论文:
Perceptual Losses for Real-Time Style Transfer and Super-Resolution

Perceptual Losses for Real-Time Style Transfer and Super-Resolution: Supplementary Material

提出背景:
- 在之前的图像风格迁移的文章中,一般的方法是使用监督学习的方式训练一个神经网络,使用per-pixel的loss来衡量输出与ground-truth的差异,这种方法在测试的时候效果很好,而且测试数据只需要经过一个训练好的网络即可。但是,这样per-pixel的loss并不能发现图中的感知信息的差异,比如两张一模一样的图像,只有1像素偏移上的差距,尽管从感知上这俩图片一模一样,但用per-pixel的方法来衡量的话,该loss值有很大不同。
- 之前的研究表明基于perceptual的loss使用从训练好的网络里提取出的图像的高级特征来生成高分辨率的图像,然后再最小化loss生成图像,这样的优化问题很慢。
所以作者结合以上两种方法的优点,使用perceptual的loss训练网络,这个perceptual的loss方程是基于预先训练好的网络中提取的高级特征。
相关工作:
前馈图像转换:作者使用前馈神经网络完成图像的转换,在网络中,使用下采样来降低feature map的空间范围,其后跟一个网络中使用上采样来产生最终的输出图像。
感知优化:使用卷积神经网络提取出高级的特征,再用perceptual的loss来感知优化。
风格转换:作者要完成的任务一。
图像超分辨率重建:作者要完成的任务二。
方法:




图像转换网络:
本文的图像转换网络就是DCGAN网络,不使用任何池化层,取而代之的是步幅卷积或微步幅卷积在网络中进行上采样和下采样,网络体有5个残差块组成,所有的非残差卷积层之后都进行batch-normalization以及ReLU激活函数以保证图像的像素值在[0,255]之间。除了第一层和最后一层使用9x9的卷积核之外,其他卷积层都使用3x3的卷积核。

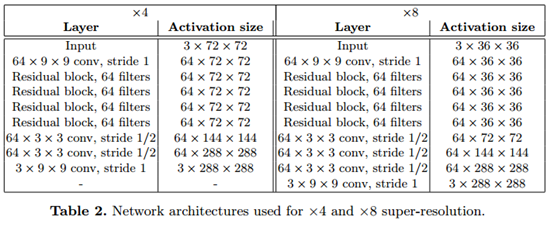
输入与输出:在风格转换的任务中输入和输出都是形状为3×256×256的彩色图像;对于超分辨率重建,有一个上采样因子f,输出是一个高分辨率的图像3×288×288,输入是一个低分辨率图像3×288/f×288/f,因为图像转换网络是完全卷积,所以在测试过程中它可以被应用到任何分辨率的图像中。
上采样和下采样:对于上采样因子为f的超分辨率,使用几个残余块,然后使用stride=1/2的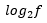 卷积层;对于风格转换,网络使用两个stride=2卷积来对输入进行下采样,然后是几个残余块,然后是两个卷积层,stride=1/2到上采样。
卷积层;对于风格转换,网络使用两个stride=2卷积来对输入进行下采样,然后是几个残余块,然后是两个卷积层,stride=1/2到上采样。
残差连接:网络体由几个残差块组成,每个残差块包含3x3的卷积层。

Perceptual的loss函数:
作者定义了两个perceptual的loss函数,分别来衡量两张图像的高级感知差距和语义差距。

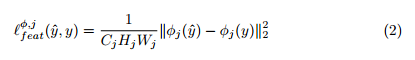
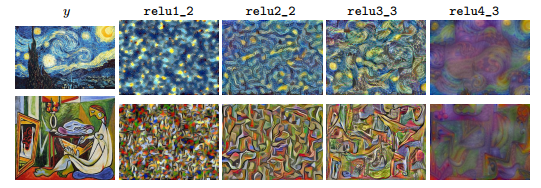
如下图所示,如果使用网络的浅层最小化内容重建loss,得到的图像跟原图几乎没差。而本文使用网络的深层,这样图像的内容和空间结构都保留下来,而颜色、纹理以及精密的形状则会丢失。


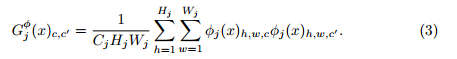




实验:
有两个图像变换任务:风格转换和单图超分辨率重建。风格转换中,前人使用白噪声图优化来生成的图像,而作者使用前馈网络产生类似的定性结果,但速度快了三个数量级。单图像超分辨率中,perceptual的loss要比per-pixel的loss效果好,主要表现在模型中的边缘和细节方面。



参考文章:
- 【论文读后感】:Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- [译] Perceptual Losses for Real-Time Style Transfer and Super-Resolution(Stanford University)
- 图像的上采样(upsampling)与下采样(subsampled)