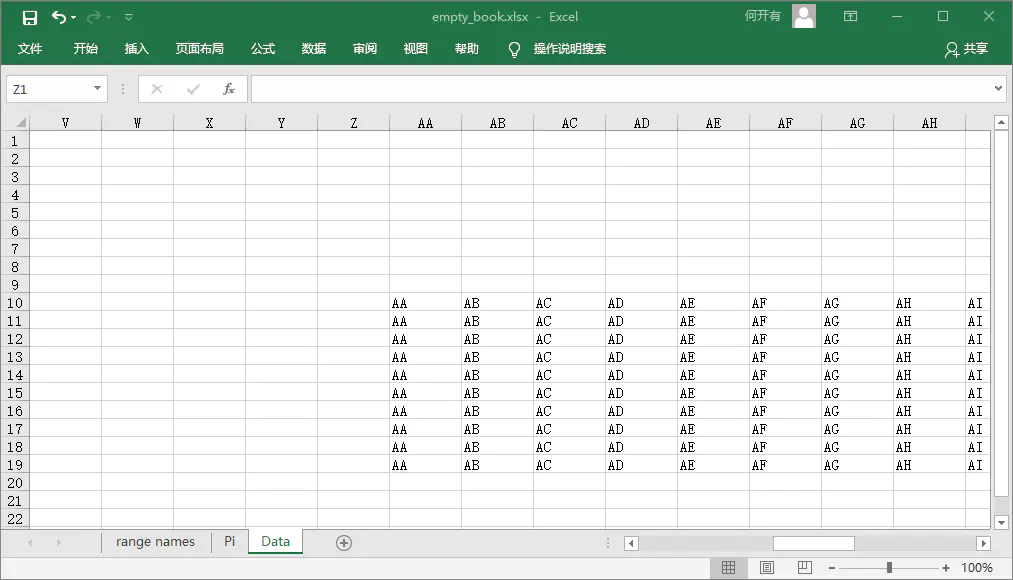
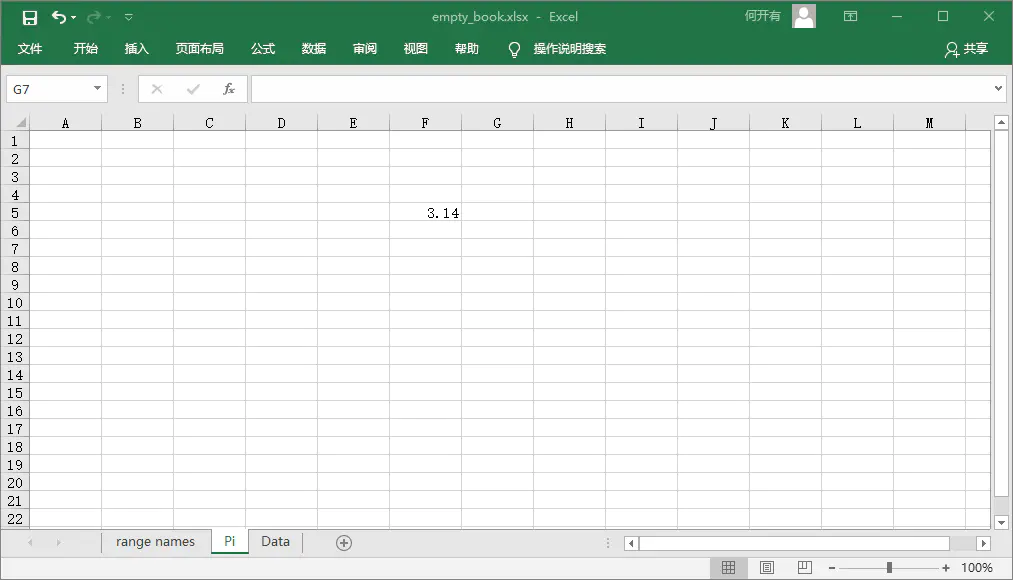
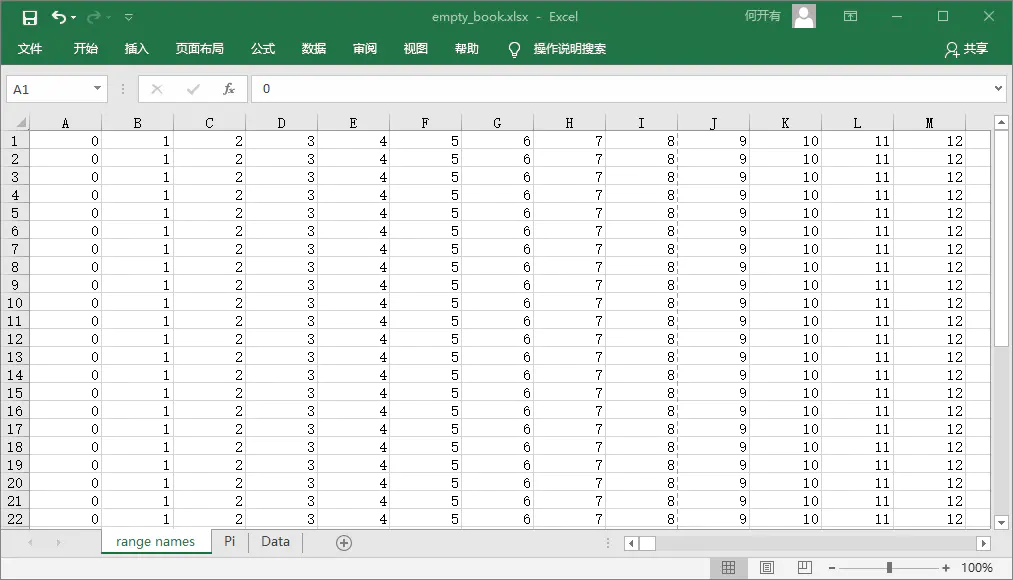
读工作簿
from openpyxl import load_workbook wb = load_workbook(filename = 'empty_book.xlsx') sheet_ranges = wb['range names'] print(sheet_ranges['D18'].value) # 3
使用数字格式
import datetime from openpyxl import Workbook wb = Workbook() ws = wb.active # 使用 Python datetime 设置日期 ws['A1'] = datetime.datetime(2010, 7, 21) ws['A1'].number_format # 'yyyy-mm-dd h:mm:ss'
使用公式
from openpyxl import Workbook wb = Workbook() ws = wb.active # 添加一个简单的公式 ws["A1"] = "=SUM(1, 1)" wb.save("formula.xlsx")
需要注意,函数名称必须为 英文 名称,函数参数必须用 逗号 分隔。openpyxl 不会评估公式,但是可以检查公式的名称:
from openpyxl.utils import FORMULAE print("HEX2DEC" in FORMULAE) # True
合并单元格
from openpyxl.workbook import Workbook wb = Workbook() ws = wb.active ws.merge_cells('A2:D2') ws.unmerge_cells('A2:D2') # 或者 ws.merge_cells(start_row=2, start_column=1, end_row=4, end_column=4) ws.unmerge_cells(start_row=2, start_column=1, end_row=4, end_column=4)
合并单元格时,除左上角以外的所有单元格都将从工作表中被删除。
插入图像
from openpyxl import Workbook from openpyxl.drawing.image import Image wb = Workbook() ws = wb.active ws['A1'] = 'You should see three logos below' # 创建图像 img = Image('logo.png') # 添加到工作表并锚定在单元格旁边 ws.add_image(img, 'A1') wb.save('logo.xlsx')
折叠与轮廓
import openpyxl wb = openpyxl.Workbook() ws = wb.create_sheet() ws.column_dimensions.group('A','D', hidden=True) ws.row_dimensions.group(1,10, hidden=True) wb.save('group.xlsx')
4.通用方案读取类


from os.path import isfile from openpyxl import load_workbook class ExcelToDict: """ 将Excel文件对象转成Python字典对象 """ def __init__(self, file_dir, title_row=0): # 工作簿文件的路径 self.file_dir = file_dir # 标题行位于第几行 self.title_row = int(title_row) self.data_dict = {} self.work_book = None def open_object(self): """打开工作簿对象""" valid = isfile(self.file_dir) # file_dir指向的文件是否不存在 if not valid: raise Exception('文件路径 {0} 不存在'.format(self.file_dir)) self.work_book = load_workbook(filename=self.file_dir) def read_excel(self): """读取工作簿数据""" if not self.work_book: raise Exception('需要先调用 open_object() 方法以打开工作簿对象') for sheet_name in self.work_book.sheetnames: # 每个工作表的字典 data_dict_sheet = {'title_row': [], 'value_row': {}} # 获取工作表对象 ws = self.work_book[sheet_name] # 预先创建工作表中每一行的字典 for i in range(ws.max_row - 1 - self.title_row): data_dict_sheet['value_row'][i] = {} # 遍历所有列 columns = tuple(ws.columns) for column in columns: # 每一列的标题 title = column[self.title_row].value # 记录每列的标题 data_dict_sheet['title_row'].append(title) row_num = 0 # 遍历每一列中的所有值 for col in column: # 忽略每一列的标题行 if column.index(col) <= self.title_row: continue data_dict_sheet['value_row'][row_num][title] = col.value row_num += 1 # 记录每个工作表的数据字段 self.data_dict[sheet_name] = data_dict_sheet def check(self, check_item=None, sheet_name=None, sheet_index=0): """ 在所选工作表中校验是否包含业务需要的所有标题名称 :param check_item: 所选工作表中需要校验的标题列表 :param sheet_name: 以名称形式选择工作表(优先) :param sheet_index: 以下标形式选择工作表 :return: {'result': True, 'exception': None} """ if not self.data_dict: return {'result': False, 'exception': '需要先调用 read_excel() 方法以读取工作簿数据'} if check_item is None: check_item = [] if sheet_name: if sheet_name not in self.data_dict: return {'result': False, 'exception': '不存在名为 {0} 的工作表'.format(sheet_name)} # 直接获得对应的工作表数据 data_sheet = self.data_dict[sheet_name] else: # 通过下标获取对应的工作表名称 data_dict_keys = tuple(self.data_dict.keys()) if len(data_dict_keys) <= int(sheet_index): return {'result': False, 'exception': '不存在下标为 {0} 的工作表'.format(sheet_index)} _sheet_name = data_dict_keys[int(sheet_index)] # 间接获得对应的工作表数据 data_sheet = self.data_dict[_sheet_name] # 判断工作表中是否包含业务需要的所有标题 if not set(check_item).issubset(set(data_sheet['title_row'])): return {'result': False, 'exception': '工作表中未包含业务需要的 {0} 标题'.format(check_item)} return {'result': True, 'exception': None} if __name__ == '__main__': excel_to_dict = ExcelToDict('C:/Users/hekaiyou/Desktop/新建 Microsoft Excel 工作表.xlsx') excel_to_dict.open_object() print('工作簿对象:', excel_to_dict.work_book) excel_to_dict.read_excel() print('工作簿数据:', excel_to_dict.data_dict) print('工作簿校验(异常演示):', excel_to_dict.check(['标题四'])) print('工作簿校验(正常演示):', excel_to_dict.check(['标题一', '标题二']))
5.参考代码
#coding=utf-8 import openpyxl from openpyxl import Workbook # 默认可读写,若有需要可以指定write_only和read_only为True # 新建Excel表格 wb = Workbook('new_excel.xlsx') # 加载本地已有文件 wb2 = openpyxl.load_workbook('excel.xlsx') # 获取所有sheet的名称 # 老版openpyxl支持方法,新版建议直接使用属性sheetnames # print(wb.get_sheet_names()) # print(wb2.get_sheet_names()) print('sheetnames') print(wb.sheetnames) print(wb2.sheetnames) # 根据sheet名字获得sheet # 老版办法,建议使用新版本方法 # a_sheet = wb2.get_sheet_by_name('Sheet1') a_sheet = wb2['Sheet1'] # 获取sheet的标题 print(a_sheet.title) # 获取当前显示的sheet页,两种方式都可以 sheet = wb2.active # sheet = wb2.get_active_sheet # 获取单元格 a4 = sheet['A4'] print('(%s,%s) is %s.' % (a4.column, a4.row, a4.value)) # 获得最大列和最大行 print('获得最大列和最大行') print(sheet.max_column) print(sheet.max_row) # 获取行和列 # sheet.rows为生成器, 里面是每一行的数据,每一行又由一个tuple包裹。 # sheet.columns类似,不过里面是每个tuple是每一列的单元格。 # 因为按行,所以返回A1, B1, C1这样的顺序 for row in sheet.rows: for cell in row: print('(%s,%s) is %s.' % (cell.column, cell.row, cell.value)) print('================') # A1, A2, A3这样的顺序 for column in sheet.columns: for cell in column: print('(%s,%s) is %s.' % (cell.column, cell.row, cell.value)) # 上面的代码就可以获得所有单元格的数据。如果要获得某行的数据呢?给其一个索引就行了,因为sheet.rows是生成器类型,不能使用索引,转换成list之后再使用索引,list(sheet.rows)[2]这样就获取到第三行的tuple对象。 print('================') for cell in list(sheet.rows)[2]: print('(%s,%s) is %s.' % (cell.column, cell.row, cell.value)) # 如何获得任意区间的单元格? # # 可以使用range函数,下面的写法,获得了以A1为左上角,B3为右下角矩形区域的所有单元格。注意range从1开始的,因为在openpyxl中为了和Excel中的表达方式一致,并不和编程语言的习惯以0表示第一个值。 for i in range(1, 4): for j in range(1, 3): print(sheet.cell(row=i, column=j)) # 还可以像使用切片那样使用。sheet['A1':'B3'] # 返回一个tuple,该元组内部还是元组,由每行的单元格构成一个元组。 for row_cell in sheet['A1':'B3']: for cell in row_cell: print(cell) for cell in sheet['A1':'B3']: print(cell) # 根据字母获得列号,根据列号返回字母 # 需要导入, 这两个函数存在于openpyxl.utils from openpyxl.utils import get_column_letter, column_index_from_string # 根据列的数字返回字母 print(get_column_letter(2)) # B # 根据字母返回列的数字 print(column_index_from_string('D')) # 4