面:说说你对Java的理解?
- 平台无关性:一次编译,到处运行
- GC:垃圾回收,不必像C++一样手动释放堆内存,由JVM自动完成
- 语言特性:泛型、反射、Lambda表达式
- 面向对象:封装、继承、多态
- 类库:Java自带的库,如并发、集合、IO、网络有关等的库
- 异常处理:抛出异常和捕获异常
面:Java如何实现平台无关性的?
答:Java源码首先被编译成字节码,Java语言在不同平台上运行时不需进行重新编译。由相应平台上的JVM将字节码转换成具体平台上的机器指令。
面:为什么不由JVM直接将源码解析成机器码去执行?
答:避免每次执行前都执行各种检查,以及扩展了兼容性即可以将别的语言(Ruby、Scala)解析成字节码去执行。
Java虚拟机
JVM是一种抽象化仿真的计算机,JVM屏蔽了与具体操作系统的相关信息。JVM的内部示意图如下:
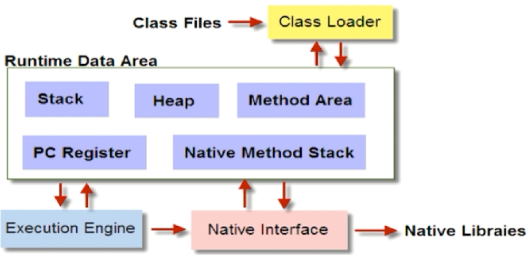
- Class Loader:依据特定格式,加载class文件到内存
- Execution Engine:对命令进行解析
- Native Interface:融合不同开发语言的原生库为Java所用
- Runtime Data Area:JVM内存空间结构模型
面:JVM如何加载.class文件?
面:谈谈反射?
答:Java反射机制是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的称为Java语言的反射机制。
面:能否写出一个反射的例子?
package com.yunche.reflect;
/**
* 用于测试反射的类
* @author yunche
* @date 2019/03/18
*/
public class Robot {
private String name;
public void sayHi(String helloSentence) {
System.out.println(helloSentence + " " + name);
}
private String throwHello(String tag) {
return "Hello " + tag;
}
}
package com.yunche.reflect;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* 通过反射的方式获取类的方法、属性
* @author yunche
* @date 2019/03/18
*/
public class ReflectSample {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException, NoSuchFieldException {
//利用forName方法并传入全类名获取该类的Class对象
Class rc = Class.forName("com.yunche.reflect.Robot");
//创建出类的实例
Robot r = (Robot) rc.newInstance();
//输出类的全限定名
System.out.println("Class name is " + rc.getName());
//Class的getDeclaredMethod获取类中所有定义了的方法,注不包括继承的方法
Method getHelllo = rc.getDeclaredMethod("throwHello", String.class);
//由于该方法是私有方法不可以在类外访问,所以这里使它能通过反射的方式在类外调用
getHelllo.setAccessible(true);
//通过Method的invoke方法使用反射的方式调用实例的方法并返回结果
Object o = getHelllo.invoke(r, "Bob");
System.out.println("throwHello result is " + o);
//通过Class的getMethod方法可以获取public、或者继承、或者实现接口的方法但不能获取private方法
Method sayHi = rc.getMethod("sayHi", String.class);
System.out.println("sayHi result is " + sayHi.invoke(r, "Welcome"));
//获取Class的属性字段
Field name = rc.getDeclaredField("name");
name.setAccessible(true);
name.set(r, "Alice");
sayHi.invoke(r, "Welcome");
}
}
输出如下:
Class name is com.yunche.reflect.Robot
throwHello result is Hello Bob
Welcome null
sayHi result is null
Welcome Alice
面:谈谈一个类(Robot)从编译到执行的过程?
- 编译器将Robot.java源文件编译成Robot.class字节码文件
- ClassLoader将字节码转换为JVM中的Class
对象 - JVM利用Class
对象实例化为Robot对象
面:谈谈ClassLoader?
答:ClassLoader在Java中的工作是在Class装载的加载阶段,其主要作用是从系统外部获得Class二进制数据流。它是Java的核心组件,所有的Class都是由ClassLoad进行加载的,ClassLoader负责通过将Class文件里的二进制数据流装载进系统,然后交给JVM进行链接、初始化等操作。它有以下4个种类:
- BootStrapClassLoader:C++编写,加载核心库java.*
- ExtClassLoader:Java编写,加载扩展库javax.*
- AppClassLoader:Java编写,加载程序所在目录
- 自定义ClassLoader:Java编写,定制化加载
自定义ClassLoader的实现:需要实现以下2个方法:
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
protected final Class<?> defineClass(String name, byte[] b, int off, int len)
throws ClassFormatError
{
return defineClass(name, b, off, len, null);
}
实例:带装载的类Mali.java如下
public class Mali {
static {
System.out.println("I am Mali");
}
}
使用命令javac编译javac Mali.java 生成class文件。
package com.yunche.reflect;
import java.io.*;
/**
* 自定义ClassLoader
* @author yunche
* @date 2019/03/19
*/
public class MyClassLoader extends ClassLoader{
private String path;
private String classLoaderName;
public MyClassLoader(String path, String classLoaderName) {
this.path = path;
this.classLoaderName = classLoaderName;
}
/**
* 用于寻找类文件
* @param name
* @return
* @throws ClassNotFoundException
*/
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] b = loadClassData(name);
return defineClass(name, b, 0, b.length);
}
/**
* 用于加载类文件
* @param name 类文件名
* @return
*/
private byte[] loadClassData(String name) {
name = path + name + ".class";
InputStream is = null;
try {
is = new FileInputStream(new File(name));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
ByteArrayOutputStream os = new ByteArrayOutputStream();
try {
byte[] buffer = new byte[1024];
int read;
while ((read = is.read(buffer, 0, buffer.length)) != -1) {
os.write(buffer, 0, read);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
os.close();
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return os.toByteArray();
}
}
package com.yunche.reflect;
/**
* 测试自定义ClassLoader是否生效
* @author yunche
* @date 2019/03/19
*/
public class ClassLoaderChecker {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
MyClassLoader mc = new MyClassLoader("C:\Users\Administrator\Desktop\", "myClassLoader");
Class c = mc.loadClass("Mali");
System.out.println(c.getClassLoader());
c.newInstance();
}
}
输出如下:
com.yunche.reflect.MyClassLoader@74a14482
I am Mali
面:谈谈类加载器的双亲委派机制?

首先自底向上查找class是否已经被装载了,若是直接返回,否则向上继续查找,若找到最顶层BoostrapClassLoader依然没有发现,说明该class没有被装载进内存成为Class对象,则需要自顶向下的尝试装载该class,若能装载成功则直接返回,否则依次向下寻找,直到最底层依然不能装载则抛出异常。
面:为什么要使用双亲委派机制去加载类?
答:避免多份同样字节码的加载,浪费内存。
类的加载方式
- 隐式加载:new
- 显示加载:loadClass、forName等
类的装载过程如下图:

面:loadClass和forName的区别?
- Class.forName得到的class是已经初始化完成了的 (MySQL加载驱动时,需要调用静态代码块完成一些操作)
- ClassLoader.loadClass得到的class是还没有链接的。(用于Spring IoC中的延迟加载机制)
Java内存模型
JVM内存模型——JDK8如下图所示:

- 线程私有:程序计数器、虚拟机栈、本地方法栈
- 线程共享:MetaSpace、Java堆
程序计数器(PC)
- 当前线程所执行的字节码行号指示器(逻辑)
- 通过改变计数器的值来选取下一条需要执行的字节码指令
- 和线程是一对一的关系即“线程私有”
- 对Java方法计数,如果是Native方法则计数器的值为Undefined
- 不会发生内存泄漏
Java虚拟机栈(Stack)
- Java方法执行的内存模型
- 包含多个栈帧(一个栈帧包括局部变量表、操作栈、动态链接、返回地址等,方法的调用即对于栈帧从虚拟机Stack中入栈到出栈的过程)
- 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
- 栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
本地方法栈
与虚拟机栈相似,主要作用于标注了native的方法。
元空间(MetaSpace)
用于存放已被加载的类信息、常量、静态变量。
面:谈谈元空间(MetaSpace)和永久代(PermGen)的区别?
- 均是方法区(JVM的一种规范)的实现
- JDK8后元空间替代了永久代
- 元空间使用本地内存,而永久代使用的是jvm内存,这解决了空间不足的问题。
面:MetaSpace相比PermGen的优势?
- 字符串常量池(JDK1.7开始移动到Java堆中)存在与永久代中,容易出现性能问题和内存溢出
- 类的方法的信息大小难以确定,给永久代的大小的指定带来了困难
- 永久代会为GC带来不必要的复杂性
- 方便HotSpot与其他JVM如Jrockit的集成(因为永久代是HotSpot独有的)
Java堆(Heap)
- 是对象实例的分配区域
- GC管理的主要区域
面:说说JVM三大性能调优参数-Xms、-Xmx、-Xss的含义?
java -Xms128m -Xmx128m -Xss256k -jar xxx.jar
- -Xss:规定了每个线程虚拟机栈(堆栈)的大小
- -Xms:堆的初始值
- -Xmx:堆能达到的最大值
一般将-Xms与-Xmx设置为同样的数值,避免堆扩容时发生的内存抖动,影响程序的稳定性。
内存分配策略
- 静态存储:编译时确定每个数据目标在运行时的存储空间需求
- 栈式存储:数据区需求在编译时未知,在运行时模块入口前确定
- 堆式存储:编译时或运行时模块入口都无法确定需求,需要动态分配
面:谈谈Java内存模型中堆和栈的区别与联系?
- 联系:引用对象、数组时,栈里定义变量来保存堆中目标的首地址
- 管理方式:栈自动释放,堆需要GC
- 空间大小:一般栈比堆小
- 碎片相关:栈产生的内存碎片远小于堆
- 分配方式:栈支持静态和动态分配,而堆仅支持动态分配
- 效率:栈的效率比堆高(栈只有入栈与出栈)
面:请解释下JDK6和JDK6+下intern()方法的区别?
- JDK6:当调用intern方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则将此字符串对象添加到字符串常量池中,并且返回该字符串对象的引用。
- JDK6+:当调用intern方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中该字符串的引用。否则,如果该字符串对象已经存在与Java堆中,则将堆中对此对象的引用添加到字符串常量池中,并且返回该引用;如果堆中不存在该对象,则在字符串常量池中创建该字符串并返回其引用。
实例,分别说出在JDK6和JDK6+下,下面程序的输出结果。
package com.yunche.jvm;
/**
* @author yunche
* @date 2019/03/20
*/
public class InternDifference {
public static void main(String[] args) {
String s = new String("a");
s.intern();
String s2 = "a";
System.out.println(s == s2);
String s3 = new String("a") + new String("a");
s3.intern();
String s4 = "aa";
System.out.println(s3 == s4);
}
}
JDK6:false,false。原因如下:
package com.yunche.jvm;
/**
* @author yunche
* @date 2019/03/20
*/
public class InternDifference {
public static void main(String[] args) {
//1.字符串常量池中创建“a”
//2.堆中创建一个对象“a”
String s = new String("a");
//3.尝试将对象“a”放入常量池中,失败,返回常量池中“a”的引用
s.intern();
//4.常量池中有“a”,返回其引用
String s2 = "a";
//5.比较堆中地址和常量池中的地址,故为false
System.out.println(s == s2);
//6.由于字符串常量池池中有“a”,故不再添加"a"到池中
//7.创建对象“aa”在堆中
String s3 = new String("a") + new String("a");
//8.尝试将“aa”放入到池中,成功,返回对其的引用
s3.intern();
//9.常量池中有"aa",返回对其的引用
String s4 = "aa";
//10.比较堆中地址和常量池中的地址,故为false
System.out.println(s3 == s4);
}
}
JDK6+:false,true。原因如下:
package com.yunche.jvm;
/**
* @author yunche
* @date 2019/03/20
*/
public class InternDifference {
public static void main(String[] args) {
//1.字符串常量池中创建“a”
//2.堆中创建一个对象“a”
String s = new String("a");
//3.尝试将对象“a”放入常量池中,失败,返回常量池中“a”的引用
s.intern();
//4.常量池中有“a”,返回其引用
String s2 = "a";
//5.比较堆中地址和常量池中的地址,故为false
System.out.println(s == s2);
//6.由于字符串常量池池中有“a”,故不再添加"a"到池中
//7.创建对象“aa”在堆中
String s3 = new String("a") + new String("a");
//8.尝试将“aa”放入到池中,成功,意味着将堆中的"aa"的引用放入池中
s3.intern();
//9.常量池中有"aa",返回对其的引用本质就是上一步堆中"aa"的引用
String s4 = "aa";
//10.比较堆中同一个地址,故为true
System.out.println(s3 == s4);
}
}
垃圾回收(GC)
从前面我们已经知道GC主要是回收Java堆中的对象,即此对象已经没有了价值,就是变成了“垃圾”,那么对象被判定为垃圾的标准是什么呢?——没有被其他对象引用。
判定对象是否是垃圾的算法
-
引用计数算法:主要是判断对象的引用数量。
- 通过判断对象的引用数量来决定对象是否可以被回收
- 每个对象实例都有一个引用计数器,被引用则+1,完成引用则-1(局部变量的生命周期结束)
- 任何引用计数为0的对象实例都可以被当作垃圾收集
优点:执行效率高,程序执行受影响较小
缺点:无法检测出循环引用的情况,导致无法回收垃圾,从而引发内存泄漏
-
可达性分析算法:通过判断对象的引用链(从GC Root开始)是否可达来决定对象是否可以被回收。
可作为GC Root的对象:
- 虚拟机栈中引用的对象(栈帧中的本地变量表)
- 方法区中的常量引用的对象
- 方法区中的类静态属性引用的对象
- 本地方法栈中JNI(Native方法)的引用对象
- 活跃线程的引用对象
面:谈谈你了解的垃圾回收算法?
- 标记-清除算法(Mark and Sweep):
- 标记:从根集合进行扫描,对存活的对象进行标记
- 清除:对堆内存从头到尾进行线性遍历,回收不可达的对象内存

缺点:产生大量的碎片,使得无法给较大的对象分配内存。
-
复制算法(Copying)
- 分为对象面和空闲面
- 对象在对象面上创建
- 存活的对象被从对象面复制到空闲面
- 将对象面所有对象内存清除
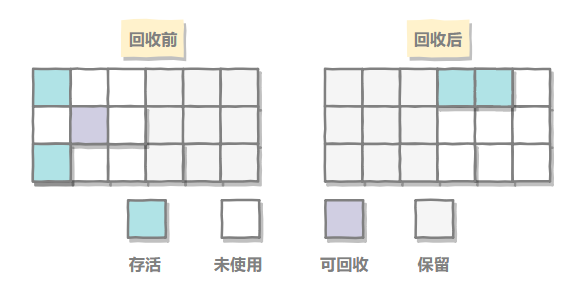
优点是:
- 解决了碎片化问题
- 顺序分配内存,简单高效
不足:复制耗费时间,且要浪费一半的内存用作空闲面。
适用场景:适用于对象存活率低的场景(年轻代)
-
标记-整理算法(Compacting)
- 标记:从根集合进行扫描,对存活的对象进行标记
- 清除:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。
优点:避免了内存的不连续行,防止出现大量内存碎片,不用浪费一半的内存(对比于复制算法)。
适用场景:适用于存活率高的场景(老年代)

-
分代收集算法(Generational Collector)
- 垃圾回收算法的组合拳
- 按照对象生命周期的不同划分区域以采用不同的垃圾回收算法
- 目的:用于提高JVM垃圾回收的效率
JDK1.8及以后堆中的划分如下:


GC的分类
- Minor GC:发生在年轻代(对象出生的地方,该区域的对象几乎都是“朝生夕灭”)中的GC动作,采用的收集算法是复制(需要复制的对象很少)。
- Full GC:主要对老年代(该区域的对象是“幸存”下来的对象,一般不会再轻易“死亡”)的回收,但同时包含了对年轻代的回收(即包含了Minor GC)。采用的收集算法是标记-清除和标记-整理。相比Minor GC慢,但执行频率低。
对象如何晋升到老年代
- 经历一定Minor GC次数后依然存活的对象
- Survivor区中存放不下的对象
- 新生成的大对象(-XX:+PretenuerSizeThreshold)
常用的调优参数
- -XX:SurvivorRatio:Eden和Survivor的比值,默认8:1
- -XX:NewRatio:老年代和年轻代内存的大小比例
- -XX:MAXTenuringThreshold:对象从年轻代晋升到老年代进过GC次数的最大阈值
触发Full GC的条件
- 老年代空间不足
- 永久代空间不足(JDK1.8之前)
- CMS GC时出现promotion failed,concurrent mode failure
- Minor GC晋升到老年代的平均大小大于老年代的剩余空间
- 调用System.gc()(仅是通知,不保证何时执行)
- 使用RMI来进行PRC或管理的JDK应用,每小时执行1此Full GC
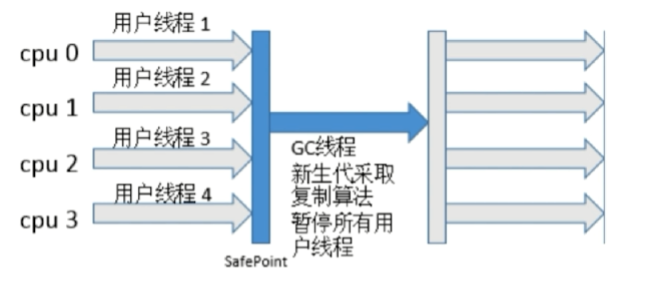
Stop-the-World
- JVM由于要执行GC而停止应用程序的执行
- 任何一种GC算法中都会发生
- 多数GC优化通过减少Stop-the-world发生的时间来提高程序性能
Safepoint
- 分析过程中对象引用关系不会发生变化的点
- 产生Safepoint的地方:方法调用、循环跳转、异常跳转等
- 安全点数量要适中(太少会让GC等待太长的时间,太多增加了程序运行的负荷)
JVM的运行模式
- Server:重量级级启动,速度较慢,优化更多
- Client:轻量级启动,速度快
常见的垃圾收集器
连线表示可以搭配使用。
年轻代常见的垃圾收集器
- Serial收集器(-XX:+UseSerialGC,复制算法)
- 单线程收集,进行垃圾收集时,必须暂停所有工作线程
- 简单高效,Client模式下默认的年轻收集器
-
ParNew收集器(-XX:+UseParNewGC,复制算法)
-
多线程收集,其余的行文、特点和Serial收集器一样
-
单核执行效率不如Serial,在多核下执行才有优势
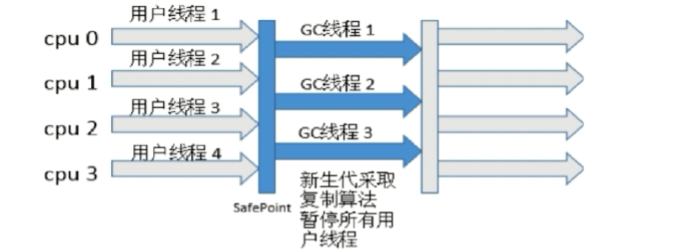
-
-
Parrallel Scanvenge收集器(-xx:+UseParallelGC,复制算法)
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)
-
比起关注用户线程停顿时间,更关注系统的吞吐量(适合后台,不用用户交互的程序)
-
在多核下执行才有优势,Server模式下默认的年轻代收集器

-
老年代常见的垃圾收集器
-
Serial Old收集器(-XX:+UseSerialOldGC,标记-整理算法)
-
单线程收集,进行垃圾收集时,必须暂停所有工作线程
-
简单高效,Client模式下默认的老年代收集器
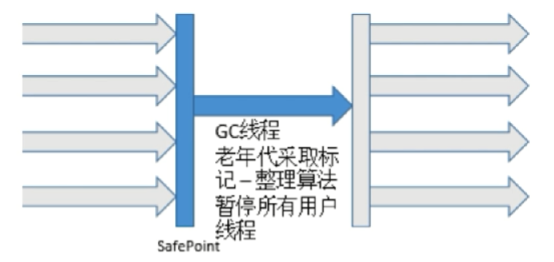
-
-
Parallel Old收集器(-XX:+UseParallelOldGC,标记-整理算法)
-
多线程,吞吐量优先

-
-
CMS收集器(-XX:+UseConcMarkSweepGC,标记-清除算法)
- 初始标记:stop-the-world
- 并发标记:并发追溯标记,程序不会停顿
- 并发预清理:查找执行并发标记阶段从年轻代晋升到老年代的对象
- 重新标记:暂停虚拟机,扫描CMS堆中的剩余对象
- 并发清理:清理垃圾对象,程序不会停顿
- 并发重置:重置CMS收集器的数据结构
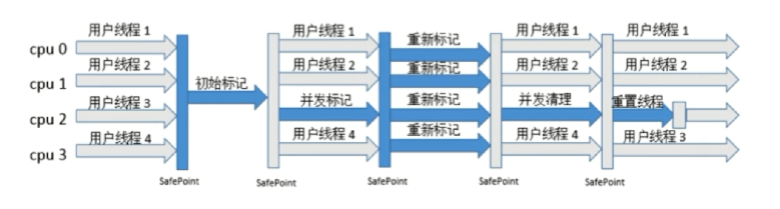
G1收集器(-XX:+UseG1GC,复制+标记-整理算法)
- 并行和并发
- 分代收集
- 空间整合
- 可预测的停顿
- 将整个Java堆内存划分成多个大小想的的Region
- 年轻代和老年代不再物理隔离

面:Object的finalize()方法的作用是否与C++的析构函数的作用相同?
- 与C++的析构函数不同,析构函数的调用时机是确定的,而它是不确定的
- 将未被应用的现象放置于F-Queue队列
- 方法执行随时可能会被终止
- 给予对象最后一次重生的机会
实例:
package com.yunche.gc;
/**
* 测试finalize方法
* @author yunche
* @date 2019/03/21
*/
public class Finalization {
public static Finalization finalization;
@Override
protected void finalize() {
System.out.println("Finalized");
finalization = this;
}
public static void main(String[] args) {
Finalization f = new Finalization();
System.out.println("First print: " + f);
f = null;
System.gc();
try { //休息一段时间,确保GC线程执行完成
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Second print: " + f);
System.out.println(f.finalization);
}
}
输出:
First print: com.yunche.gc.Finalization@4554617c
Finalized
Second print: null
com.yunche.gc.Finalization@4554617c
面:Java中的强引用,软引用,弱引用,虚引用的作用?
-
强引用(Strong Reference)
- 最普遍的引用:Object ob = new Object()
- 抛出OutOfMemoryError终止程序也不会回收具有强引用的对象
- 通过将对象设置为null来弱化引用,使其被回收
-
软引用(Soft Reference)
-
对象处在有用当非必须的状态
-
只有当内存空间不足时,GC才会回收该引用的对象的内存
-
可以用来实现高速缓存
String str = new String("abc"); //强引用
SoftReference
softRef = new SoftReference (str); //软引用
-
-
弱引用(Weak Reference)
-
非必须的对象,比软引用更弱一些,也可以用作缓存
-
只要GC就会被回收
-
被回收的概率也不大,因为GC线程优先级比较低
-
适用于引用偶尔被使用且不影响垃圾收集的对象
String str = new String("abc");
WeakReference
weakRef = new WeakReference (str);
-
-
虚引用(PhantomReference)
-
不会决定对象的生命周期
-
任何时候都可能被GC
-
跟踪对象被GC的活动,起哨兵作用
-
必须和引用队列ReferenceQueue联合使用
String str = new String("abc");
ReferenceQueue queue = new ReferenceQueue();
PhantomReference ref = new PhantomReference(str, queue);
-